- The paper introduces a novel entropy-guided extrapolative decoding method that significantly reduces hallucination in LLM outputs.
- It leverages dynamic contrasting layer selection and logit extrapolation to enhance factuality using entropy metrics across transformer layers.
- Experimental results across multiple benchmarks demonstrate improved truthfulness and chain-of-thought reasoning in diverse tasks.
Abstract
The paper addresses a fundamental challenge in LLMs: their tendency to hallucinate by generating content that is ungrounded from their training data. The research introduces a novel approach known as Entropy Guided Extrapolative Decoding that aims to enhance the factuality of LLM outputs without the over-reliance on the final transformer layer as the benchmark of model maturity. By extrapolating critical token probabilities and employing an entropy-guided lower layer selection method, the novel approach significantly surpasses state-of-the-art performance on several factual and reasoning benchmarks.
Introduction
As LLMs advance, their ability to perform various tasks, such as natural language processing, continues to impress researchers globally. However, these models are known to generate hallucinations—produced content that doesn't align with their training data. Improving factual accuracy is critical for deploying LLMs safely and installing trust in AI systems, particularly as these models continue to scale and evolve.
Conventional methods highlight the contrast between finalized predictions and prior inferences from earlier layers. Yet, the dependency on the final layer as the most reliable source can inherently lead to suboptimal outputs when the final layer remains immature. This research addresses hallucination by proposing an innovative logit extrapolation during inference times coupled with entropy-guided layer selection, which navigates the bottleneck imposed by the maturity assumption of the final layer.
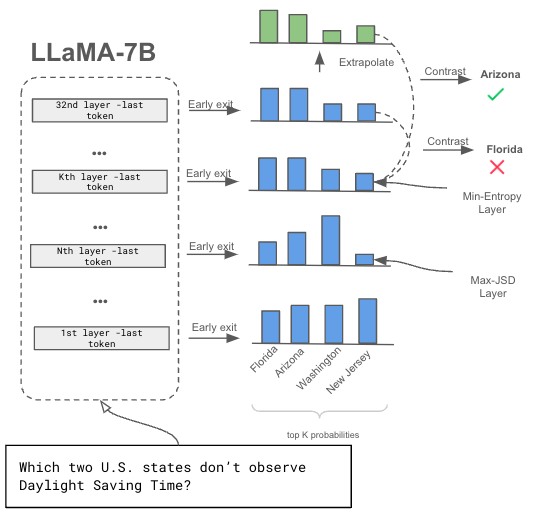
Figure 1: Our proposed extrapolative decoding, final transformer layer is extrapolated to a predetermined layer before contrasting with a lower layer.
Methodology
Dynamic Contrasting Layer Selection
A crucial step involves the dynamic selection of a contrasting layer guided by layer-wise entropy from early exits. This contrast aims to maximize gesture decoding's effect, where a sub-optimal final layer maturity is outstripped by choosing the appropriate layer based on maximum or minimum entropy metrics. Mathematically, the entropy for token-wise distribution within a range of transformer layers can be expressed as:
Hij=−∑Pij(.∣x<t)logpij(.∣x<t)
The optimal contrasting layer l is picked based on:
l={argj∈KmaxEx(Hij)if Q∈Qf argi∈Kmin(Hij)otherwise
This seeks to exploit the hierarchical representation by dynamically selecting the layer with the most profound entropy for either maximal or minimal entropy prompts.
Challenging the notion that a model's final layer is the most mature, the research proposes logit extrapolation to render the distribution more mature. This is achieved by employing simple linear regression to extrapolate critical token probabilities. The extrapolation process involves evaluating the last few layers' probabilities and selecting those with monotonically evolving probabilities suitable for opening further inference layers.
