ID-Aligner: Enhancing Identity-Preserving Text-to-Image Generation with Reward Feedback Learning
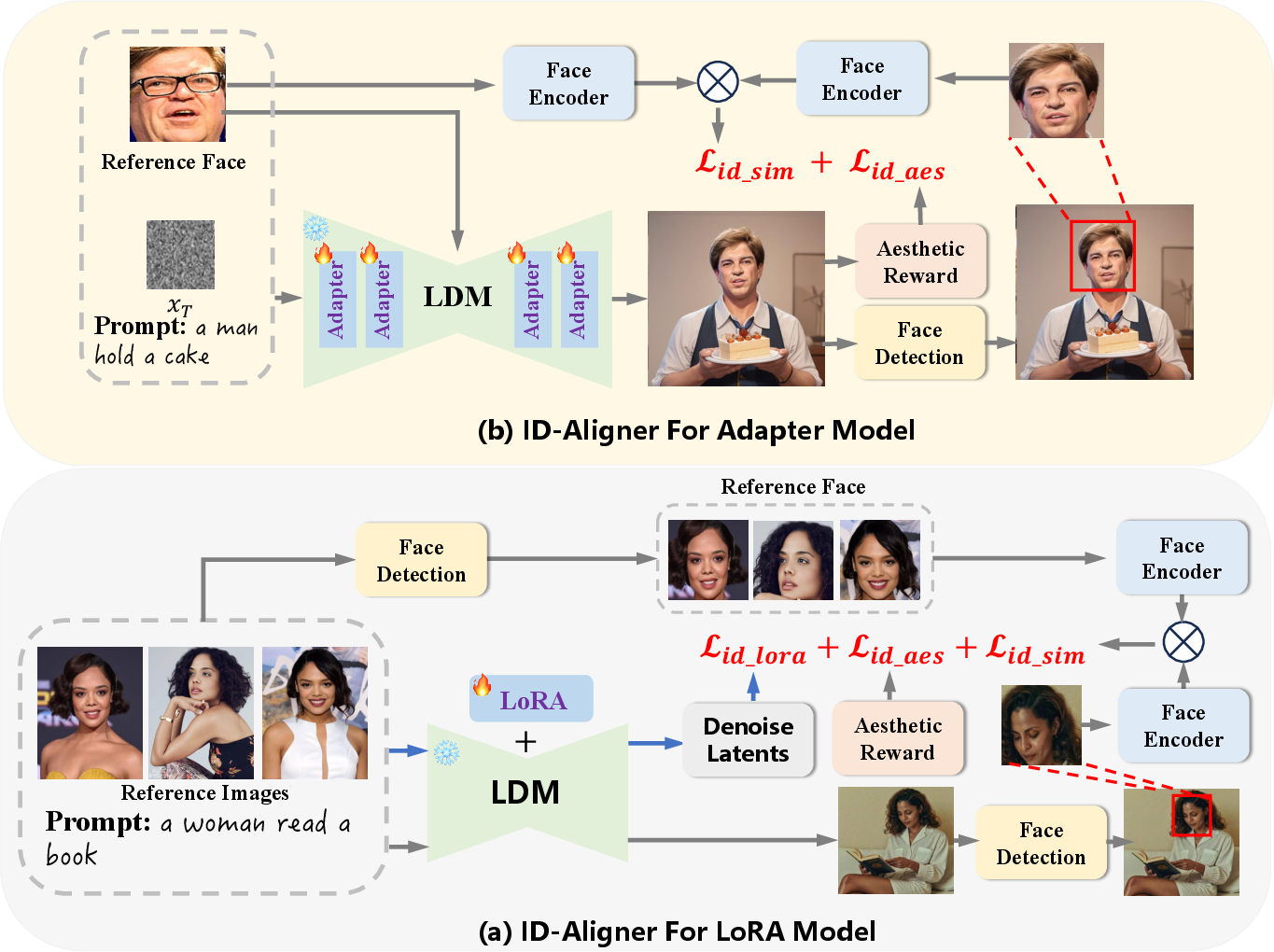
Abstract: The rapid development of diffusion models has triggered diverse applications. Identity-preserving text-to-image generation (ID-T2I) particularly has received significant attention due to its wide range of application scenarios like AI portrait and advertising. While existing ID-T2I methods have demonstrated impressive results, several key challenges remain: (1) It is hard to maintain the identity characteristics of reference portraits accurately, (2) The generated images lack aesthetic appeal especially while enforcing identity retention, and (3) There is a limitation that cannot be compatible with LoRA-based and Adapter-based methods simultaneously. To address these issues, we present \textbf{ID-Aligner}, a general feedback learning framework to enhance ID-T2I performance. To resolve identity features lost, we introduce identity consistency reward fine-tuning to utilize the feedback from face detection and recognition models to improve generated identity preservation. Furthermore, we propose identity aesthetic reward fine-tuning leveraging rewards from human-annotated preference data and automatically constructed feedback on character structure generation to provide aesthetic tuning signals. Thanks to its universal feedback fine-tuning framework, our method can be readily applied to both LoRA and Adapter models, achieving consistent performance gains. Extensive experiments on SD1.5 and SDXL diffusion models validate the effectiveness of our approach. \textbf{Project Page: \url{https://idaligner.github.io/}}
- Training Diffusion Models with Reinforcement Learning. arXiv:2305.13301 [cs.LG]
- Instructpix2pix: Learning to follow image editing instructions. arXiv preprint arXiv:2211.09800 (2022).
- PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models. ([n. d.]).
- Taming Transformers for High-Resolution Image Synthesis. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr46437.2021.01268
- Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022).
- Denoising Diffusion Probabilistic Models. arXiv:2006.11239 [cs.LG]
- LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL]
- IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models. (Aug 2023).
- Composer: Creative and Controllable Image Synthesis with Composable Conditions. (Feb 2023).
- Diederik P Kingma and Max Welling. 2022. Auto-Encoding Variational Bayes. arXiv:1312.6114 [stat.ML]
- PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding. (Dec 2023).
- Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning. (Jul 2023).
- SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. arXiv:2108.01073 [cs.CV]
- T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453 (2023).
- GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv:2112.10741 [cs.CV]
- OpenAI. 2023. Introducing chatgpt. arXiv:2303.08774 [cs.CL]
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Training language models to follow instructions with human feedback. arXiv:2203.02155 [cs.CL]
- JourneyDB: A Benchmark for Generative Image Understanding. arXiv:2307.00716 [cs.CV]
- SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. ([n. d.]).
- UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild. arXiv:2305.11147 [cs.CV]
- Learning Transferable Visual Models From Natural Language Supervision. Cornell University - arXiv,Cornell University - arXiv (Feb 2021).
- Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv:2204.06125 [cs.CV]
- High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752 [cs.CV]
- DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation.
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv:2205.11487 [cs.CV]
- FaceNet: A unified embedding for face recognition and clustering. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2015.7298682
- LAION-5B: An open large-scale dataset for training next generation image-text models. ([n. d.]).
- InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning. (Apr 2023).
- Denoising Diffusion Implicit Models. arXiv:2010.02502 [cs.LG]
- Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation. arXiv preprint arXiv:2211.12572 (2022).
- InstantID: Zero-shot Identity-Preserving Generation in Seconds. arXiv:2401.07519 [cs.CV]
- ELITE: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation. (Feb 2023).
- Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis. arXiv:2306.09341 [cs.CV]
- Human Preference Score: Better Aligning Text-to-Image Models with Human Preference. arXiv:2303.14420 [cs.CV]
- FastComposer: Tuning-Free Multi-Subject Image Generation with Localized Attention. ([n. d.]).
- ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation. arXiv:2304.05977 [cs.CV]
- FaceStudio: Put Your Face Everywhere in Seconds. (Dec 2023).
- IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models. arXiv:2308.06721 [cs.CV]
- UniFL: Improve Stable Diffusion via Unified Feedback Learning. ([n. d.]).
- Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks. IEEE Signal Processing Letters (Oct 2016), 1499–1503. https://doi.org/10.1109/lsp.2016.2603342
- Adding Conditional Control to Text-to-Image Diffusion Models. arXiv:2302.05543 [cs.CV]



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

