- The paper introduces LLM-Seg, a two-stage framework decoupling prompt understanding from image segmentation using a frozen SAM.
- It leverages ChatGPT-4 to generate the LLM-Seg40K dataset, enabling scalable data creation for reasoning segmentation tasks.
- Experimental results show that combining IoU and IoP selection heads in the mask module significantly enhances segmentation accuracy.
LLM-Seg: Bridging Image Segmentation and LLM Reasoning
This paper introduces LLM-Seg, a novel two-stage framework for reasoning segmentation, which combines VLMs and vision foundation models. It also introduces a data generation pipeline leveraging ChatGPT-4 to create a large-scale reasoning segmentation dataset named LLM-Seg40K. The core idea is to decouple prompt understanding and image segmentation. The LLM-Seg framework uses a frozen SAM to generate mask proposals and adopts LLaVA to process user prompts and select relevant masks. The authors emphasize that this two-stage approach avoids fine-tuning the SAM, which could compromise its generality, and simplifies the learning target, leading to faster convergence.
Methodology
The LLM-Seg architecture comprises four main components: a pretrained LLaVA-7B model, SAM, a DINOv2 model, and a mask selection module (Figure 1).
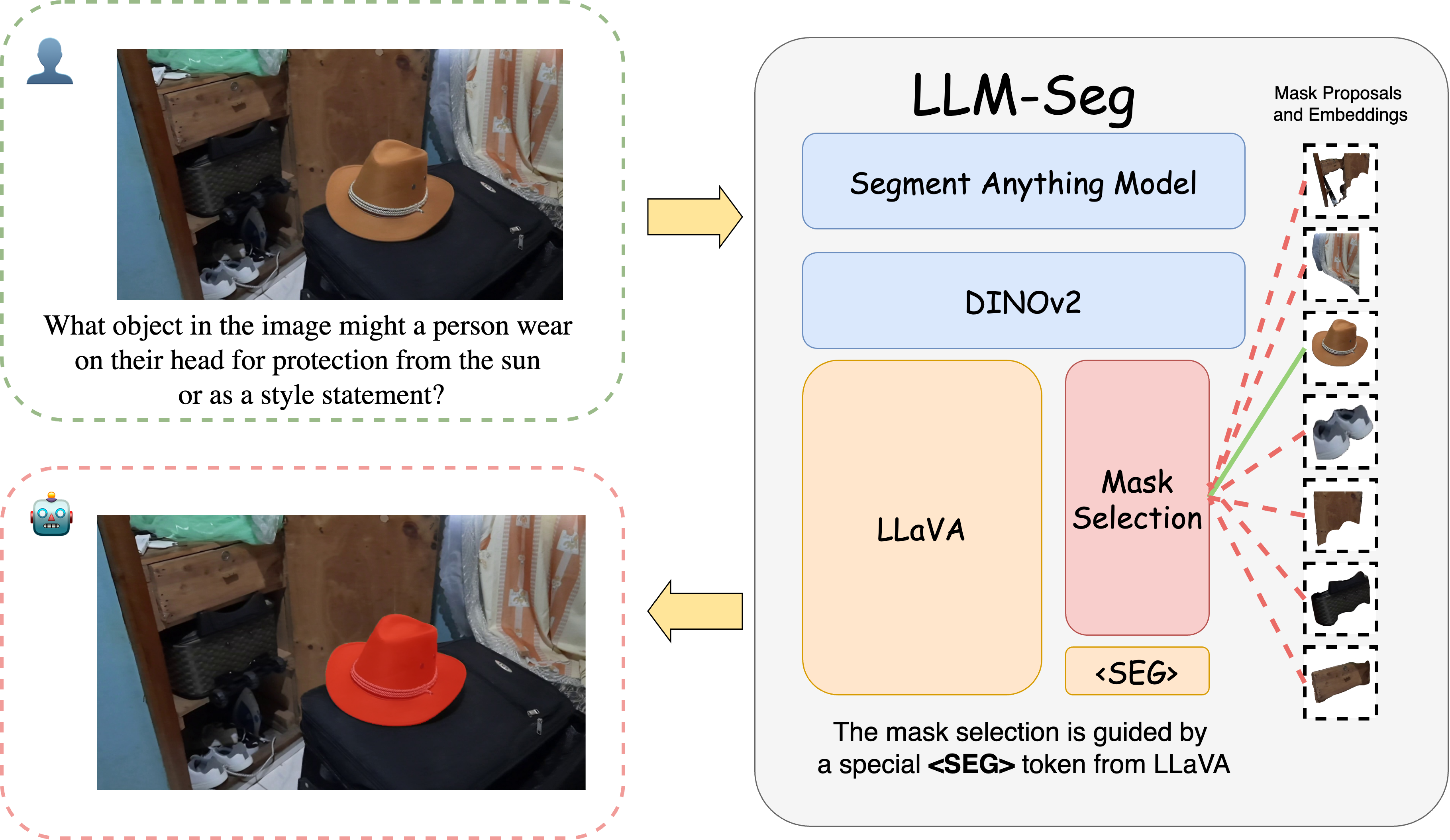
Figure 1: Our LLM-Seg model integrates multiple foundation models including LLaVA, SAM, and DINOv2.
