- The paper introduces a novel approach using discrete speech tokens that achieved top TTS performance with high UTMOS scores and the lowest bitrate.
- The paper integrates semantic and acoustic tokens via advanced architectures including a conformer-based encoder and a non-autoregressive pipeline for ASR and SVS.
- The paper demonstrates that tailored token strategies reduce error rates and improve naturalness, offering actionable insights for future speech processing research.
The X-LANCE Technical Report for Interspeech 2024: Speech Processing Using Discrete Speech Unit Challenge
Introduction
The paper details the contributions from the SJTU X-LANCE team to the Interspeech 2024 challenge, focusing on discrete speech tokens, which have gained prominence across several domains, including ASR, TTS, and SVS. The team's systems achieved notable results, particularly in the TTS track, where they topped the leaderboard with high UTMOS scores and achieved the lowest bitrate across all submissions.
TTS Track: The VQTTS System
The challenge in the TTS track required efficient use of discrete tokens to achieve low bitrate while maintaining high naturalness. The team employed FunCodec for discrete tokens and a modified VQTTS pipeline.
Discrete Tokens
Semantic and acoustic tokens were integrated to harness both content and signal reconstruction aspects. Wav2vec2.0 served as the semantic token provider, and FunCodec acted as the acoustic token with a significant reduction in bitrate.
Model Architecture
The acoustic model utilized a conformer-based encoder and a phoneme-level prosody controller, allowing precise prosody modeling and a fixed-step causal VQ decoder. The vocoder incorporated by the team leveraged the CTX-vec2wav vocoder design refined for single-speaker scenarios.
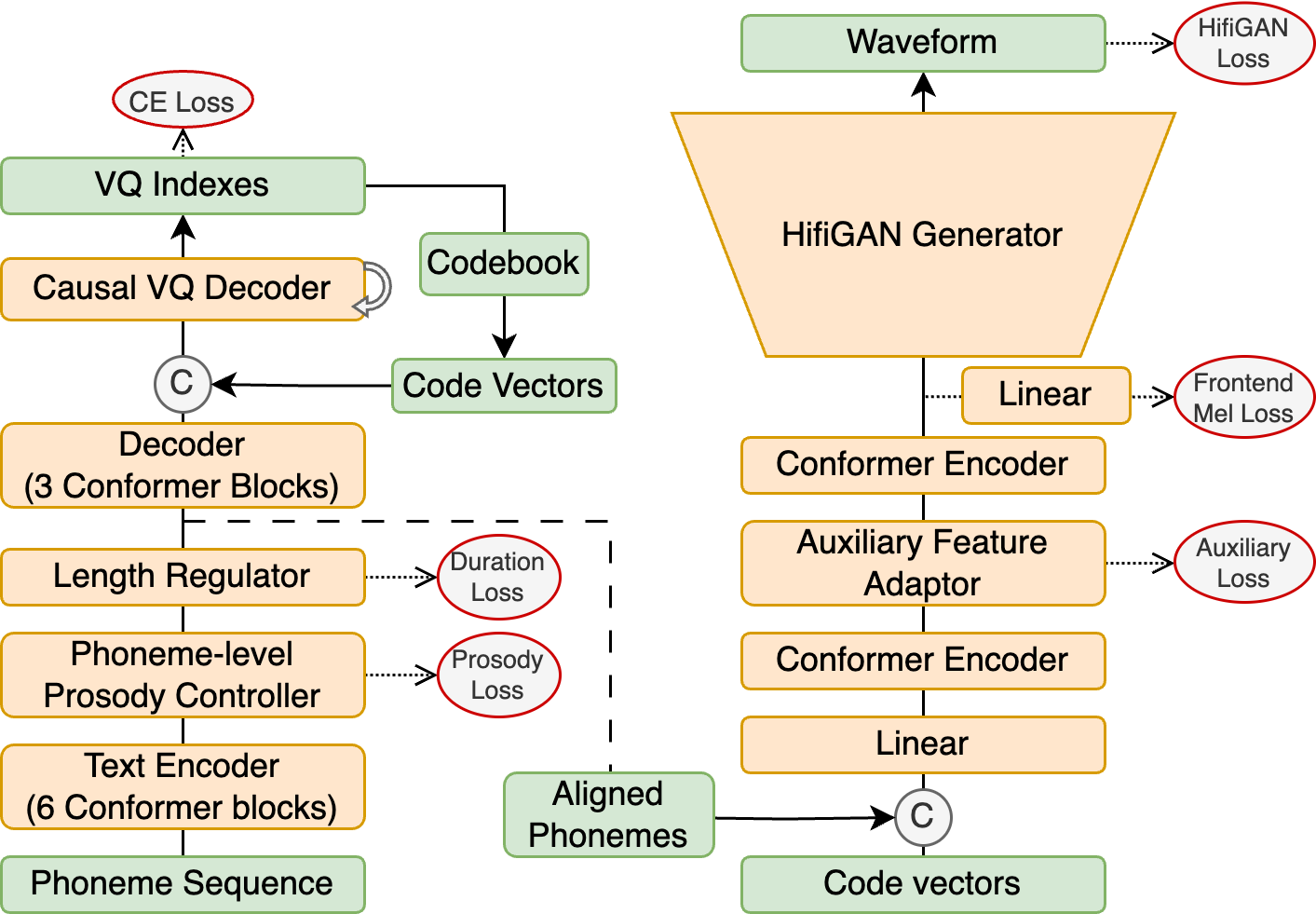
Figure 1: Architecture of the acoustic model (left) and vocoder (right) in the TTS track.
