- The paper introduces a retrieval augmented generation framework that effectively reduces hallucinations by grounding responses in Adobe-specific data.
- It employs contrastive learning with Adobe click and interaction data to train a retriever model that significantly improves relevance scoring and contextual retrieval.
- Experimental results show that fine-tuning and product disambiguation techniques lead to superior domain-specific QA performance compared to general models.
Retrieval Augmented Generation for Domain-specific Question Answering
Introduction
The paper presents a framework for domain-specific question answering, leveraging retrieval augmented generation techniques, specifically tailored for Adobe products. Traditional QA systems often fail to adapt to specific domain needs, such as understanding proprietary terminologies or dynamically updated content. This research proposes a fine-tuned retrieval system that significantly mitigates hallucinations in LLM responses by contextual grounding with up-to-date retrieved content, which is crucial for addressing the unique challenges posed by Adobe product inquiries.
Framework Overview
The proposed system comprises multiple components: a trained retriever model utilizing Adobe's click data for improved relevance scoring, a diverse retrieval index encompassing both primary and derivative sources, and an LLM fine-tuned to optimize contextual response generation.
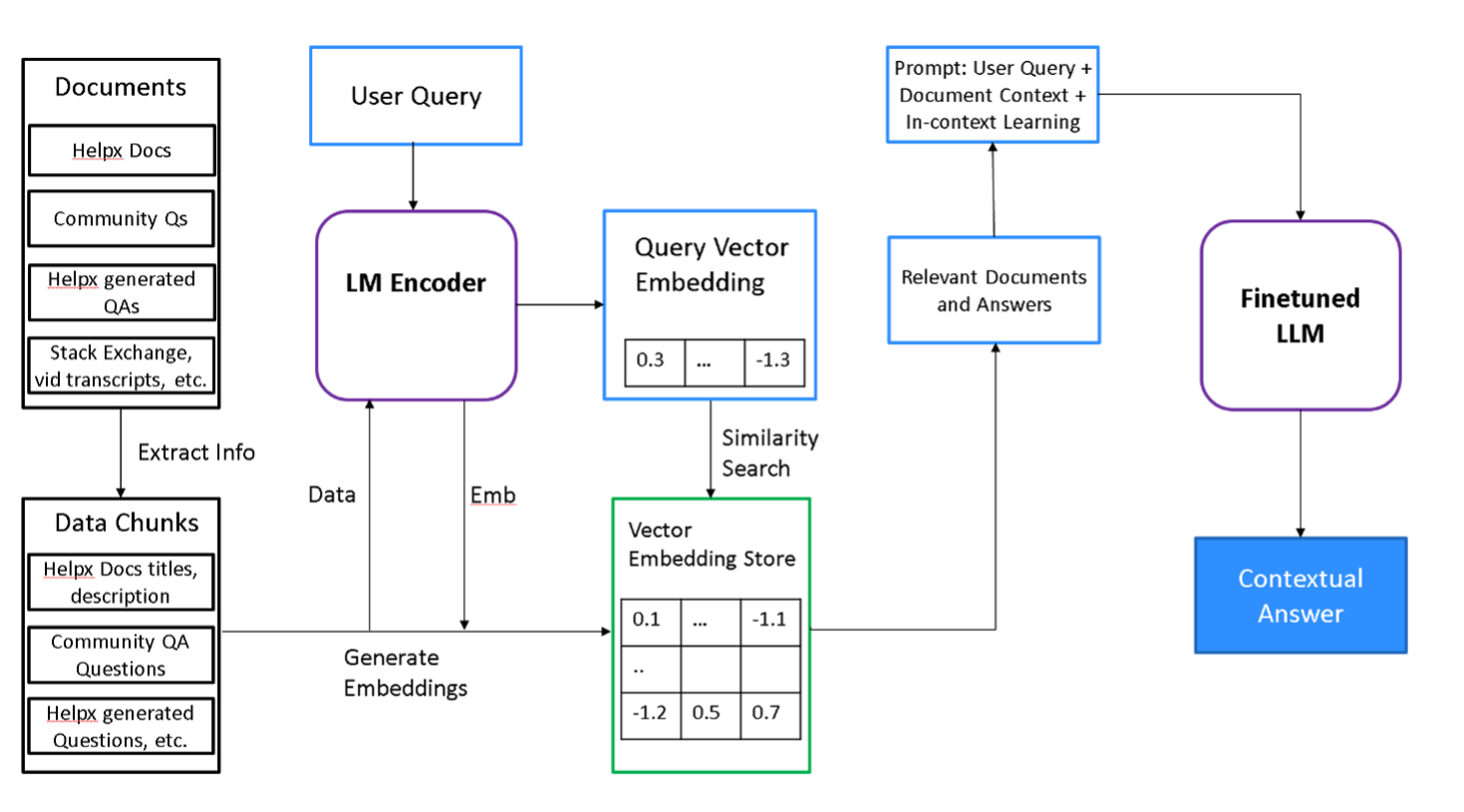
Figure 1: An overview of our proposed framework.
