Uncertainty Estimation and Quantification for LLMs: A Simple Supervised Approach
Abstract: In this paper, we study the problem of uncertainty estimation and calibration for LLMs. We begin by formulating the uncertainty estimation problem, a relevant yet underexplored area in existing literature. We then propose a supervised approach that leverages labeled datasets to estimate the uncertainty in LLMs' responses. Based on the formulation, we illustrate the difference between the uncertainty estimation for LLMs and that for standard ML models and explain why the hidden neurons of the LLMs may contain uncertainty information. Our designed approach demonstrates the benefits of utilizing hidden activations to enhance uncertainty estimation across various tasks and shows robust transferability in out-of-distribution settings. We distinguish the uncertainty estimation task from the uncertainty calibration task and show that better uncertainty estimation leads to better calibration performance. Furthermore, our method is easy to implement and adaptable to different levels of model accessibility including black box, grey box, and white box.
- A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information fusion 76 243–297.
- Distinguishing the knowable from the unknowable with language models. arXiv preprint arXiv:2402.03563 .
- The internal state of an llm knows when its lying. arXiv preprint arXiv:2304.13734 .
- Findings of the 2014 workshop on statistical machine translation. Proceedings of the ninth workshop on statistical machine translation. 12–58.
- Breiman, Leo. 2001. Random forests. Machine learning 45 5–32.
- Language models are few-shot learners. Advances in neural information processing systems 33 1877–1901.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712 .
- Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827 .
- Do androids know they’re only dreaming of electric sheep? arXiv preprint arXiv:2312.17249 .
- Inside: Llms’ internal states retain the power of hallucination detection. arXiv preprint arXiv:2402.03744 .
- Calibration of pre-trained transformers. arXiv preprint arXiv:2003.07892 .
- Do llms know about hallucination? an empirical investigation of llm’s hidden states. arXiv preprint arXiv:2402.09733 .
- Shifting attention to relevance: Towards the uncertainty estimation of large language models. arXiv preprint arXiv:2307.01379 .
- Benchmarking bayesian deep learning with diabetic retinopathy diagnosis. Preprint at https://arxiv. org/abs/1912.10481 .
- Unsupervised quality estimation for neural machine translation. Transactions of the Association for Computational Linguistics 8 539–555.
- A survey of uncertainty in deep neural networks. Artificial Intelligence Review 56(Suppl 1) 1513–1589.
- Gemma doi:10.34740/KAGGLE/M/3301. URL https://www.kaggle.com/m/3301.
- On calibration of modern neural networks. International conference on machine learning. PMLR, 1321–1330.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 .
- Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551 .
- Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221 .
- Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. arXiv preprint arXiv:2302.09664 .
- Conformal prediction with large language models for multi-choice question answering. arXiv preprint arXiv:2305.18404 .
- Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems 36.
- Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04). 605–612.
- ORANGE: a method for evaluating automatic evaluation metrics for machine translation. COLING 2004: Proceedings of the 20th International Conference on Computational Linguistics. COLING, Geneva, Switzerland, 501–507. URL https://www.aclweb.org/anthology/C04-1072.
- Generating with confidence: Uncertainty quantification for black-box large language models. arXiv preprint arXiv:2305.19187 .
- Towards collaborative neural-symbolic graph semantic parsing via uncertainty. Findings of the Association for Computational Linguistics: ACL 2022 .
- Cognitive dissonance: Why do language model outputs disagree with internal representations of truthfulness? arXiv preprint arXiv:2312.03729 .
- Uncertainty estimation in autoregressive structured prediction. International Conference on Learning Representations. URL https://openreview.net/forum?id=jN5y-zb5Q7m.
- Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv preprint arXiv:2303.08896 .
- Reducing conversational agents’ overconfidence through linguistic calibration. Transactions of the Association for Computational Linguistics 10 857–872.
- Language models with conformal factuality guarantees. arXiv preprint arXiv:2402.10978 .
- Training language models to follow instructions with human feedback. Advances in neural information processing systems 35 27730–27744.
- Bleu: a method for automatic evaluation of machine translation. 311–318.
- Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in large margin classifiers 10(3) 61–74.
- Softmax probabilities (mostly) predict large language model correctness on multiple-choice q&a. arXiv preprint arXiv:2402.13213 .
- Conformal language modeling. arXiv preprint arXiv:2306.10193 .
- Language models are unsupervised multitask learners. OpenAI blog 1(8) 9.
- A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922 .
- Re-examining calibration: The case of question answering. arXiv preprint arXiv:2205.12507 .
- The curious case of hallucinatory (un) answerability: Finding truths in the hidden states of over-confident large language models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 3607–3625.
- Unsupervised real-time hallucination detection based on the internal states of large language models. arXiv preprint arXiv:2403.06448 .
- Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. arXiv preprint arXiv:2305.14975 .
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 .
- Reducing llm hallucinations using epistemic neural networks. arXiv preprint arXiv:2312.15576 .
- Hallucination is inevitable: An innate limitation of large language models. arXiv preprint arXiv:2401.11817 .
- Can explanations be useful for calibrating black box models? arXiv preprint arXiv:2110.07586 .
- Transforming classifier scores into accurate multiclass probability estimates. Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining. 694–699.
- A study on the calibration of in-context learning. arXiv preprint arXiv:2312.04021 .
- Knowing more about questions can help: Improving calibration in question answering. arXiv preprint arXiv:2106.01494 .
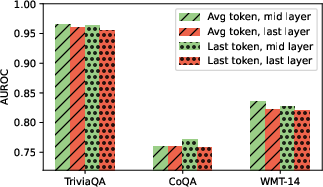
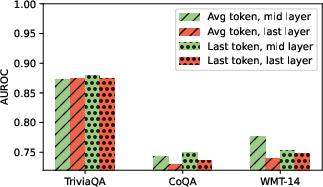
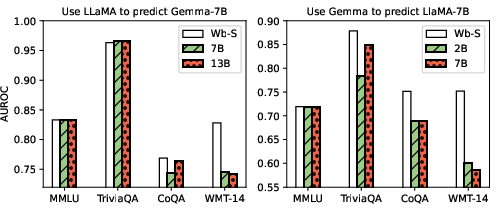
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

