- The paper presents a multi-teacher distillation framework that integrates outputs from several teacher models to guide student networks in image super-resolution, achieving up to 0.46 dB PSNR improvements.
- The methodology employs DCTSwin blocks that combine discrete cosine transform with Swin transformer self-attention to capture both spatial and frequency domain features.
- Experimental results on benchmarks like Set5 and Urban100 demonstrate MTKD's superior ability in reconstructing complex textures and sharp edges compared to traditional single-teacher methods.
MTKD: Multi-Teacher Knowledge Distillation for Image Super-Resolution
Introduction
Multi-Teacher Knowledge Distillation (MTKD) introduces a novel framework specifically designed for image super-resolution tasks. Unlike traditional knowledge distillation approaches that typically involve a single teacher model, MTKD utilizes multiple teacher models to enhance the learning of compact student networks. This approach leverages the distinct advantages of multiple teacher models by combining and refining their outputs, subsequently guiding the student model's learning process.
Knowledge distillation in image super-resolution has predominantly adopted strategies developed for broader computer vision tasks, which utilize single-teacher frameworks along with straightforward loss functions. MTKD breaks away from this traditional mold through a new wavelet-based loss function aimed at optimizing performance by observing differences in spatial and frequency domains. The evaluation results exhibit significant performance enhancements over existing methods, with improvements of up to 0.46 dB in PSNR across various network structures.
Methodology
Multi-Teacher Knowledge Distillation Framework
The MTKD framework is depicted as employing multiple teacher models in conjunction with a novel knowledge aggregation network. This network utilizes discrete cosine transform Swin blocks (DCTSwin), enabling the combination of outputs from various teacher models to generate an enriched representation for guiding student models.
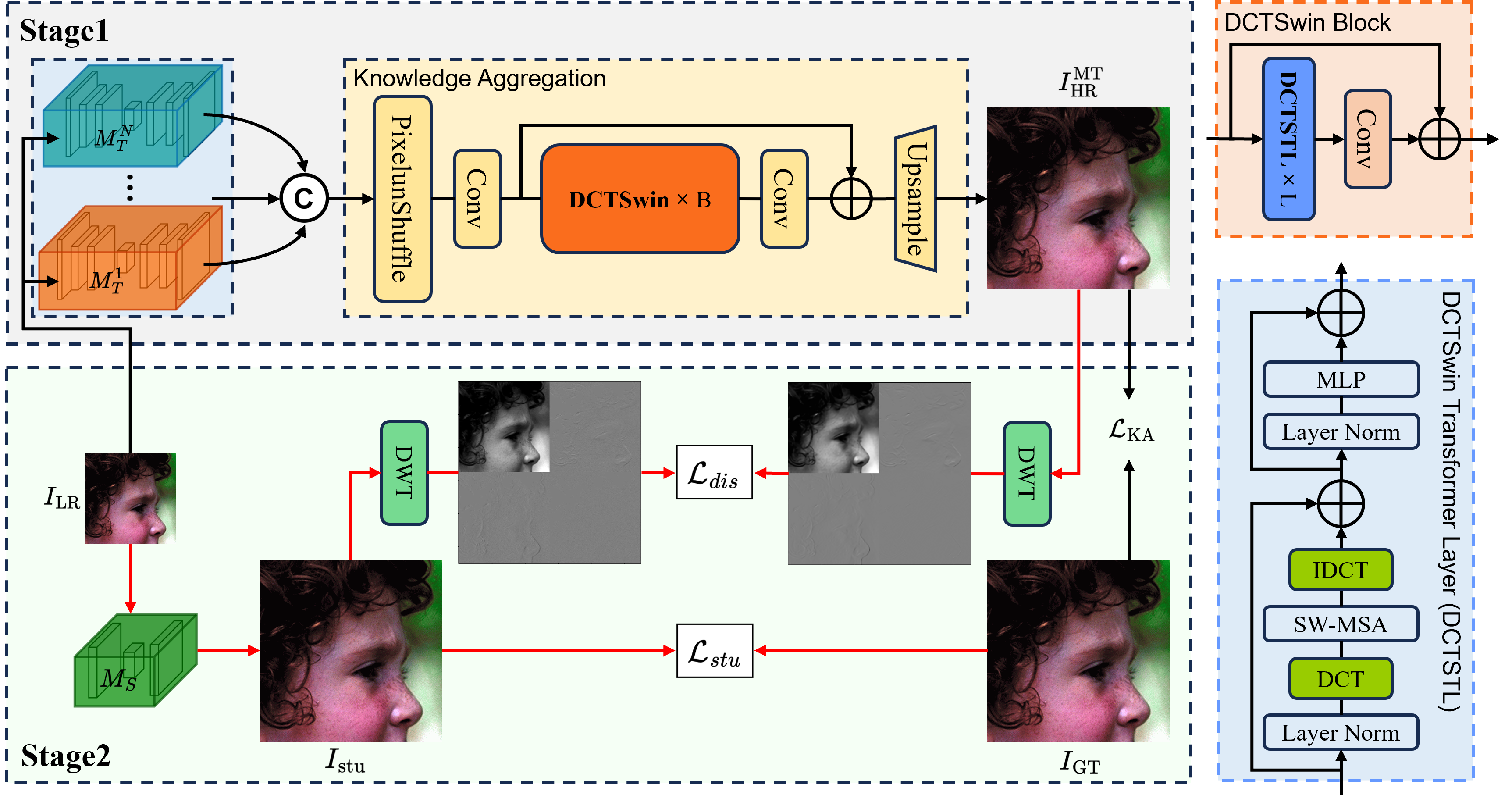
Figure 1: Illustration of the proposed Multi-Teacher Knowledge Distillation framework.
