- The paper introduces a paradigm shift where generative models produce document identifiers and responses rather than relying solely on traditional matching.
- It details advanced sequence-to-sequence training methods, dynamic identifier design, and incremental learning strategies to enhance retrieval effectiveness.
- The study emphasizes strategies for ensuring factual accuracy through model scaling, external knowledge augmentation, and embedding citations in responses.
Introduction
Generative information retrieval (GenIR) has emerged as a paradigm shift in how information retrieval systems operate, transitioning from traditional document matching and ranking to more sophisticated generative models. These models leverage powerful pre-trained language capabilities to perform two primary tasks: generative document retrieval and response generation. This paper provides a comprehensive review of the advancements, challenges, and future directions of GenIR, positioning it within the broader context of information retrieval systems.
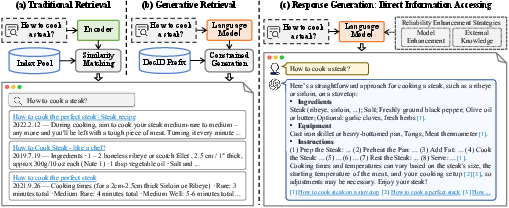
Figure 1: Exploring IR Evolution: From Traditional to Generative Methods.
Generative Document Retrieval
Generative document retrieval leverages LLMs to directly generate document identifiers (DocIDs), bypassing the need for traditional indexing. This section explores various aspects of the document retrieval process facilitated by generative models.
Model Training and Structure
Training generative retrieval models involves mapping queries to relevant DocIDs through sequence-to-sequence (seq2seq) training, supported by data augmentation techniques such as pseudo query generation and multi-task distillation strategies. Examples like the DSI model and its successors demonstrate adaptations using innovative document sampling and query generation methods to increase DocID memorization and improve ranking capabilities.
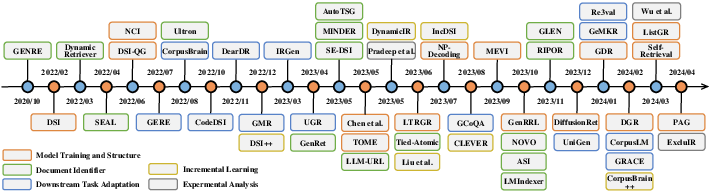
Figure 2: Timeline of research in generative retrieval: focus on model training and structure, document identifier design, incremental learning and downstream task adaptation.
Document Identifier Design
DocIDs can be both static and dynamic, numeric or text-based. While text-based identifiers utilize pre-trained LLMs' linguistic adeptness, numeric identifiers often achieve efficiency through methods like Product Quantization and learnable identifiers. The integration of these identifiers into GR models remains central to their success for accurate and efficient document representation.
Incremental Learning
Incremental learning addresses the challenge of adapting to dynamic corpora. Solutions range from dynamic memory banks to constrained optimization techniques and incremental pre-training strategies, which ensure the model maintains performance while incorporating new information, crucial for maintaining relevance in evolving information environments.
Reliable Response Generation
Response generation in GenIR models focuses on producing user-centric, reliable responses, effectively changing the paradigm from document ranking to direct answer generation.
Model Internal Knowledge Enhancement
Improving internal knowledge retention within models involves scaling models through Transformer architecture and mixtures of experts (MoE) to enhance generation capabilities. Training methodologies such as factual calibration and adversarial training improve factual correctness and response reliability, fostering trust in generated content.
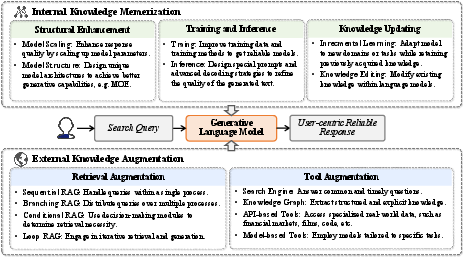
Figure 3: An illustration of strategies for enhancing LLMs to generate user-centric and reliable responses.
External Knowledge Augmentation
Enhancements through retrieval augmentation and tool augmentation remain crucial. Retrieval-augmented generation (RAG) enriches models with externally sourced content to generate factually accurate and timely responses. Tools like search engines and APIs provide real-time data, supplementing model knowledge with dynamic content that ensures relevancy and accuracy in responses.
Generating Responses with Citations
Citations improve the verifiability of generated content by embedding source references within responses. Techniques like constrained decoding and verification layers ensure responses are supported by reliable sources, promoting trustworthiness in generated outputs.
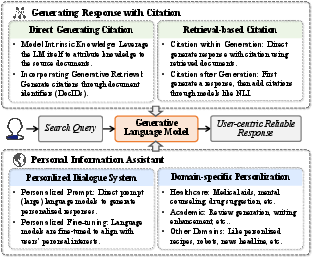
Figure 4: Generating response with citation and personal information assistant are also crucial approaches for building a reliable and user-centric GenIR system.
Conclusion
Generative information retrieval redefines how information systems interact with users, emphasizing the need for models that generate rather than merely retrieve information. The survey highlights the shift in focus from matching to generation, showcasing how advancements in model training, incremental learning, and knowledge enhancement significantly contribute to more robust and reliable information systems. Future developments in AI will likely build on these foundations, further integrating retrieval and generative capabilities into unified, adaptable systems capable of addressing a wide array of information challenges.