The VLM interprets image content and questions, using a special <SEG> token to represent the segmentation target. SAM generates binary masks, and the mask selection module refines these proposals based on the <SEG> token. Only the mask selection module is fully trainable; SAM and DINOv2 are frozen, and LLaVA is optimized using LoRA. This design choice enables training on a single RTX 3090 GPU.
Mask Proposal Generation
SAM is employed in its Everything Mode to generate mask proposals via point prompts. A uniform sampling of 32x32 points within the image yields 1024 prompts, each generating a mask. Low-IoU masks are filtered, and duplicates are removed using Non-Maximum Suppression. While 1024 point prompts are generated per image, the image encoder is run only once, and the mask decoder processes prompts in batches. The mask proposals are then converted into mask embeddings using mask pooling with image features from the DINOv2 model.
Mask Selection Module
The mask selection module consists of a mask-text fusion module and two selection heads: an IoU head and an IoP head (Figure 2).
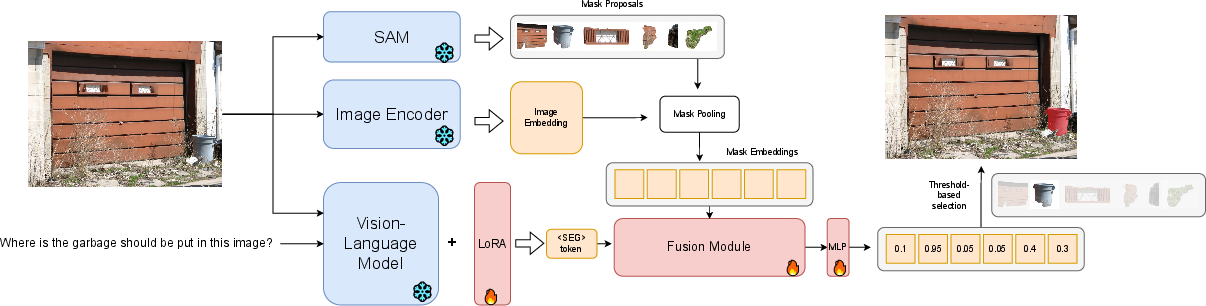
Figure 2: Model Structure of our LLM-Seg.
The fusion module, similar to SAM's mask decoder, utilizes self-attention and cross-attention mechanisms to align mask embeddings and the <SEG> token. The IoU head selects the mask proposal with the highest IoU with the ground truth by computing the similarity between mask embeddings and the <SEG> token, using a temperature factor τ for normalization and KL-Divergence for supervision. The IoP head selects multiple masks based on the Intersection over Prediction (IoP), regressing mask embeddings to their corresponding IoP values using a weighted L2 loss to address class imbalance.
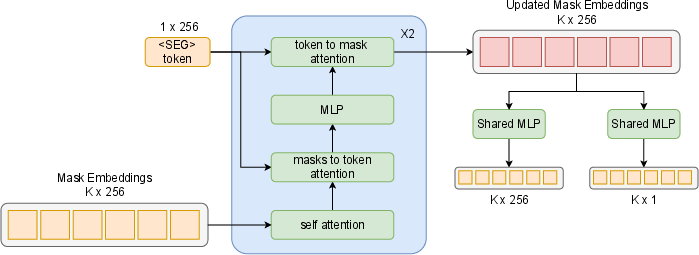
Figure 3: Diagram of the fusion module and two selection heads.
Training Details
The mask selection modules are fully updated during training, while LLaVA-7B is fine-tuned using LoRA, and SAM and DINOv2 are frozen. The training loss combines losses from the IoU and IoP selection heads.
LLM-Seg40K Dataset
The paper addresses the scarcity of datasets for reasoning segmentation by introducing LLM-Seg40K, a large-scale dataset generated using ChatGPT-4. The dataset comprises images paired with questions requiring basic knowledge and reasoning for correct target identification.
