- The paper introduces EvalGen, a framework that leverages LLMs to generate, synthesize, and iteratively adjust evaluation criteria for superior human alignment.
- It demonstrates that fewer, well-aligned assertions can achieve robust evaluation in diverse contexts such as medical records and e-commerce descriptions.
- User studies reveal that continuous human feedback integration improves evaluation accuracy while highlighting challenges like criteria drift.
Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences
This paper introduces a unique approach to aligning LLM-generated evaluations with human preferences through mixed-initiative methods. The proposed system, EvalGen, aims to address the inherent challenges in effectively validating LLM outputs, especially when human feedback is costly and LLM evaluations themselves could be flawed. It presents a workflow to help users systematically tune LLM-assisted evaluations to reflect human evaluation criteria more closely.
Introduction to the Problem
Validating outputs from LLMs poses significant challenges due to their limitations in accuracy and consistency. Traditional methods heavily rely on human evaluation, but this approach is time-consuming and not scalable. The paper highlights the growing reliance on LLMs to evaluate other LLMs, a circular validation loop that necessitates solutions ensuring alignment with human evaluators. EvalGen is introduced as a solution—facilitating the creation, evaluation, and alignment of LLM-output assessment criteria.
The EvalGen Workflow
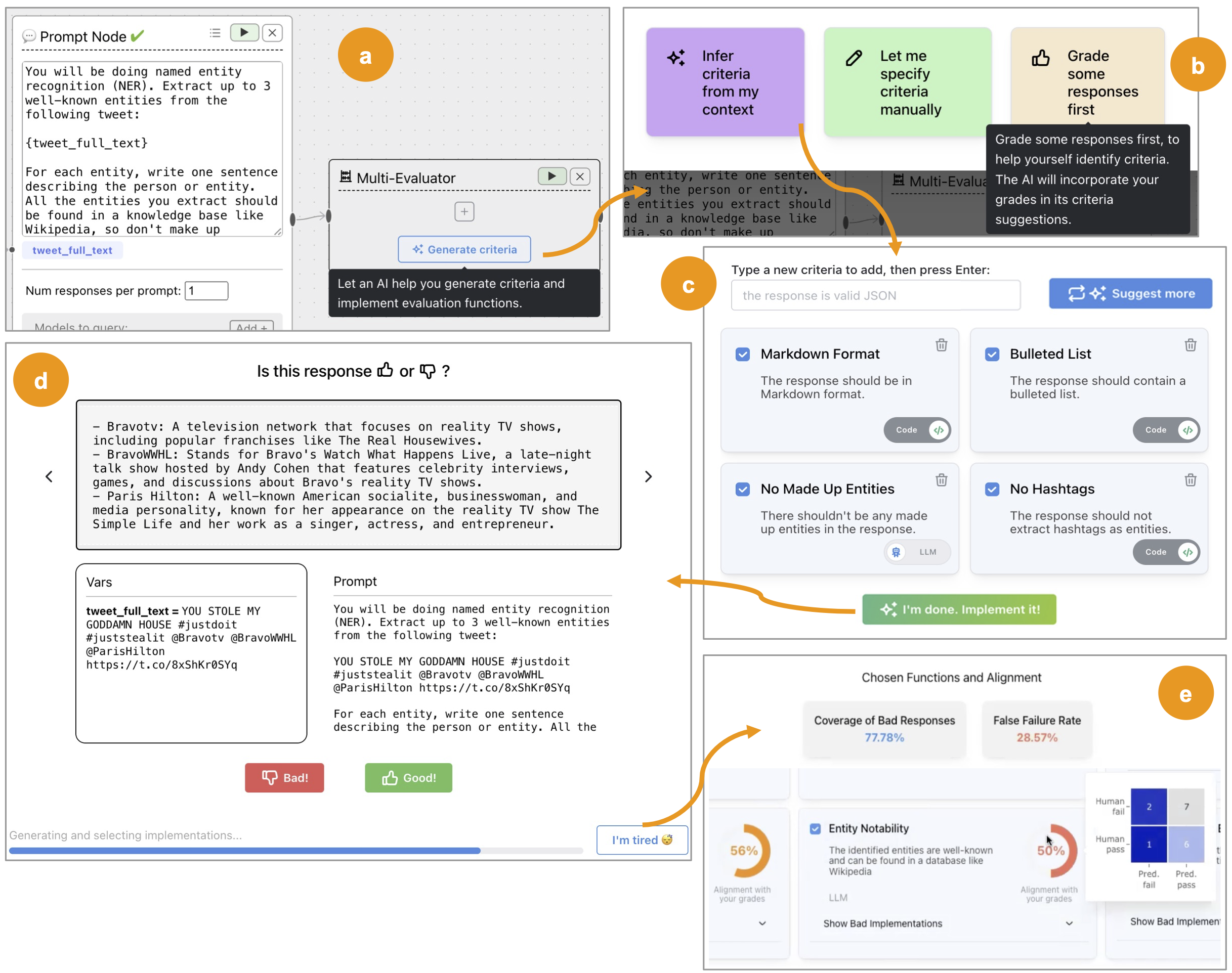
EvalGen is embedded within the ChainForge tool for prompt engineering, designed to aid users in developing evaluation criteria and corresponding assertions (either through code or via further LLM-generated prompts). Users engage with EvalGen through the following workflow:
- Criteria Generation: Using LLMs to generate potential evaluation criteria from user prompts. Users can accept these criteria or modify them to better suit their needs.
