Length Generalization of Causal Transformers without Position Encoding
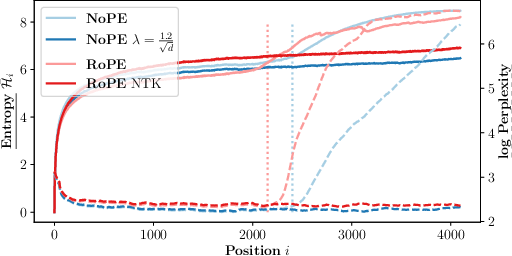
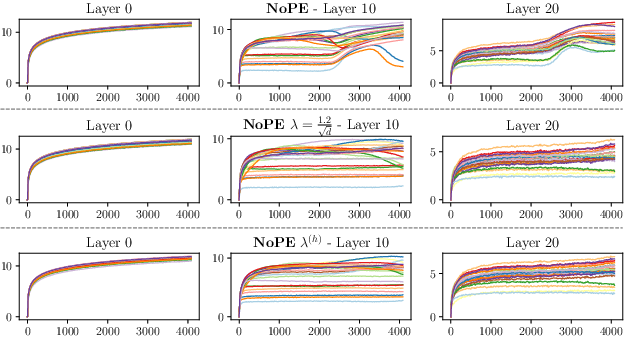
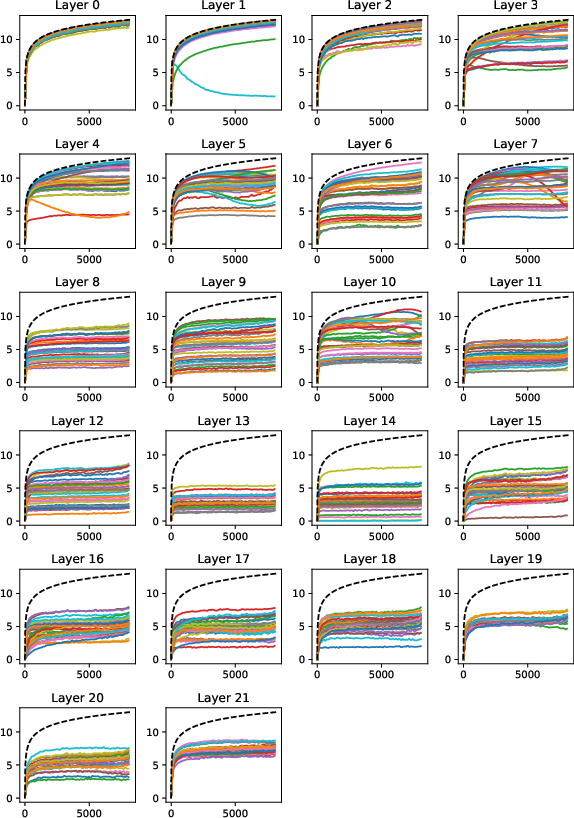
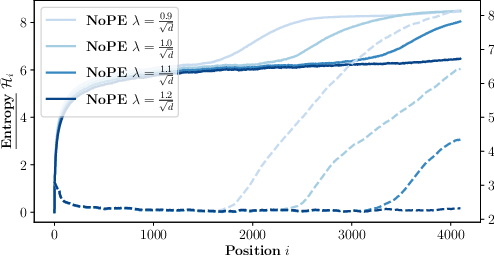
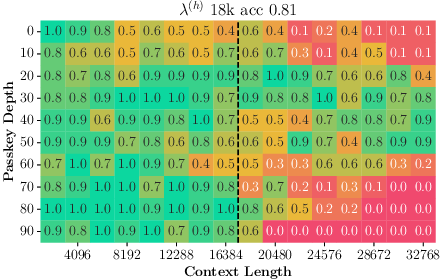
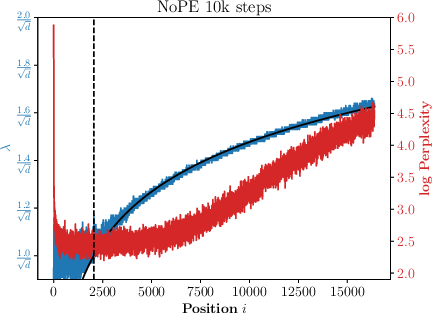
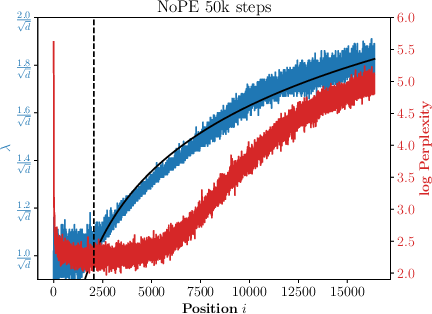
Abstract: Generalizing to longer sentences is important for recent Transformer-based LLMs. Besides algorithms manipulating explicit position features, the success of Transformers without position encodings (NoPE) provides a new way to overcome the challenge. In this paper, we study the length generalization property of NoPE. We find that although NoPE can extend to longer sequences than the commonly used explicit position encodings, it still has a limited context length. We identify a connection between the failure of NoPE's generalization and the distraction of attention distributions. We propose a parameter-efficient tuning for searching attention heads' best temperature hyper-parameters, which substantially expands NoPE's context size. Experiments on long sequence language modeling, the synthetic passkey retrieval task and real-world long context tasks show that NoPE can achieve competitive performances with state-of-the-art length generalization algorithms. The source code is publicly accessible
- Proof-pile.
- Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508.
- BigScience Workshop. 2022. Bloom (revision 4ab0472).
- bloc97. 2023a. Add NTK-Aware interpolation "by parts" correction.
- bloc97. 2023b. NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation.
- bloc97. 2023c. NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation.
- Extending context window of large language models via positional interpolation.
- Latent positional information is in the self-attention variance of transformer language models without positional embeddings. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1183–1193, Toronto, Canada. Association for Computational Linguistics.
- David Chiang and Peter Cholak. 2022. Overcoming a theoretical limitation of self-attention. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7654–7664.
- A survey on long text modeling with transformers. arXiv preprint arXiv:2302.14502.
- emozilla. 2023. Dynamically Scaled RoPE further increases performance of long context LLaMA with zero fine-tuning.
- Lm-infinite: Simple on-the-fly length generalization for large language models.
- Transformer language models without positional encodings still learn positional information. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 1382–1390, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Automl: A survey of the state-of-the-art. Knowledge-Based Systems, 212:106622.
- Advancing transformer architecture in long-context large language models: A comprehensive survey. arXiv preprint arXiv:2311.12351.
- Atlas: Few-shot learning with retrieval augmented language models. J. Mach. Learn. Res., 24:251:1–251:43.
- Llm maybe longlm: Self-extend llm context window without tuning.
- kaiokendev. 2023. Things iḿ learning while training superhot.
- The impact of positional encoding on length generalization in transformers. In Thirty-seventh Conference on Neural Information Processing Systems.
- Starcoder: may the source be with you!
- Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. In International Conference on Learning Representations.
- Amirkeivan Mohtashami and Martin Jaggi. 2023a. Landmark attention: Random-access infinite context length for transformers.
- Amirkeivan Mohtashami and Martin Jaggi. 2023b. Random-access infinite context length for transformers. In Thirty-seventh Conference on Neural Information Processing Systems.
- MosaicML NLP Team. 2023. Introducing mpt-7b: A new standard for open-source, commercially usable llms. Accessed: 2023-05-05.
- Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23, New York, NY, USA. Association for Computing Machinery.
- Yarn: Efficient context window extension of large language models.
- YaRN: Efficient context window extension of large language models. In The Twelfth International Conference on Learning Representations.
- Train short, test long: Attention with linear biases enables input length extrapolation. In International Conference on Learning Representations.
- Train short, test long: Attention with linear biases enables input length extrapolation.
- Compressive transformers for long-range sequence modelling. International Conference on Learning Representations,International Conference on Learning Representations.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- SlimPajama: A 627B token cleaned and deduplicated version of RedPajama.
- Jianlin Su. 2021. Attentionś scale operation from entropy invariance.
- Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063.
- Roformer: Enhanced transformer with rotary position embedding. CoRR, abs/2104.09864.
- A length-extrapolatable transformer. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14590–14604, Toronto, Canada. Association for Computational Linguistics.
- Llama 2: Open foundation and fine-tuned chat models.
- Attention is all you need. In Advances in Neural Information Processing Systems, volume 30.
- Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models. arXiv preprint arXiv:2310.00746.
- Efficient streaming language models with attention sinks.
- Soaring from 4k to 400k: Extending llm’s context with activation beacon.
- Tinyllama: An open-source small language model.
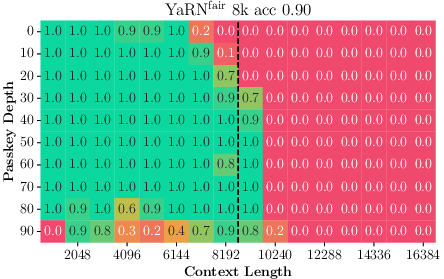
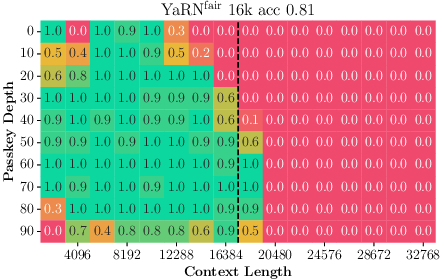
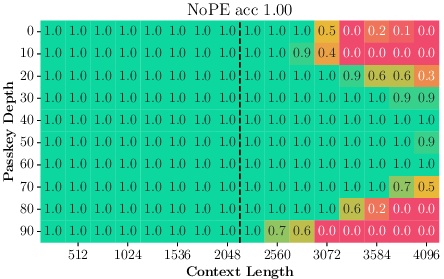
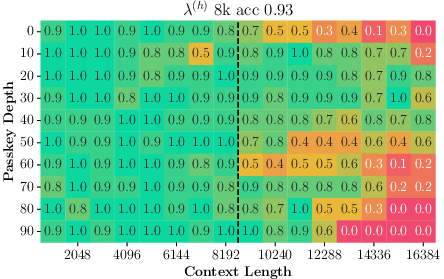
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.