Compression Represents Intelligence Linearly
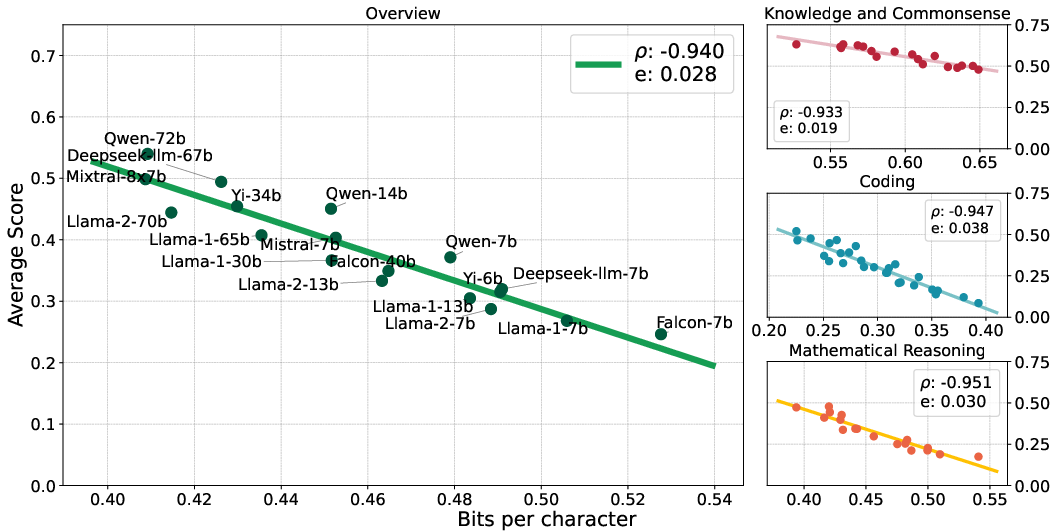
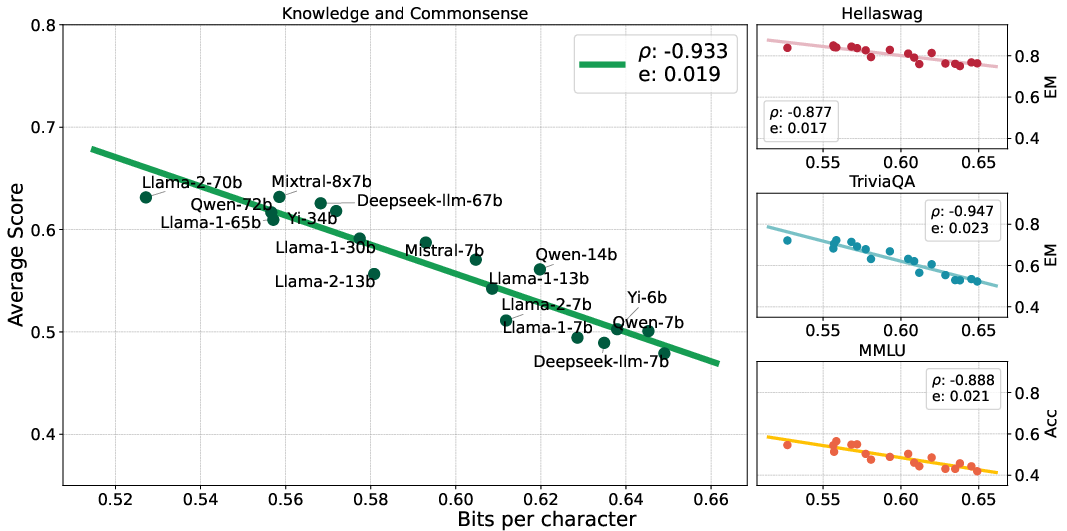
Abstract: There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been shown to be equivalent to compression, which offers a compelling rationale for the success of LLMs: the development of more advanced LLMs is essentially enhancing compression which facilitates intelligence. Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors. Given the abstract concept of "intelligence", we adopt the average downstream benchmark scores as a surrogate, specifically targeting intelligence related to knowledge and commonsense, coding, and mathematical reasoning. Across 12 benchmarks, our study brings together 31 public LLMs that originate from diverse organizations. Remarkably, we find that LLMs' intelligence -- reflected by average benchmark scores -- almost linearly correlates with their ability to compress external text corpora. These results provide concrete evidence supporting the belief that superior compression indicates greater intelligence. Furthermore, our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. We open-source our compression datasets as well as our data collection pipelines to facilitate future researchers to assess compression properly.
- Yi: Open foundation models by 01.ai, 2024.
- The falcon series of open language models. arXiv preprint arXiv:2311.16867, 2023.
