From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function
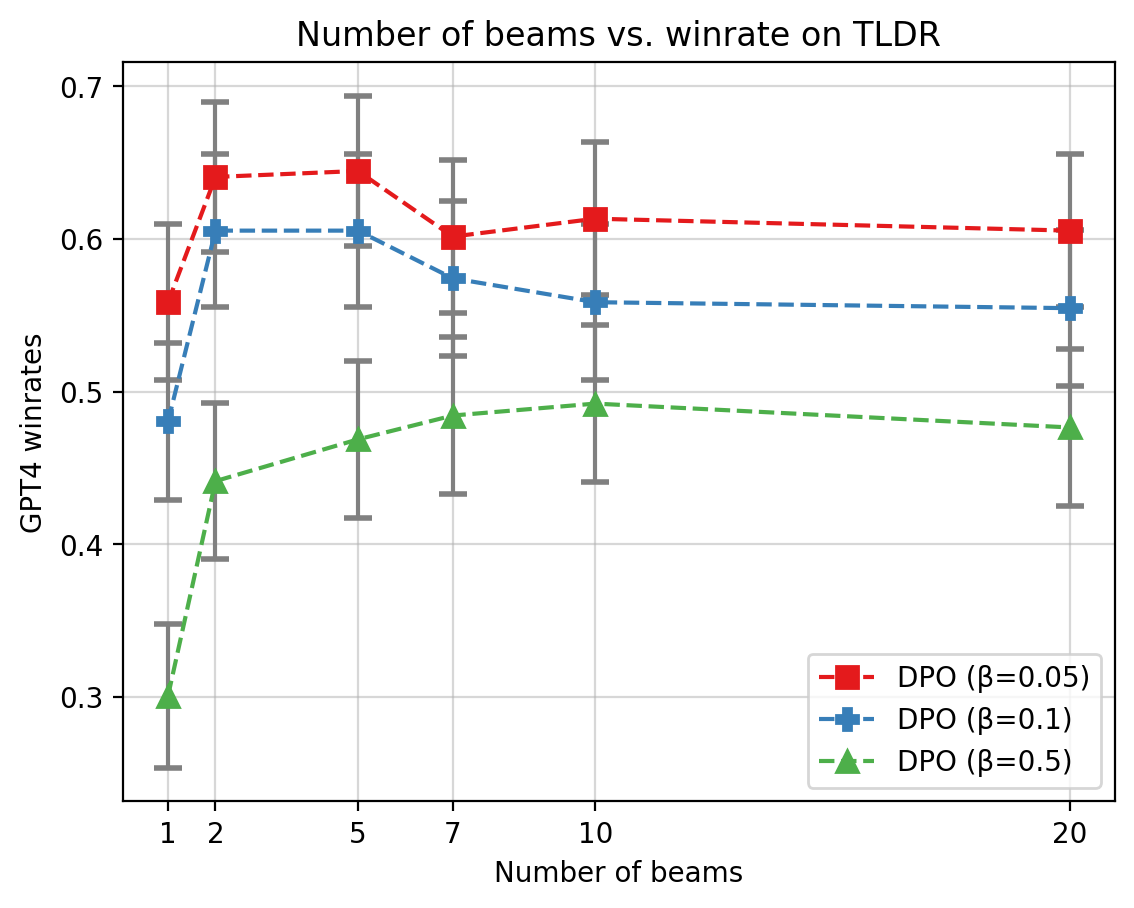
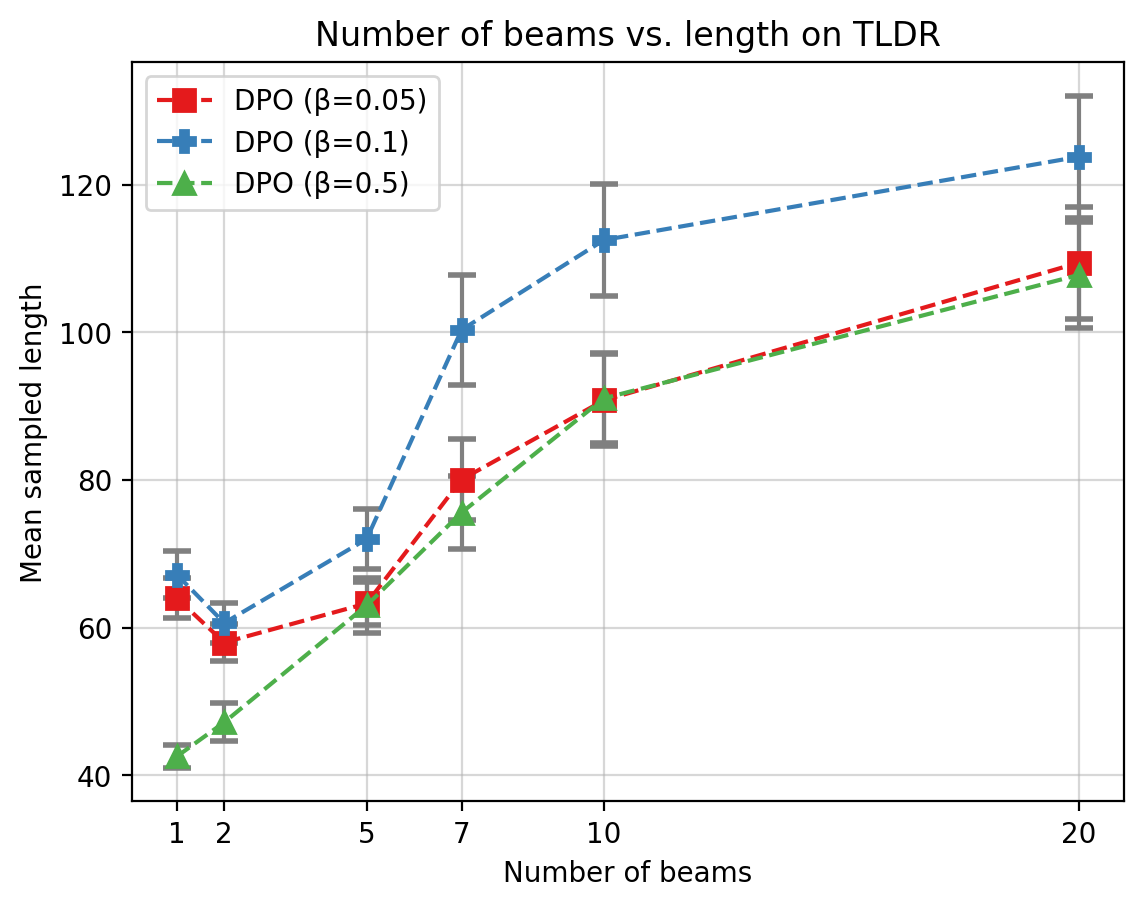
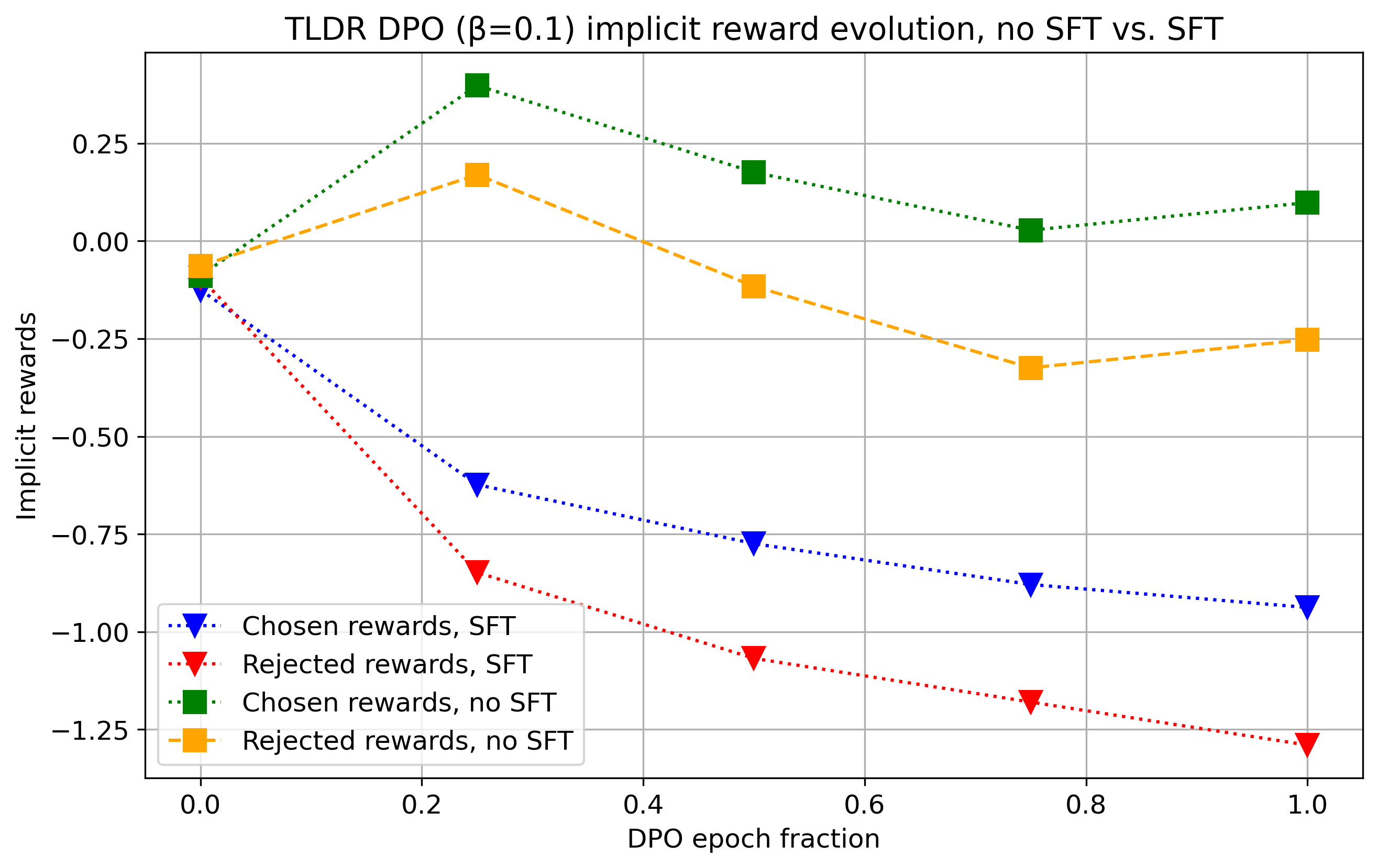
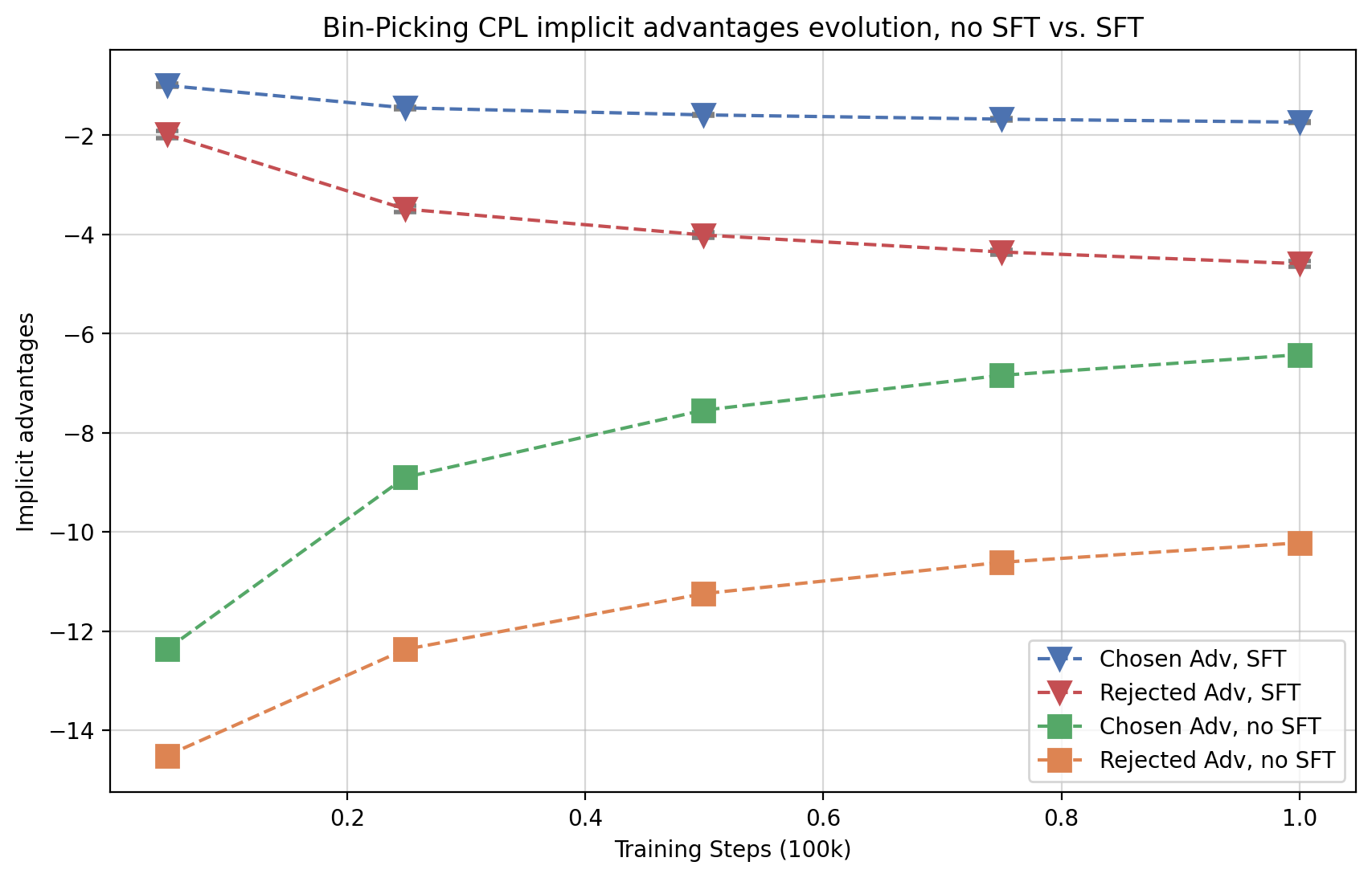
Abstract: Reinforcement Learning From Human Feedback (RLHF) has been critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline, direct alignment algorithms such as Direct Preference Optimization (DPO) have emerged as an alternative approach. Although DPO solves the same objective as the standard RLHF setup, there is a mismatch between the two approaches. Standard RLHF deploys reinforcement learning in a specific token-level MDP, while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference. We theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation. Using our theoretical results, we provide three concrete empirical insights. First, we show that because of its token level interpretation, DPO is able to perform some type of credit assignment. Next, we prove that under the token level formulation, classical search-based algorithms, such as MCTS, which have recently been applied to the language generation space, are equivalent to likelihood-based search on a DPO policy. Empirically we show that a simple beam search yields meaningful improvement over the base DPO policy. Finally, we show how the choice of reference policy causes implicit rewards to decline during training. We conclude by discussing applications of our work, including information elicitation in multi-turn dialogue, reasoning, agentic applications and end-to-end training of multi-model systems.
- Preference-based policy learning. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 2011.
- Star-gate: Teaching language models to ask clarifying questions, 2024.
- A general theoretical paradigm to understand learning from human preferences, 2023.
- Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022a.
- Constitutional ai: Harmlessness from ai feedback, 2022b.
- Improving image generation with better captions, 2023. URL https://cdn.openai.com/papers/dall-e-3.pdf.
- Pythia: A suite for analyzing large language models across training and scaling, 2023.
- Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301, 2023a.
- Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301, 2023b.
- Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952. doi: https://doi.org/10.2307/2334029.
