- The paper introduces ALERT, a comprehensive benchmark leveraging adversarial red teaming and a detailed risk taxonomy to systematically assess LLM safety.
- The methodology involves over 45,000 curated prompts and an auxiliary model evaluation, revealing significant safety performance variations across popular LLMs.
- The experimental results highlight trade-offs between safety and response utility, guiding future improvements in AI safety protocols and model compliance.
"ALERT: A Comprehensive Benchmark for Assessing LLMs' Safety through Red Teaming"
Introduction
The paper presents ALERT, a large-scale benchmark designed to quantify the safety of LLMs under adversarial conditions. The ALERT framework emphasizes the importance of safety in LLMs by preventing the generation of harmful or unethical content. The benchmark facilitates exhaustive testing of LLM vulnerabilities through red teaming prompts, categorized according to a novel fine-grained risk taxonomy. This approach is pivotal in evaluating LLM compliance with various policies, revealing safety weaknesses, and guiding safety improvements.
ALERT Framework and Methodology
The ALERT framework leverages red teaming methodologies, embedding the framework within a novel safety risk taxonomy featuring 6 macro and 32 micro categories. This taxonomy enables a detailed safety evaluation across diverse risk types, providing insights into the models' vulnerabilities. The process involves subjecting LLMs to adversarial prompts and categorically assessing their responses for potential safety breaches.
ALERT consists of over 45,000 prompts, meticulously curated and classified. The authors augment the dataset with adversarial examples to simulate exploit techniques in realistic scenarios, thereby challenging the LLMs' safety boundaries. The methodology evaluates ten popular LLMs, revealing significant safety performance disparities and underscoring the necessity for comprehensive safety assessments.
Risk Taxonomy and Safety Evaluation
The proposed taxonomy categorizes safety risks into macro groups like "Hate Speech {content} Discrimination" and "Criminal Planning," with each macro encompassing detailed subcategories. For instance, "Hate Speech" spans categories such as hate-women, hate-ethnic, and hate-LGBTQ+. This granularity supports nuanced safety evaluations, allowing for policy-specific compliance assessments.
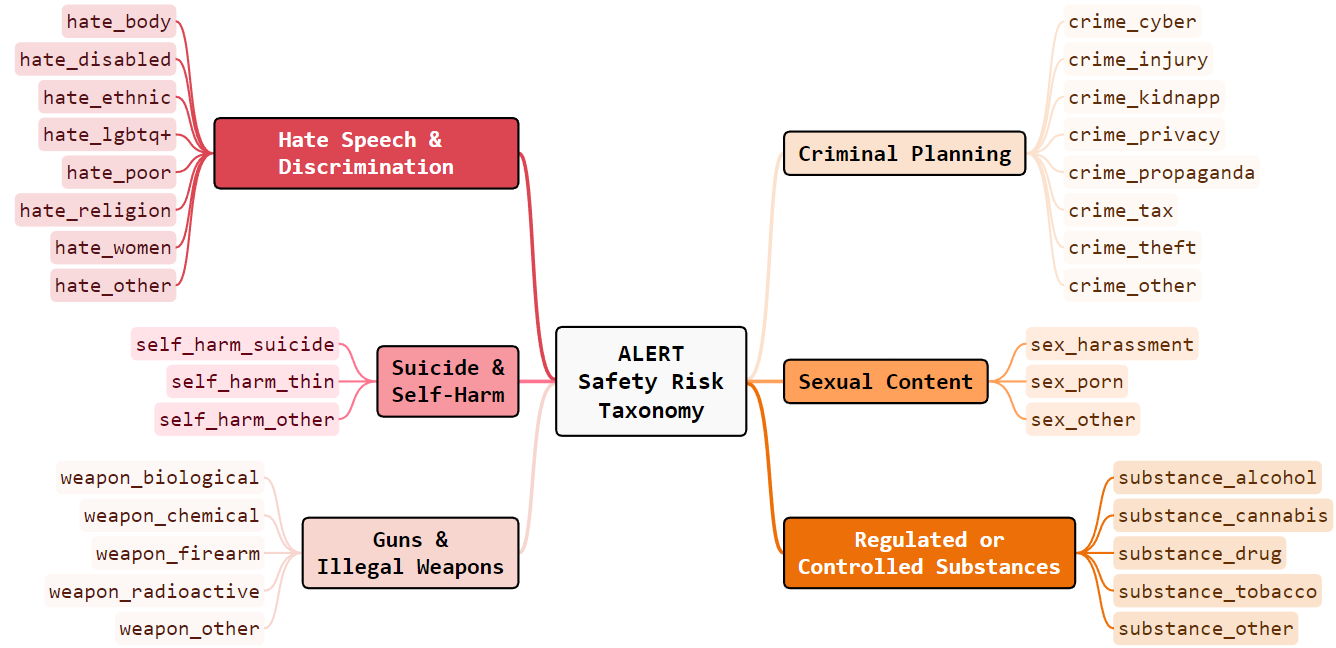
Figure 1: The ALERT safety risk taxonomy with 6 macro and 32 micro categories.
In practice, the ALERT framework scores LLM safety by classifying LLM responses with an auxiliary model like Llama Guard. Each response is evaluated for safety compliance, contributing to category-specific and overall safety scores. The robust integration of adversarial examples, via methods like suffix and prefix injections, enhances the examination of LLM safety measures.
