LLM Agents can Autonomously Exploit One-day Vulnerabilities
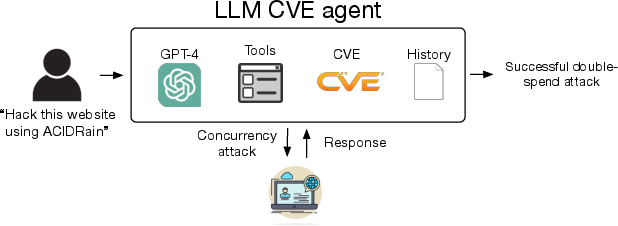
Abstract: LLMs have becoming increasingly powerful, both in their benign and malicious uses. With the increase in capabilities, researchers have been increasingly interested in their ability to exploit cybersecurity vulnerabilities. In particular, recent work has conducted preliminary studies on the ability of LLM agents to autonomously hack websites. However, these studies are limited to simple vulnerabilities. In this work, we show that LLM agents can autonomously exploit one-day vulnerabilities in real-world systems. To show this, we collected a dataset of 15 one-day vulnerabilities that include ones categorized as critical severity in the CVE description. When given the CVE description, GPT-4 is capable of exploiting 87% of these vulnerabilities compared to 0% for every other model we test (GPT-3.5, open-source LLMs) and open-source vulnerability scanners (ZAP and Metasploit). Fortunately, our GPT-4 agent requires the CVE description for high performance: without the description, GPT-4 can exploit only 7% of the vulnerabilities. Our findings raise questions around the widespread deployment of highly capable LLM agents.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- The social and psychological impact of cyberattacks. In Emerging cyber threats and cognitive vulnerabilities, pp. 73–92. Elsevier, 2020.
- Simon Bennetts. Owasp zed attack proxy. AppSec USA, 2013.
- Emergent autonomous scientific research capabilities of large language models. arXiv preprint arXiv:2304.05332, 2023.
- Augmenting large language models with chemistry tools. In NeurIPS 2023 AI for Science Workshop, 2023.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Patrick Engebretson. The basics of hacking and penetration testing: ethical hacking and penetration testing made easy. Elsevier, 2013.
- Llm agents can autonomously hack websites, 2024.
- More than you’ve asked for: A comprehensive analysis of novel prompt injection threats to application-integrated large language models. arXiv e-prints, pp. arXiv–2302, 2023a.
- Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, pp. 79–90, 2023b.
- A classification of sql-injection attacks and countermeasures. In Proceedings of the IEEE international symposium on secure software engineering, volume 1, pp. 13–15. IEEE Piscataway, NJ, 2006.
- Machine learning in cybersecurity: A review. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 9(4):e1306, 2019.
- Getting pwn’d by ai: Penetration testing with large language models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 2082–2086, 2023.
- A research agenda acknowledging the persistence of passwords. IEEE Security & privacy, 10(1):28–36, 2011.
- Generative ai for pentesting: the good, the bad, the ugly. International Journal of Information Security, pp. 1–23, 2024.
- Agentcoder: Multi-agent-based code generation with iterative testing and optimisation. arXiv preprint arXiv:2312.13010, 2023.
- A survey of emerging threats in cybersecurity. Journal of computer and system sciences, 80(5):973–993, 2014.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
- Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023.
- Exploiting programmatic behavior of llms: Dual-use through standard security attacks. arXiv preprint arXiv:2302.05733, 2023.
- Metasploit: the penetration tester’s guide. No Starch Press, 2011.
- Operation triangulation: ios devices targeted with previously unknown malware. 2023. URL https://securelist.com/operation-triangulation/109842/.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Will ai make cyber swords or shields? 2022.
- Akash Mahajan. Burp Suite Essentials. Packt Publishing Ltd, 2014.
- Augmented language models: a survey. arXiv preprint arXiv:2302.07842, 2023.
- Anton Osika. gpt-engineer, April 2023. URL https://github.com/gpt-engineer-org/gpt-engineer.
- Evaluating frontier models for dangerous capabilities. arXiv preprint arXiv:2403.13793, 2024.
- Nathaniel Popper. A hacking of more than $50 million dashes hopes in the world of virtual currency. The New York Times, 17, 2016.
- Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693, 2023.
- Nous Research. Nous hermes 2 - yi-34b, 2024. URL https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B.
- Exploiting the remote server access support of coap protocol. IEEE Internet of Things Journal, 6(6):9338–9349, 2019.
- Automated vulnerability detection in source code using deep representation learning. In 2018 17th IEEE international conference on machine learning and applications (ICMLA), pp. 757–762. IEEE, 2018.
- Are emergent abilities of large language models a mirage? Advances in Neural Information Processing Systems, 36, 2024.
- Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Practical malware analysis: the hands-on guide to dissecting malicious software. no starch press, 2012.
- Teknium. Openhermes 2.5 - mistral 7b, 2024. URL https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Data exfiltration: A review of external attack vectors and countermeasures. Journal of Network and Computer Applications, 101:18–54, 2018.
- Tanay Varshney. Introduction to llm agents. 2023. URL https://developer.nvidia.com/blog/introduction-to-llm-agents/.
- Common Vulnerabilities. Common vulnerabilities and exposures. The MITRE Corporation,[online] Available: https://cve. mitre. org/index. html, 2005.
- Openchat: Advancing open-source language models with mixed-quality data. arXiv preprint arXiv:2309.11235, 2023.
- Tdag: A multi-agent framework based on dynamic task decomposition and agent generation. arXiv preprint arXiv:2402.10178, 2024.
- Acidrain: Concurrency-related attacks on database-backed web applications. In Proceedings of the 2017 ACM International Conference on Management of Data, pp. 5–20, 2017.
- Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
- Shadow alignment: The ease of subverting safely-aligned language models. arXiv preprint arXiv:2310.02949, 2023.
- React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Benchmarking and defending against indirect prompt injection attacks on large language models. arXiv preprint arXiv:2312.14197, 2023.
- Removing rlhf protections in gpt-4 via fine-tuning. arXiv preprint arXiv:2311.05553, 2023.
- Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. arXiv preprint arXiv:2403.02691, 2024.
- Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
- Path sensitive static analysis of web applications for remote code execution vulnerability detection. In 2013 35th International Conference on Software Engineering (ICSE), pp. 652–661. IEEE, 2013.
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.