- Dense reward for free in reinforcement learning from human feedback. arXiv preprint arXiv:2402.00782, 2024.
- Deep reinforcement learning from human preferences. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/d5e2c0adad503c91f91df240d0cd4e49-Paper.pdf.
- Sequencematch: Imitation learning for autoregressive sequence modelling with backtracking. arXiv preprint arXiv:2306.05426, 2023.
- Alpacafarm: A simulation framework for methods that learn from human feedback, 2024.
- Implementation matters in deep policy gradients: A case study on ppo and trpo. arXiv preprint arXiv:2005.12729, 2020.
- Scaling rectified flow transformers for high-resolution image synthesis, 2024.
- Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. arXiv preprint arXiv:2305.16381, 2023.
- Alphazero-like tree-search can guide large language model decoding and training, 2024.
- Scaling laws for reward model overoptimization. International Conference on machine Learning, 2023.
- Iq-learn: Inverse soft-q learning for imitation, 2022.
- Photorealistic video generation with diffusion models, 2023.
- Inverse preference learning: Preference-based rl without a reward function. Advances in Neural Information Processing Systems, 36, 2024.
- Contrastive preference learning: Learning from human feedback without reinforcement learning. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=iX1RjVQODj.
- V-star: Training verifiers for self-taught reasoners, 2024.
- Gaia-1: A generative world model for autonomous driving, 2023.
- Deal: Decoding-time alignment for large language models, 2024.
- Critic-guided decoding for controlled text generation. arXiv preprint arXiv:2212.10938, 2022.
- Models of human preference for learning reward functions. Transactions on Machine Learning Research, 2023.
- Learning optimal advantage from preferences and mistaking it for reward. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 10066–10073, 2024.
- Openassistant conversations – democratizing large language model alignment, 2023.
- Rewardbench: Evaluating reward models for language modeling, 2024.
- Aligning text-to-image models using human feedback. arXiv e-prints, pp. arXiv–2302, 2023.
- Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review, 2018.
- Offline reinforcement learning: Tutorial, review, and perspectives on open problems, 2020.
- Learning to decode for future success. arXiv preprint arXiv:1701.06549, 2017.
- Don’t throw away your value model! making ppo even better via value-guided monte-carlo tree search decoding, 2023a.
- Making ppo even better: Value-guided monte-carlo tree search decoding. arXiv preprint arXiv:2309.15028, 2023b.
- Controlled decoding from language models. arXiv preprint arXiv:2310.17022, 2023.
- Controlled decoding from language models, 2024.
- Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- Webgpt: Browser-assisted question-answering with human feedback, 2022.
- Policy invariance under reward transformations: Theory and application to reward shaping. In Icml, volume 99, pp. 278–287, 1999.
- Training language models to follow instructions with human feedback. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 27730–27744. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf.
- Smaug: Fixing failure modes of preference optimisation with dpo-positive. arXiv preprint arXiv:2402.13228, 2024.
- Let’s reinforce step by step. arXiv preprint arXiv:2311.05821, 2023.
- Disentangling length from quality in direct preference optimization, 2024.
- Direct preference optimization: Your language model is secretly a reward model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://arxiv.org/abs/2305.18290.
- Proximal policy optimization algorithms, 2017.
- Offline rl for natural language generation with implicit language q learning. In The Eleventh International Conference on Learning Representations, 2022.
- Trial and error: Exploration-based trajectory optimization for llm agents, 2024.
- Learning to summarize from human feedback, 2022.
- Diffusion model alignment using direct preference optimization, 2023.
- A bayesian approach for policy learning from trajectory preference queries. In Advances in Neural Information Processing Systems, 2012.
- Fudge: Controlled text generation with future discriminators. arXiv preprint arXiv:2104.05218, 2021.
- Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
- Slic-hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425, 2023a.
- Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. arXiv preprint arXiv:2311.16839, 2023b.
- Brian D Ziebart. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010.
- Maximum entropy inverse reinforcement learning. In Aaai, volume 8, pp. 1433–1438. Chicago, IL, USA, 2008.
- Fine-tuning language models from human preferences, 2020.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