- When benchmarks are targets: Revealing the sensitivity of large language model leaderboards. arXiv preprint arXiv:2402.01781, 2024.
- Anthropic. Introducing the next generation of claude, 2024. URL https://www.anthropic.com/news/claude-3-family.
- Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631, 2023.
- Adaptive input representations for neural language modeling. arXiv preprint arXiv:1809.10853, 2018.
- Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954, 2024.
- Improving language models by retrieving from trillions of tokens. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato (eds.), Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pp. 2206–2240. PMLR, 17–23 Jul 2022. URL https://proceedings.mlr.press/v162/borgeaud22a.html.
- Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=YfZ4ZPt8zd.
- Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- CodeParrot. codeparrot-clean. https://huggingface.co/datasets/codeparrot/codeparrot-clean, 2021.
- Language modeling is compression. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=jznbgiynus.
- Understanding emergent abilities of language models from the loss perspective, 2024.
- Incoder: A generative model for code infilling and synthesis. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=hQwb-lbM6EL.
- Language models scale reliably with over-training and on downstream tasks, 2024.
- A framework for few-shot language model evaluation, 12 2023a. URL https://zenodo.org/records/10256836.
- Pal: Program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. PMLR, 2023b.
- Demystifying prompts in language models via perplexity estimation. arXiv preprint arXiv:2212.04037, 2022.
- Deepseek-coder: When the large language model meets programming–the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024.
- Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021a. URL https://openreview.net/forum?id=d7KBjmI3GmQ.
- Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021b.
- A formal definition of intelligence based on an intensional variant of algorithmic complexity. In Proceedings of International Symposium of Engineering of Intelligent Systems (EIS98), pp. 146–163, 1998.
- Marcus Hutter. The hutter prize. http://prize.hutter1.net, 2006.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min-Yen Kan (eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1601–1611, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1147. URL https://aclanthology.org/P17-1147.
- Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
- DS-1000: A natural and reliable benchmark for data science code generation. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp. 18319–18345. PMLR, 23–29 Jul 2023.
- Universal intelligence: A definition of machine intelligence. Minds and machines, 17:391–444, 2007.
- A universal measure of intelligence for artificial agents. In International Joint Conference on Artificial Intelligence, volume 19, pp. 1509. LAWRENCE ERLBAUM ASSOCIATES LTD, 2005.
- Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
- Starcoder 2 and the stack v2: The next generation. arXiv preprint arXiv:2402.19173, 2024.
- Towards boosting the open-domain chatbot with human feedback. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 4060–4078, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.224. URL https://aclanthology.org/2023.acl-long.224.
- Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8086–8098, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.556. URL https://aclanthology.org/2022.acl-long.556.
- Paloma: A benchmark for evaluating language model fit, 2023.
- Matt Mahoney. Large text compression benchmark, 2011.
- Matthew V Mahoney. Text compression as a test for artificial intelligence. AAAI/IAAI, 970, 1999.
- MistralAI. Mixtral of experts: A high quality sparse mixture-of-experts. Mistral Blog, 2023. URL www.mistral.ai/news/mixtral-of-experts/.
- R. Pasco. Source coding algorithms for fast data compression (ph.d. thesis abstr.). IEEE Transactions on Information Theory, 23(4):548–548, 1977. doi: 10.1109/TIT.1977.1055739.
- Keiran Paster. Testing language models on a held-out high school national finals exam. https://huggingface.co/datasets/keirp/hungarian_national_hs_finals_exam, 2023.
- Shortformer: Better language modeling using shorter inputs. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 5493–5505, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.427. URL https://aclanthology.org/2021.acl-long.427.
- J. J. Rissanen. Generalized kraft inequality and arithmetic coding. IBM Journal of Research and Development, 20(3):198–203, 1976. doi: 10.1147/rd.203.0198.
- Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2023.
- Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=RIu5lyNXjT.
- C. E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27(3):379–423, 1948. doi: 10.1002/j.1538-7305.1948.tb01338.x.
- Claude E Shannon. Prediction and entropy of printed english. Bell system technical journal, 30(1):50–64, 1951.
- Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Detecting pretraining data from large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=zWqr3MQuNs.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- AM Turing. Computing machinery and intelligence. Mind, 59(236):433–460, 1950.
- Emergent abilities of large language models. Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=yzkSU5zdwD. Survey Certification.
- Skywork: A more open bilingual foundation model. arXiv preprint arXiv:2310.19341, 2023.
- Ccnet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of The 12th Language Resources and Evaluation Conference, pp. 4003–4012, 2020.
- Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825, 2023.
- HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Lluís Màrquez (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4791–4800, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1472. URL https://aclanthology.org/P19-1472.
- Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364, 2023.
- LIMA: Less is more for alignment. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=KBMOKmX2he.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