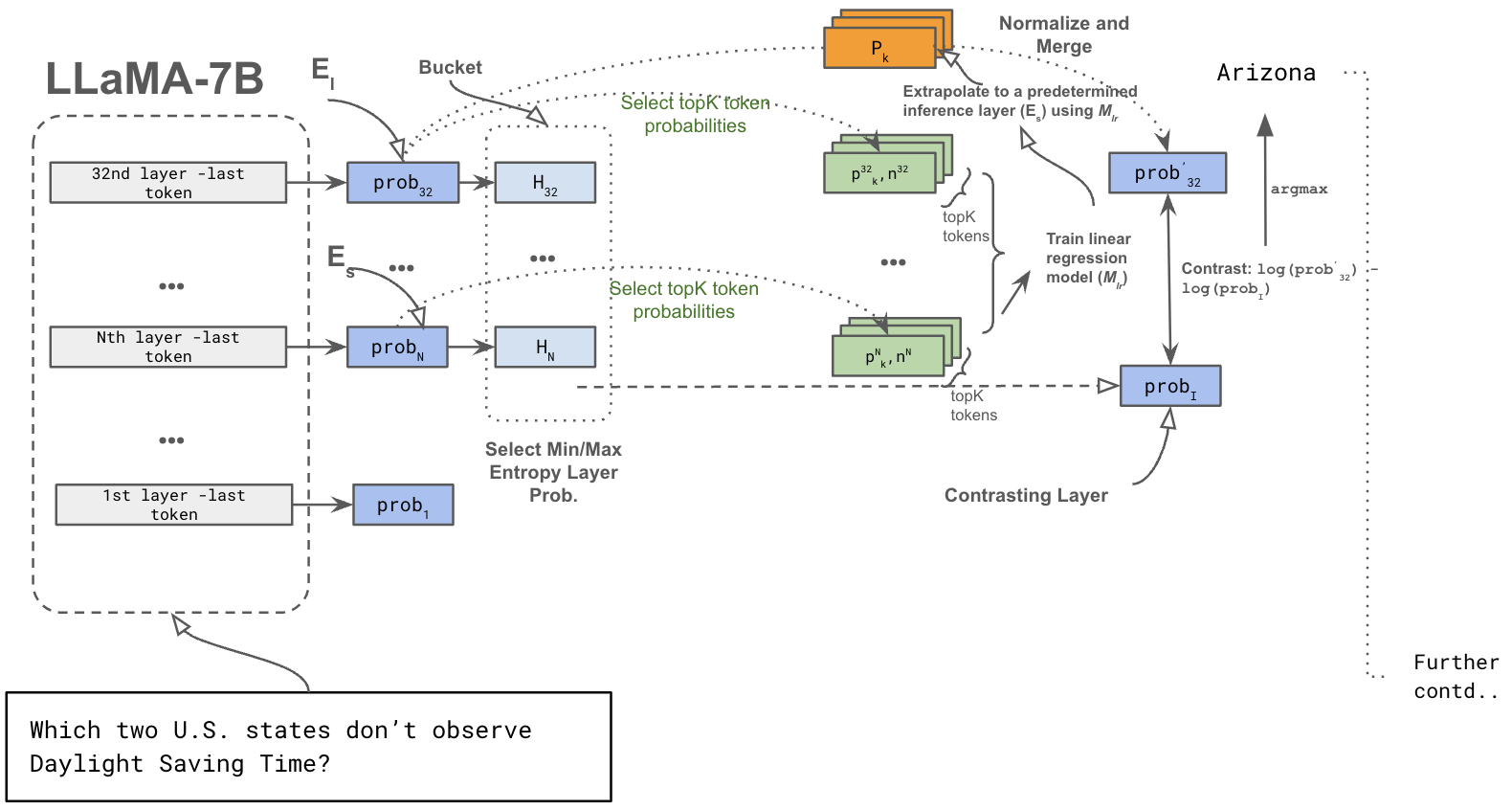
Figure 2: Overview of our entire inference pipeline.
Experimentation
Tasks and Baselines
The proposed methodology has been experimentally validated against multiple benchmarks, including TruthfulQA, TriviaQA, Natural Questions, StrategyQA, and GSM8K (Figure 3). These datasets have been carefully selected to evaluate tasks related both to factuality and chain-of-thought reasoning. The experimental setup utilized NVIDIA V100 GPUs and the Hugging Face Transformers package.