Data Generation Pipeline
The data generation pipeline reuses existing image segmentation data from LVIS and EgoObjects. Images from LVIS are sampled based on category complexity, while images from EgoObjects are sampled with more than two categories. SAM is applied to convert bounding box annotations to binary segmentation masks. The LLaVA-v1.5-13B model generates image descriptions, which are then fed into ChatGPT-4 to generate high-quality questions for reasoning segmentation using a carefully designed prompt template and in-context learning (Figure 4).
Experimental Results
The LLM-Seg model was evaluated on the ReasonSeg validation split, using cumulative IoU (cIoU) and generalized IoU (gIoU) as metrics. The paper also introduces normalized cIoU (ncIoU). The LLM-Seg model demonstrates competitive results compared to LISA, achieving higher gIoU scores under various training settings. Ablation studies validate the effectiveness of different modules and mask selection strategies. Specifically, DINOv2 consistently outperformed SAM and CLIP as the vision backbone for generating mask embeddings.

Figure 5: Visual comparison of LLM-Seg with the SOTA methods.
LLM-Seg40K Benchmark
The LLM-Seg40K dataset was used to benchmark the performance of different methods, including GRES, LISA, and LLM-Seg. LLM-Seg achieves SOTA performance under the fully-supervised setting, demonstrating the effectiveness of the proposed data generation pipeline.
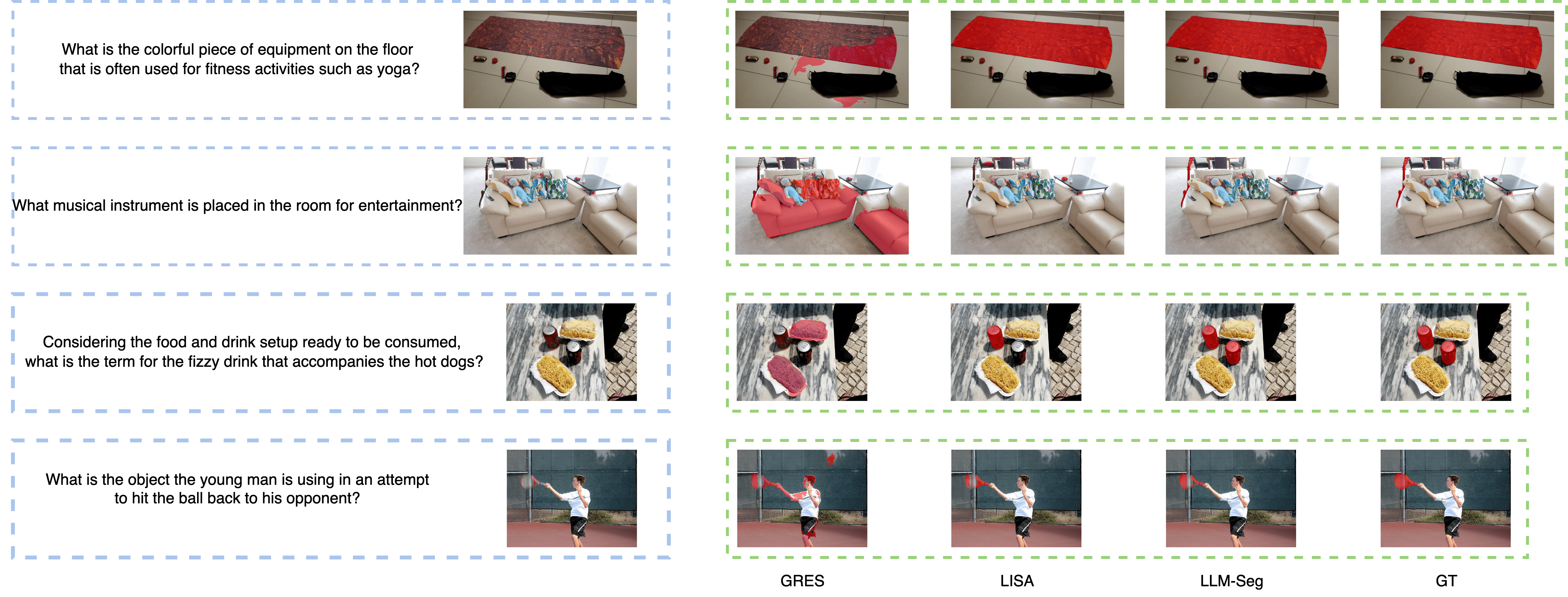
Figure 6: Visual comparison on LLM-Seg40K validation split.
Conclusion
The paper presents LLM-Seg, a two-stage method for reasoning segmentation that decouples reasoning and segmentation. The introduction of the LLM-Seg40K dataset addresses the need for large-scale datasets in this field. The experimental results demonstrate the competitive performance of LLM-Seg and the effectiveness of the proposed data generation pipeline. One limitation of LLM-Seg is the false positive during mask selection.