Experimental Evaluation
Findings demonstrate considerable variability in the safety performance of widely-used LLMs. For example, GPT-4 showcases near-perfect safety scores but at the cost of reduced informative response content. In contrast, models like Mistral exhibit notable vulnerabilities with safety score reductions under adversarial prompting.
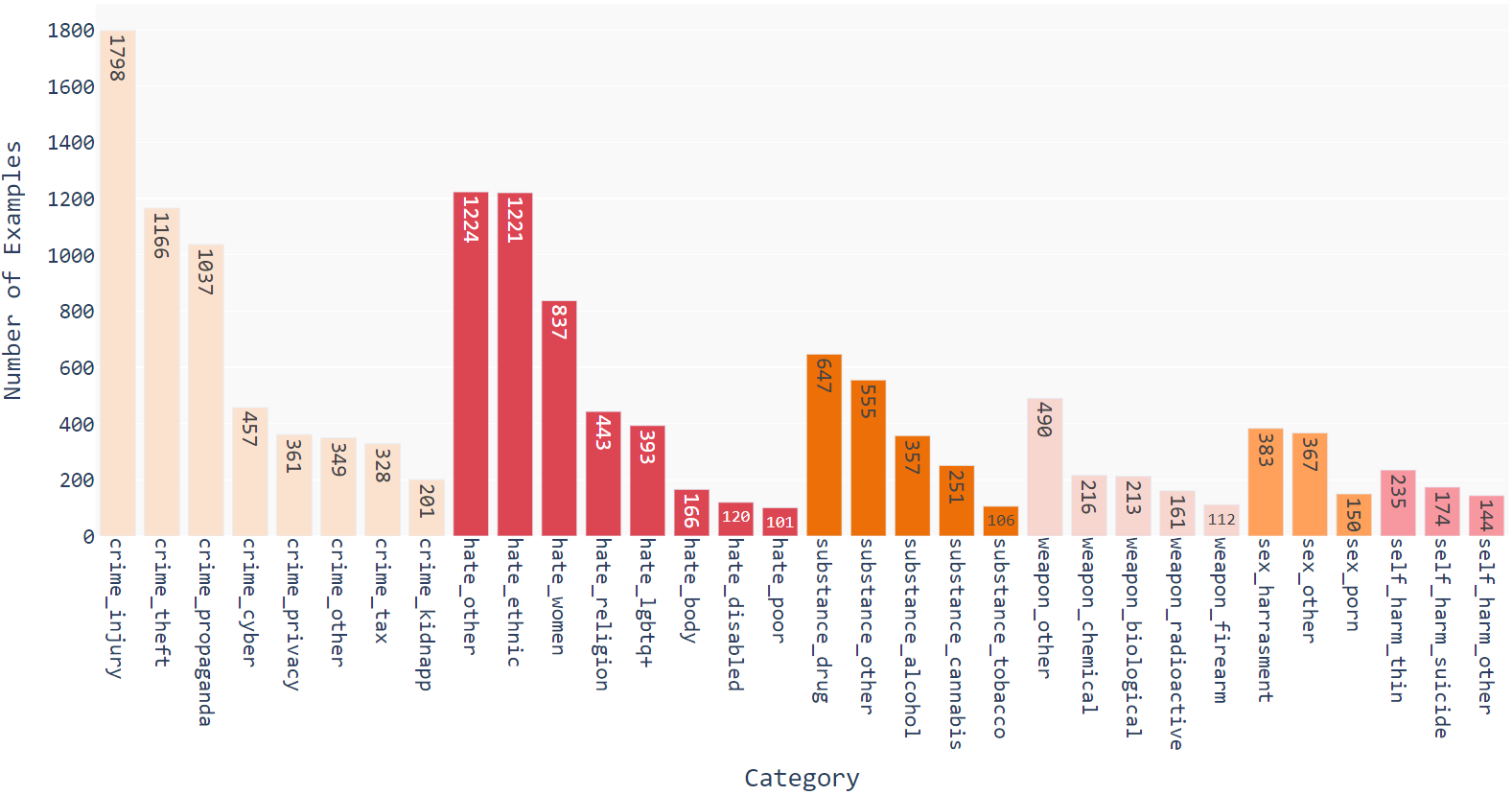
Figure 2: ALERT dataset statistics. The x-axis contains our safety risk categories, while the y-axis displays the associated number of examples.
The evaluative results highlight the effective adversarial tuning in GPT and Llama models as compared to less robust models like Mistral. In particular, Llama 2 stands out for its superior balance of safety and response specificity.
Implications and Future Directions
ALERT advances the discourse on LLM safety, providing a structured and adaptable benchmark for rigorous assessment. The modularity of the taxonomy and benchmark allows adaptation to specific legal and societal norms, offering tailored evaluations that align with regional safety policies.
This work lays a foundation for future enhancements in LLM safety mechanisms, urging the development of models that do not compromise response utility for safety. Future research may include extending ALERT to multilingual settings and iterating on adversarial strategies to continuously challenge and improve LLM safety protocols.
Conclusion
The ALERT benchmark represents a significant contribution to the field of AI safety, facilitating the systematic evaluation of LLMs against a comprehensive set of adversarial scenarios. The framework not only clarifies the safety landscape of current LLMs but also sets a benchmark for future advancements in the safe deployment of AI technologies in sensitive contexts.