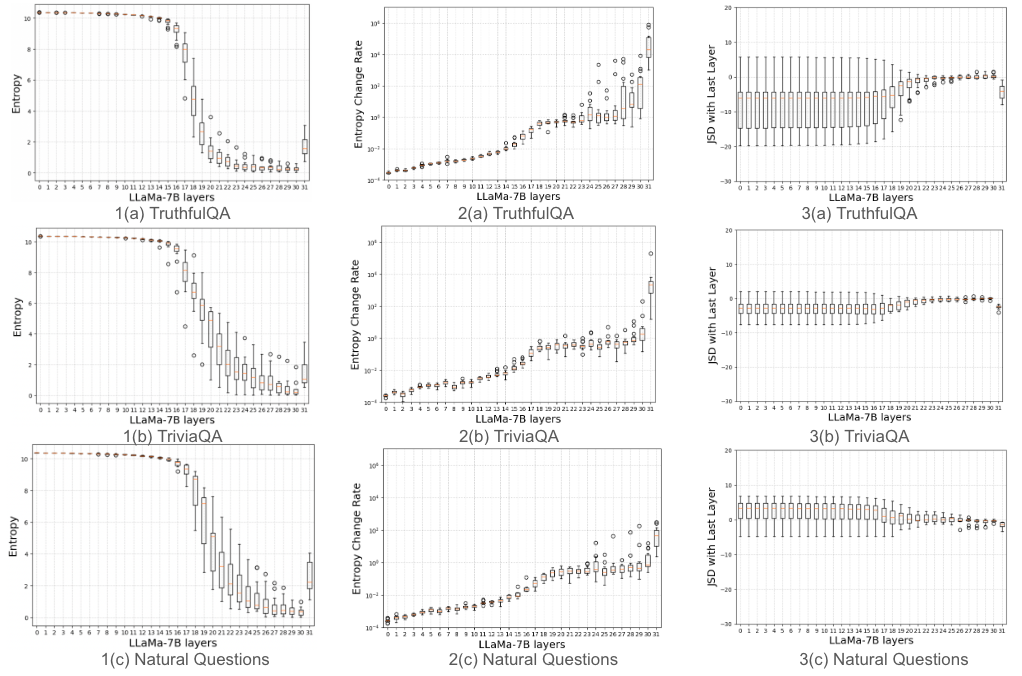
Figure 3: Analysis performed on 100 prompts sampled from TruthfulQA, TriviaQA and Natural Questions. We plot three sets of graphs (1) Entropy(Hi) vs Transformer layers (2) Entropy change rate (3) JSD with the last layer vs Transformer layers.
Results
Multiple Choice Tasks
The proposed Extrapolative Decoding technique was validated through multiple choice datasets, including TruthfulQA-MC and FACTOR-Wiki. The results (Table 1), demonstrated substantial improvements over baseline methods, surpassing the DoLa strategy in multiple model sizes for the LLaMA series models.
Open-Ended Generation Tasks
Open-ended generation tasks, particularly the TruthfulQA dataset, were assessed using GPT3 fine-tuned judges for truthfulness and informativeness. The Entropy Guided Extrapolative approach consistently achieved superior %Truth * Info scores compared to baselines (Table 3), indicating substantial improvements in balancing informativeness with factual correctness while mitigating hallucinations.