Experimental Results
The integration of aligned phonemes enhanced performance significantly, reducing WER and boosting UTMOS scores effectively in Wav2vec2.0 tokens. The FunCodec token, although less effective in WER during resynthesis, exhibited superior stability with fewer training data inputs.
SVS Track: The DOVSinger System
The SVS track demanded leveraging discrete tokens for singing synthesis with high fidelity. The employed technique centered around Descript Audio Codec (DAC) tokens with a refined VALL-E pipeline.
Discrete Tokens
DAC was chosen for its ability to compress high-fidelity audio effectively, specifically retaining the nuances in the singing voice dataset.
Model Architecture
The modified VALL-E framework involved a purely non-autoregressive inference pipeline, optimized to predict DAC codes across multiple layers with a focus on temporal coherence.
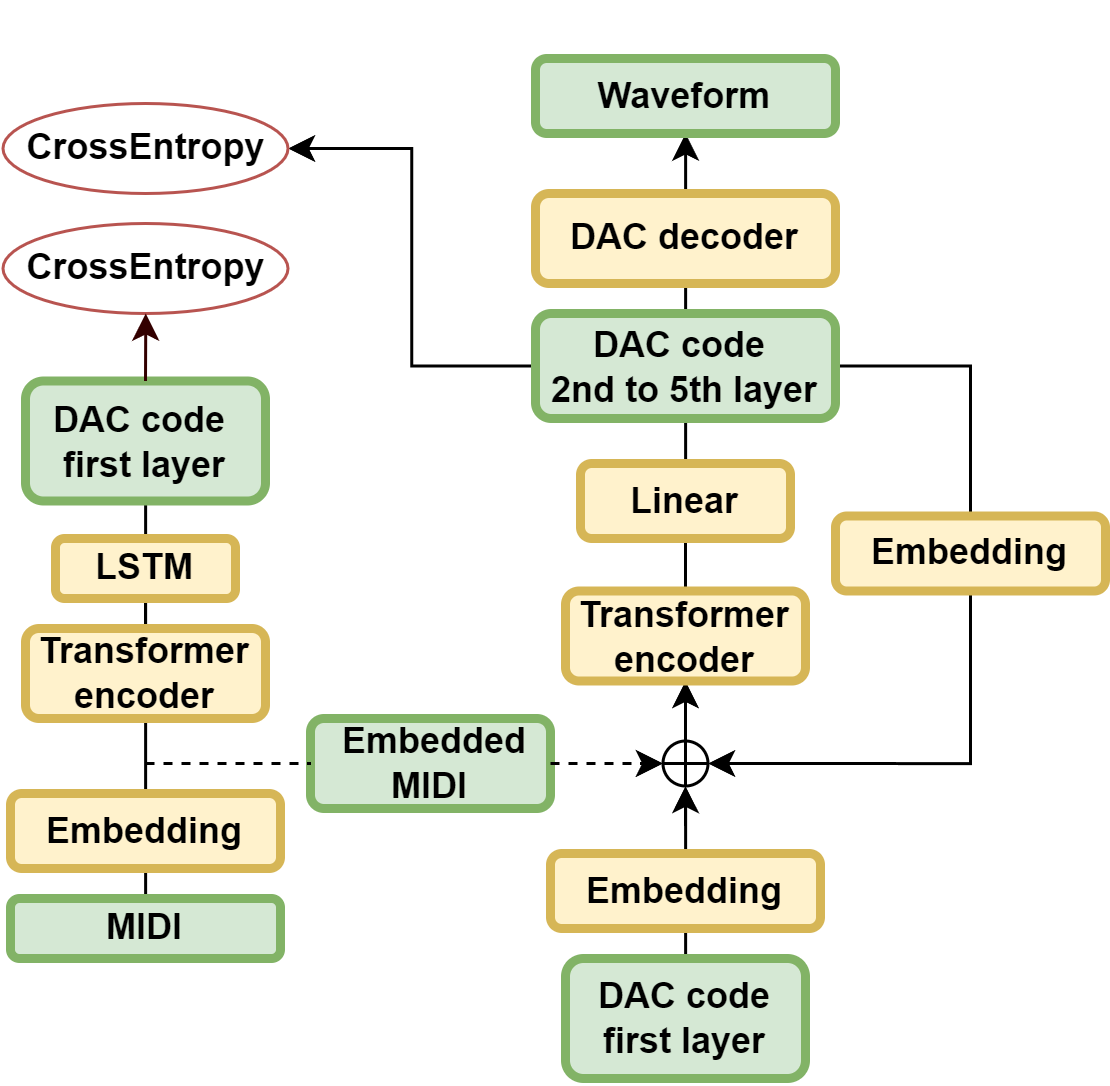
Figure 2: Architecture of the acoustic model (left) and vocoder (right) in the SVS track.
