CoST: Contrastive Quantization based Semantic Tokenization for Generative Recommendation
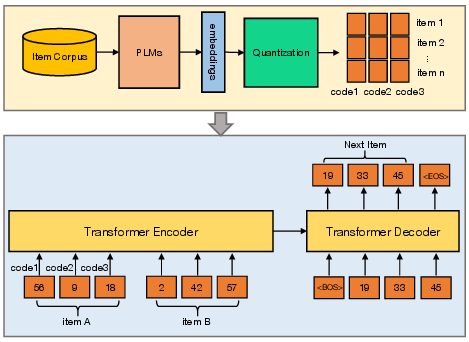
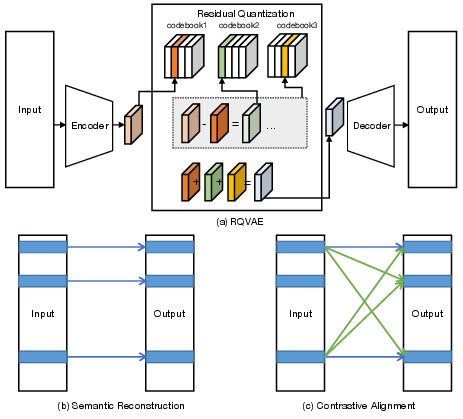
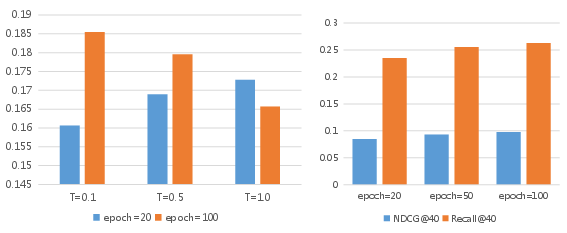
Abstract: Embedding-based retrieval serves as a dominant approach to candidate item matching for industrial recommender systems. With the success of generative AI, generative retrieval has recently emerged as a new retrieval paradigm for recommendation, which casts item retrieval as a generation problem. Its model consists of two stages: semantic tokenization and autoregressive generation. The first stage involves item tokenization that constructs discrete semantic tokens to index items, while the second stage autoregressively generates semantic tokens of candidate items. Therefore, semantic tokenization serves as a crucial preliminary step for training generative recommendation models. Existing research usually employs a vector quantizier with reconstruction loss (e.g., RQ-VAE) to obtain semantic tokens of items, but this method fails to capture the essential neighborhood relationships that are vital for effective item modeling in recommender systems. In this paper, we propose a contrastive quantization-based semantic tokenization approach, named CoST, which harnesses both item relationships and semantic information to learn semantic tokens. Our experimental results highlight the significant impact of semantic tokenization on generative recommendation performance, with CoST achieving up to a 43% improvement in Recall@5 and 44% improvement in NDCG@5 on the MIND dataset over previous baselines.
- M6-rec: Generative pretrained language models are open-ended recommender systems. arXiv preprint arXiv:2205.08084 (2022).
- Autoregressive entity retrieval. arXiv preprint arXiv:2010.00904 (2020).
- Transformers4rec: Bridging the gap between nlp and sequential/session-based recommendation. In Proceedings of the 15th ACM Conference on Recommender Systems. 143–153.
- Recommender Forest for Efficient Retrieval. Advances in Neural Information Processing Systems 35 (2022), 38912–38924.
- Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In Proceedings of the 16th ACM Conference on Recommender Systems. 299–315.
- Learning Vector-Quantized Item Representation for Transferable Sequential Recommenders. In TheWebConf.
- How to index item ids for recommendation foundation models. In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. 195–204.
- Product Quantization for Nearest Neighbor Search. IEEE Transactions on Pattern Analysis and Machine Intelligence 33, 1 (2011), 117–128. https://doi.org/10.1109/TPAMI.2010.57
- Autoregressive image generation using residual quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11523–11532.
- Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. arXiv preprint arXiv:2108.08877 (2021).
- Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018).
- Recommender systems with generative retrieval. Advances in Neural Information Processing Systems 36 (2024).
- Better Generalization with Semantic IDs: A case study in Ranking for Recommendations. arXiv preprint arXiv:2306.08121 (2023).
- Contrastive distillation on intermediate representations for language model compression. arXiv preprint arXiv:2009.14167 (2020).
- Sequence to sequence learning with neural networks. Advances in neural information processing systems 27 (2014).
- Transformer memory as a differentiable search index. Advances in Neural Information Processing Systems 35 (2022), 21831–21843.
- Neural discrete representation learning. Advances in neural information processing systems 30 (2017).
- Attention is all you need. Advances in neural information processing systems 30 (2017).
- A neural corpus indexer for document retrieval. Advances in Neural Information Processing Systems 35 (2022), 25600–25614.
- Mind: A large-scale dataset for news recommendation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 3597–3606.
- Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing 30 (2021), 495–507.
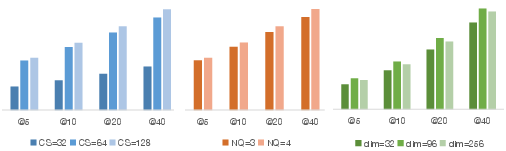
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.