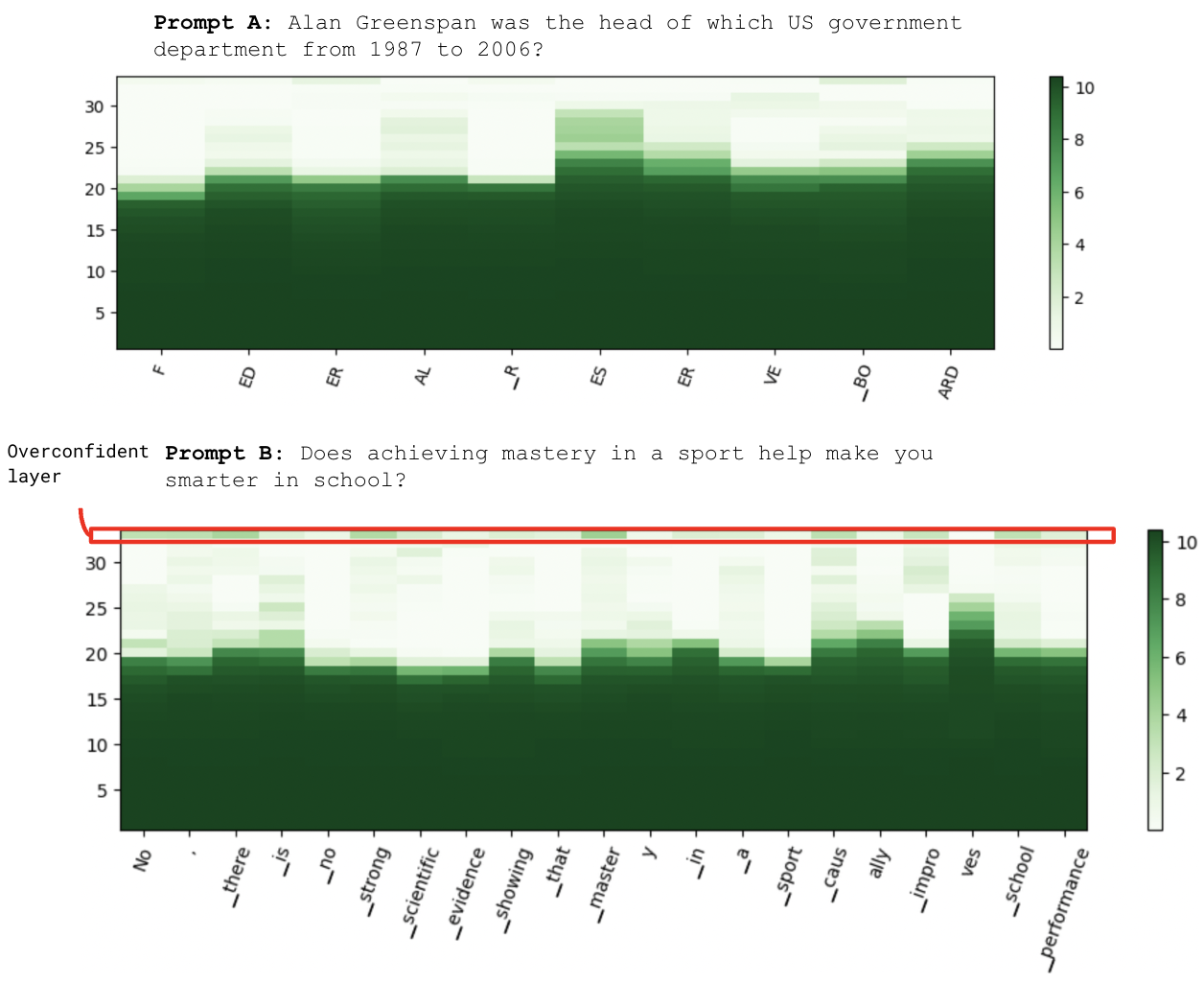
Figure 4: Prompt A: An example of factual prompt Qf and layer-wise entropy for LLaMA 7B. Prompt B: An example of open-ended prompt Qs and layer-wise entropy for LLaMA 7B, with annotated higher overconfident layer.
Chain-of-Thought Reasoning Tasks
On the StrategyQA and GSM8K datasets, the introduced method demonstrated superior performance in comparison to the DoLa baselines (Table 4). The results emphasize the method's capability not only in factual recall but also in leveraging chain-of-thought reasoning, showcasing its broad potential across complex reasoning tasks.
Conclusion
The proposed Entropy Guided Extrapolative Decoding method effectively mitigates hallucinations and enhances factuality in LLMs without imposing additional computational burdens. Through layer-wise entropy guidance and logit extrapolation, it addresses fundamental limitations of traditional methods by allowing greater predictive maturity. Future developments might explore the integration of this methodology with other advanced inference techniques, to further enhance LLMs' capabilities and reduce hallucinations across a broader spectrum of generative tasks.