The aggregation network extracts both spatial and frequency information, further refined by discrete wavelet transform (DWT)-based loss functions during distillation. This dual-domain learning facilitates improved high-frequency detail reconstruction in the super-resolution process.
DCTSwin Network
DCTSwin blocks incorporate discrete cosine transform (DCT) and inverse DCT (IDCT) operations, integrated with window-based self-attention mechanisms akin to Swin transformers. This structure aids in capturing extensive contextual interactions and enhancing the learning capacity of the network.
Distillation Loss Function
MTKD employs a DWT-based loss function during the distillation process. This function assesses discrepancies between the student and aggregated teacher outputs across distinct frequency subbands. The loss function balances spatial and frequency aspects, ensuring that high-frequency information, crucial for realistic resolution enhancements, is effectively learned.
Experimental Evaluation
MTKD's efficacy was validated against various widely-used ISR networks, including EDSR, SwinIR, and RCAN. The approach consistently surpassed existing distillation methods such as basic KD, AT, FAKD, DUKD, and CrossKD, achieving notable improvements in PSNR and SSIM metrics across diverse datasets like Set5, Set14, BSD100, and Urban100.
Qualitative Analysis
MTKD demonstrated superior capabilities in reconstructing complex textures and sharp edges compared to other approaches. Urban100 and BSD100 datasets, known for their challenging high-detail requirements, highlighted MTKD's proficiency in delivering high-quality super-resolution results.


















Figure 2: The ×4 super-resolution results of SwinIR models on (a) img012, (b) img062 from Urban100. PSNRs and SSIMs are displayed below each image.
Ablation Studies
Teacher Contributions
The study confirmed the importance of leveraging multiple teacher models, resulting in enhanced representation consistency and richness. The Local Attribution Maps tool further demonstrated robust contributions from all employed teacher models.
Network Structure Variants
Replacements of the DCTSwin blocks with alternative architectures confirmed the design's effectiveness in both spatial and frequency domain learning.
Loss Function Comparisons
The superiority of the wavelet-based loss function was evident in its ability to facilitate high-frequency detail learning, outperforming traditional L1 and DCT-based loss functions.






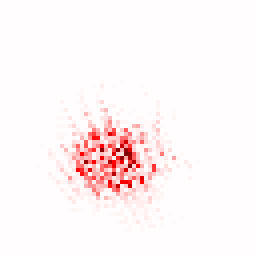
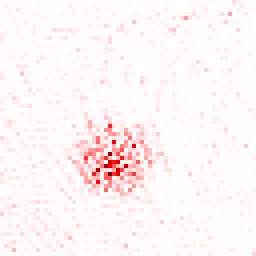
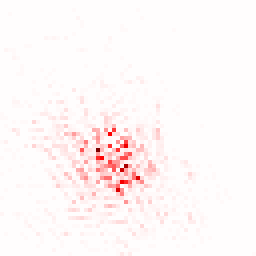
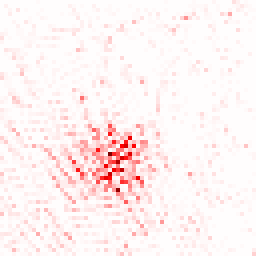
Figure 3: The illustration of the contribution from each teacher model using the Local Attribution Maps tool.
Conclusion
MTKD establishes a comprehensive framework for achieving high-performance image super-resolution through multi-teacher knowledge distillation. By integrating extensive domain knowledge from diverse teacher networks and employing an innovative wavelet-based loss function, MTKD delivers consistent advancements in super-resolution tasks. Future research should explore extending these methodologies to other computer vision realms, potentially enhancing tasks with high detail and resolution demands.