- Assertion Synthesis: EvalGen generates multiple implementations of each chosen criterion, allowing for both code-based and LLM-based assertions. The choice between code and LLM-based evaluation methods is available based on user preference.
- Grading Outputs: Users are asked to provide feedback on LLM outputs to capture their evaluation preferences through a simple rating system. This feedback actively influences which assertion implementations are selected for each criterion.
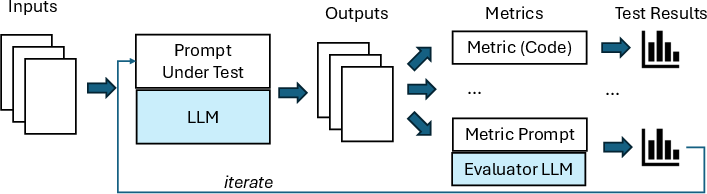
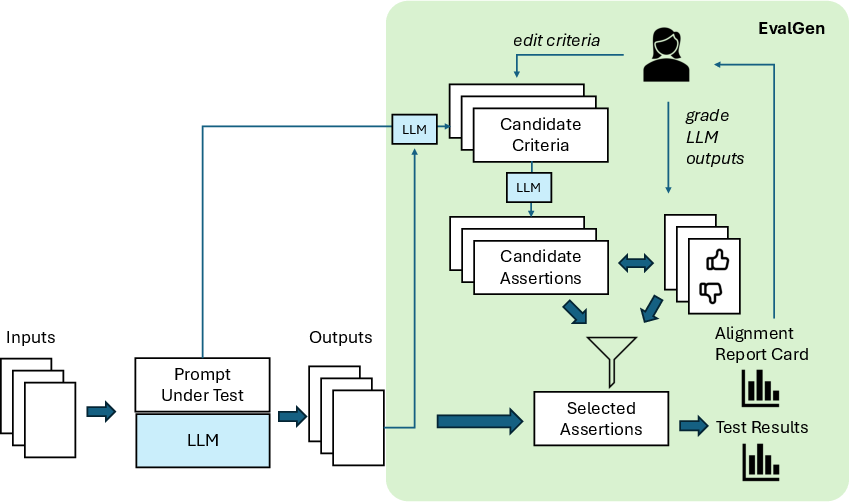
Figure 1: Typical Evaluation Pipeline
- Alignment and Adjustment: EvalGen ranks the candidate assertions according to their alignment with the user's feedback. The alignment process prioritizes assertions that effectively distinguish between good and bad output relative to the user's grading.
Methodology and Evaluation
The assessment of EvalGen's efficacy was conducted using datasets tailored for two distinct LLM pipeline tasks: medical records and e-commerce product descriptions. By leveraging ground-truth annotations for output evaluation, the study showcased EvalGen's capacity to reduce the number of assertions while maintaining (or even enhancing) alignment with human preferences, compared to existing approaches like SPADE.
Results of the System Evaluation
EvalGen demonstrated its effectiveness by providing better-aligned evaluations with fewer assertions, highlighting its strength in leveraging human-specified criteria. Notably, users could achieve greater coverage and alignment with their preferences, addressing a significant challenge in LLM-based evaluation pipelines. However, the study highlights the challenge posed by criteria drift—where the definition of evaluation criteria evolves as users become more familiar with the outputs, necessitating iterative refinement.
User Study Insights
A user study involving industry practitioners revealed EvalGen's advantages and areas for improvement:
Challenges and Future Directions
Despite its effectiveness, the study identified challenges with the alignment process, especially pertaining to criteria drift and the subjective nature of what constitutes "alignment." Future work should explore optimizations for handling evolving criteria definitions and more robust integration of human feedback cycles to continuously refine LLM evaluators.