The system's architecture ensures users query Adobe's community database and Helpx documentation for the most accurate answers. By incorporating retrieval-aware finetuning strategies, the LLM leverages enhanced domain understanding and improved generative responses.
Retriever Training and Evaluation
The retriever model is trained using contrastive learning with Adobe-specific datasets derived from user interactions with Helpx articles and community forums. This methodology allows the model to align document titles and descriptions closely with user queries, enhancing retrieval relevance.
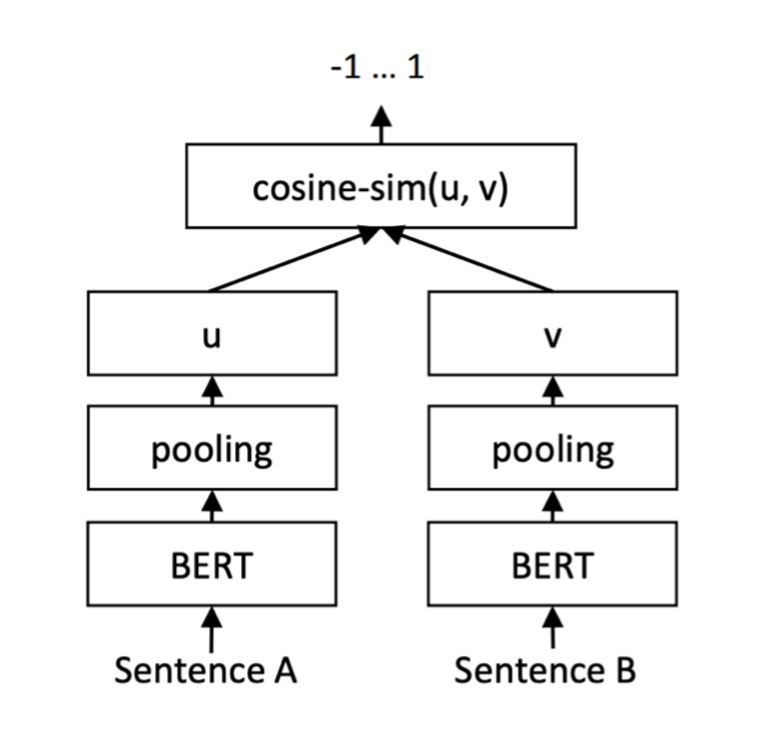
Figure 2: The training processing for the retriever.
Evaluation metrics such as nDCG were used to assess the retriever's performance, showcasing superior results over existing models like BGE and DiffCSE, with improvements noted in domain understanding and sentence comprehension capabilities.
Retrieval Index Creation and Database
The retrieval database integrates Helpx articles, community questions, and generated QA pairs from AdobeCare video transcripts. These sources ensure robust retrieval capabilities, empowering the system to provide up-to-date and accurate information.
