Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
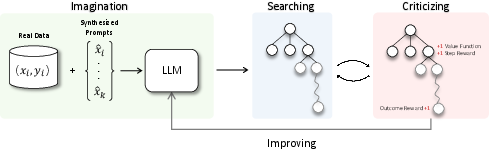
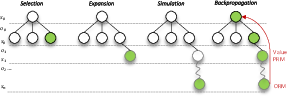
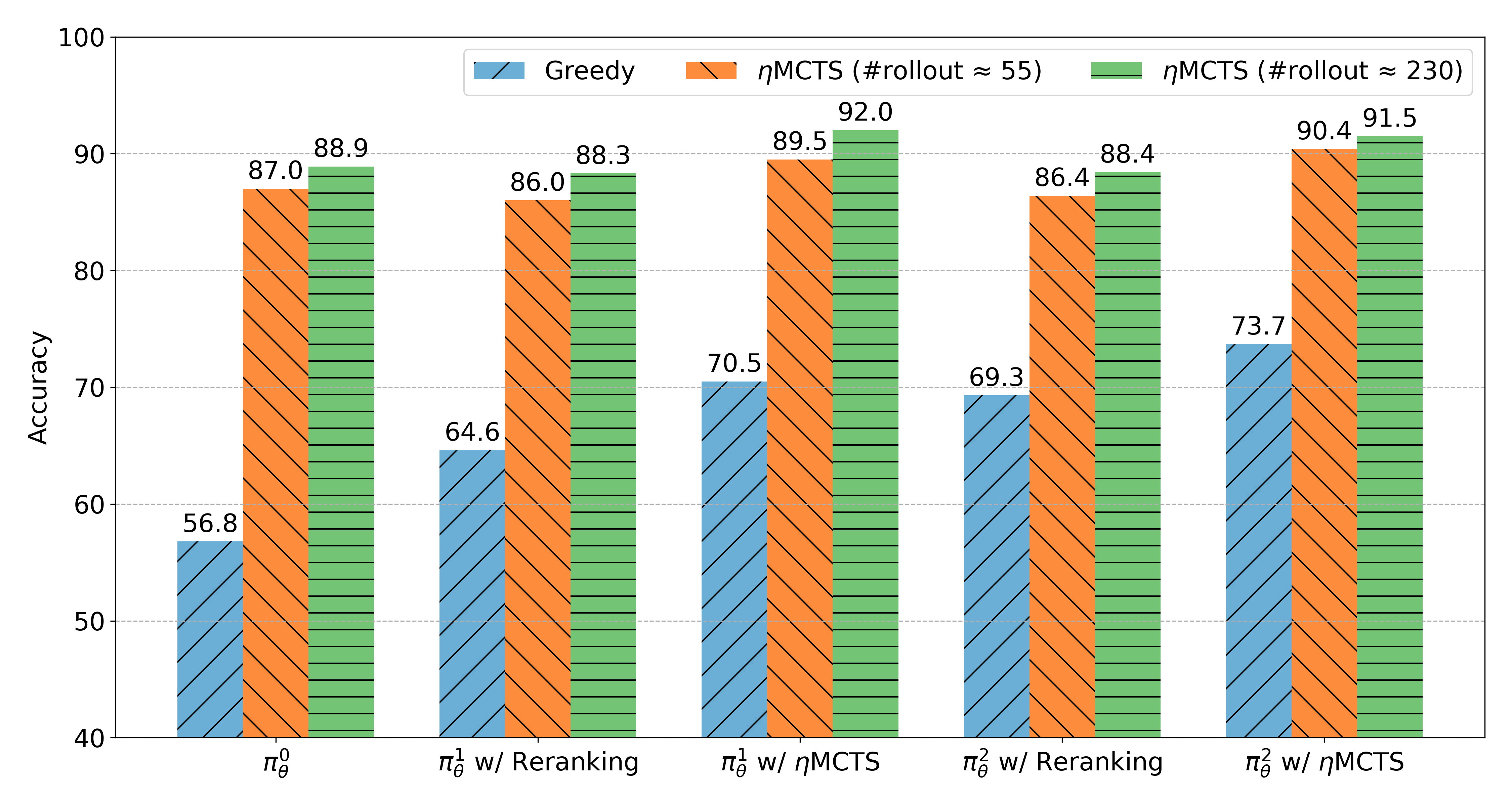
Abstract: Despite the impressive capabilities of LLMs on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
- Finite-time analysis of the multiarmed bandit problem. Machine learning, 47:235–256, 2002.
- Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, pp. 17682–17690, 2024.
- Measuring progress on scalable oversight for large language models. arXiv preprint arXiv:2211.03540, 2022.
- Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335, 2024.
- Intrinsically motivated reinforcement learning. Advances in neural information processing systems, 17, 2004.
- Generative ai for math: Abel. https://github.com/GAIR-NLP/abel, 2023.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Training deep convolutional neural networks to play go. In International conference on machine learning, pp. 1766–1774. PMLR, 2015.
- Jeffery Allen Clouse. On integrating apprentice learning and reinforcement learning. University of Massachusetts Amherst, 1996.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Monte carlo tree search with options for general video game playing. In 2016 IEEE Conference on Computational Intelligence and Games (CIG), pp. 1–8. IEEE, 2016.
- Everything of thoughts: Defying the law of penrose triangle for thought generation. arXiv preprint arXiv:2311.04254, 2023.
- Alphazero-like tree-search can guide large language model decoding and training. arXiv preprint arXiv:2309.17179, 2023.
- Pal: Program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. PMLR, 2023.
- Critic: Large language models can self-correct with tool-interactive critiquing. In Second Agent Learning in Open-Endedness Workshop, 2023a.
- Tora: A tool-integrated reasoning agent for mathematical problem solving. arXiv preprint arXiv:2309.17452, 2023b.
- Human-instruction-free llm self-alignment with limited samples. arXiv preprint arXiv:2401.06785, 2024.
- Reasoning with language model is planning with world model. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 8154–8173, 2023.
- Measuring mathematical problem solving with the math dataset, 2021.
- A closer look at the self-verification abilities of large language models in logical reasoning. arXiv preprint arXiv:2311.07954, 2023.
- Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798, 2023.
- Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35:3843–3857, 2022.
- Self-alignment with instruction backtranslation. arXiv preprint arXiv:2308.06259, 2023.
- Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- Making ppo even better: Value-guided monte-carlo tree search decoding. arXiv preprint arXiv:2309.15028, 2023.
- Jieyi Long. Large language model guided tree-of-thought. arXiv preprint arXiv:2305.08291, 2023.
- A survey of reinforcement learning informed by natural language. ArXiv, abs/1906.03926, 2019. URL https://api.semanticscholar.org/CorpusID:182952502.
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36, 2024.
- Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021.
- R OpenAI. Gpt-4 technical report. arXiv, pp. 2303–08774, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Composite task-completion dialogue policy learning via hierarchical deep reinforcement learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2017.
- Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Is reinforcement learning (not) for natural language processing?: Benchmarks, baselines, and building blocks for natural language policy optimization. ArXiv, abs/2210.01241, 2022. URL https://api.semanticscholar.org/CorpusID:252693405.
- Self-critiquing models for assisting human evaluators. arXiv preprint arXiv:2206.05802, 2022.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489, 2016.
- Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv preprint arXiv:1712.01815, 2017.
- On the self-verification limitations of large language models on reasoning and planning tasks. arXiv preprint arXiv:2402.08115, 2024.
- Principle-driven self-alignment of language models from scratch with minimal human supervision. arXiv preprint arXiv:2305.03047, 2023.
- Reinforcement learning: An introduction. MIT press, 2018.
- Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial Intelligence, 112(1):181–211, 1999a. ISSN 0004-3702. doi: https://doi.org/10.1016/S0004-3702(99)00052-1. URL https://www.sciencedirect.com/science/article/pii/S0004370299000521.
- Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2):181–211, 1999b.
- Richard Stuart Sutton. Temporal credit assignment in reinforcement learning. University of Massachusetts Amherst, 1984.
- Reinforcement learning agents providing advice in complex video games. Connection Science, 26(1):45–63, 2014.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Large language models still can’t plan (a benchmark for llms on planning and reasoning about change). arXiv preprint arXiv:2206.10498, 2022.
- Revisiting move groups in monte-carlo tree search. In Advances in Computer Games: 13th International Conference, ACG 2011, Tilburg, The Netherlands, November 20-22, 2011, Revised Selected Papers 13, pp. 13–23. Springer, 2012.
- Math-shepherd: Verify and reinforce llms step-by-step without human annotations. CoRR, abs/2312.08935, 2023a.
- Shepherd: A critic for language model generation. arXiv preprint arXiv:2308.04592, 2023b.
- Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560, 2022.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Self-evaluation guided beam search for reasoning. Advances in Neural Information Processing Systems, 36, 2024.
- Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
- Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Advancing llm reasoning generalists with preference trees. arXiv preprint arXiv:2404.02078, 2024a.
- Self-rewarding language models. arXiv preprint arXiv:2401.10020, 2024b.
- Deductive beam search: Decoding deducible rationale for chain-of-thought reasoning. arXiv preprint arXiv:2401.17686, 2024.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