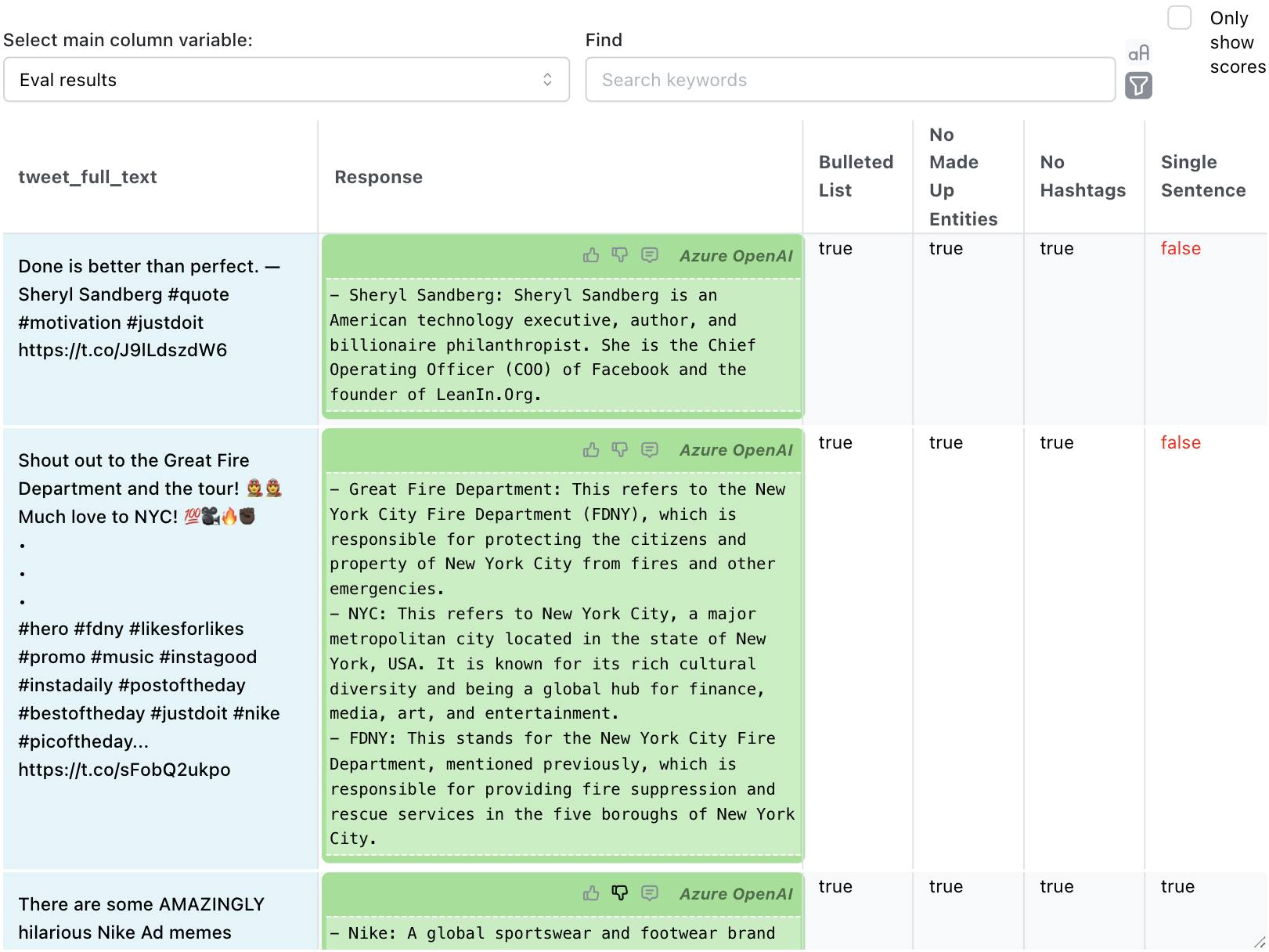
Figure 3: The Table View, showing inputs, LLM outputs, and evaluation results per criteria for the NER task
.
Conclusion
The study's findings underpin the critical insights into the dynamic and iterative nature of aligning LLM-based evaluations with human judgments. EvalGen emerges as an early attempt at creating more intelligent synergies between human evaluators and LLM-based systems. As LLM applications continue to expand, developing dependable, human-aligned evaluation methodologies will be crucial for their broader adoption and trustworthiness.
This work lays the foundational principles for future research into mixed-initiative evaluation systems, offering a robust framework to examine human-in-the-loop learning systems and their application in AI.