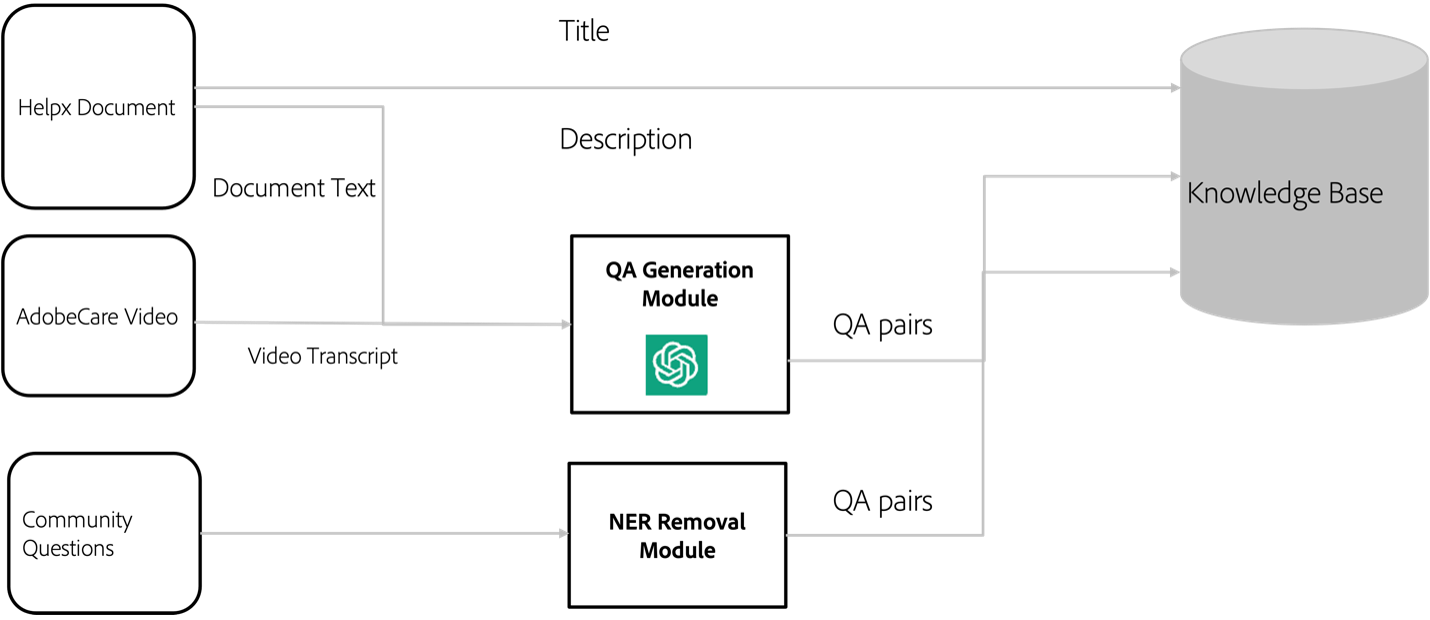
Figure 3: An overall architecture for indexing.
Named entity removal strategies are employed to preserve privacy, and a QA generation module contributes to enriching the dataset with detailed question-answer examples.
Query Augmentation via Product Identification
Product disambiguation is a key component to resolve ambiguities in user queries. By mapping queries to specific Adobe products, the retriever's accuracy in document relevance greatly improves, as demonstrated in comparative examples. This system's capability to discern product-specific information ensures tailored responses to common user questions.
Experiments and Results
The experiments conducted on the system illustrated notable enhancements in the retrieval and generation aspects when compared to other available models. The significant improvements are attributed to the retriever's training with domain-specific relevancies and LLM's finetuning with comprehensive Adobe datasets.
For quantitative evaluation, the integration with GPT-4 provided metrics showcasing higher relevance scores. Qualitative assessments further highlighted the system's ability to produce accurate, detailed responses compared to OpenAI's ChatGPT, especially in product-specific queries.
Conclusion
This study successfully implements a retrieval augmented generation framework, enhancing domain-specific QA systems tailored for Adobe products. The integration of finely tuned retrieval mechanisms and product disambiguation techniques ensures precise, grounded responses, minimizing hallucination risks associated with general LLM models. The methodologies presented offer compelling insights into developing advanced QA systems for specialized domains, suggesting further research into adaptive retrieval techniques to augment domain-specific knowledge bases.