Experimental Results
The DOVSinger resulted in high pitch accuracy at reduced bitrates, although it compromised on perceptual quality due to the limited use of DAC layers in synthesis, resulting in a notable hoarseness in output vocals.
ASR Track
For the ASR track, the focus was on using semantic tokens for recognizing speech at a low bitrate. The WavLM model was pivotal in providing the discrete tokens.
Utilizing WavLM-large and k-means clustering, the team developed an end-to-end ASR system optimized using RNN-T loss and incorporated robust token augmentation techniques.
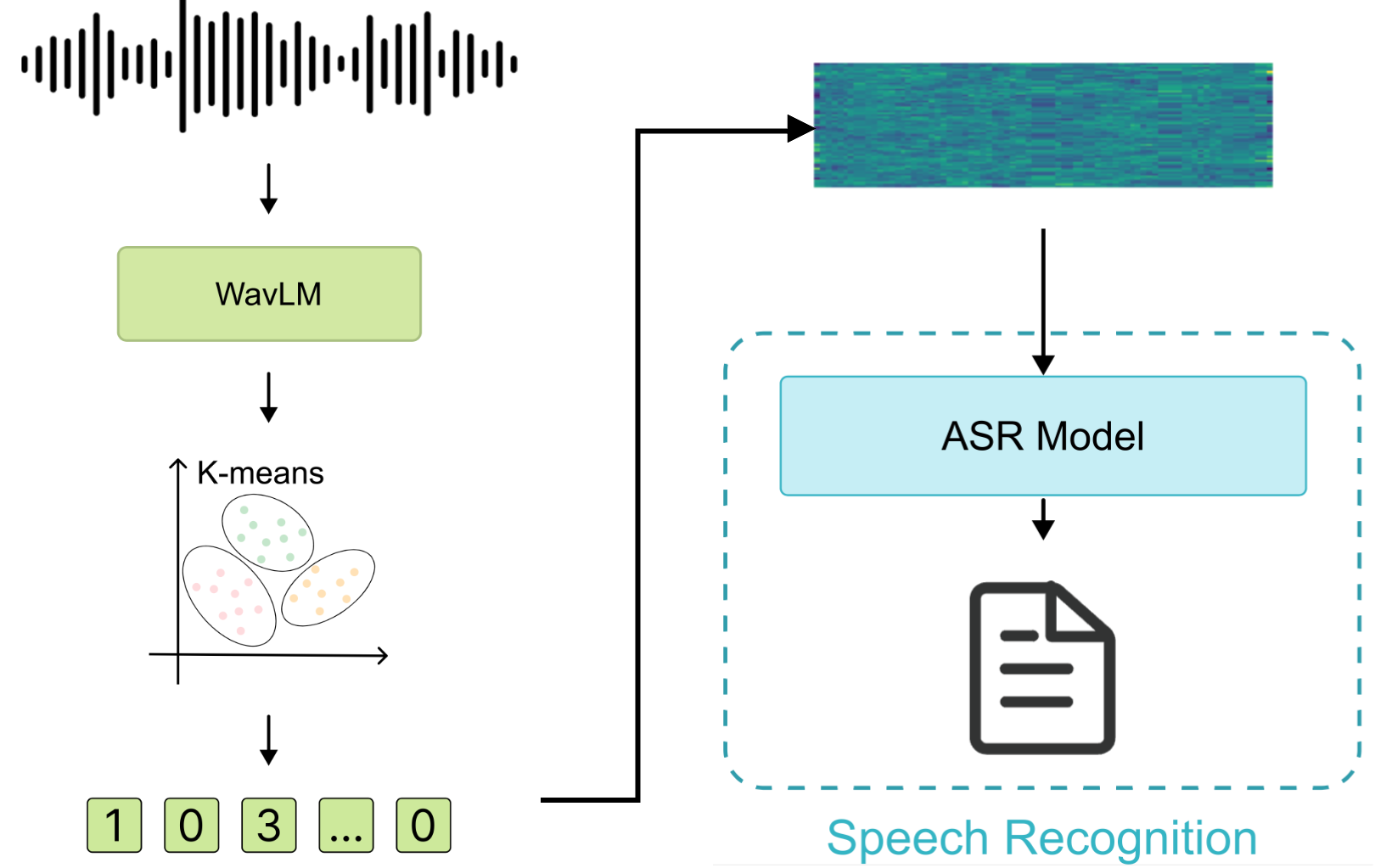
Figure 3: Illustration of the pipeline for speech discrete tokens in the ASR track.
Model Architecture and Training
The selected neural Transducer architecture with a Zipformer encoder allowed for efficient sequence encoding, further refined by a stateless RNN-T framework.
Experimental Results
The system achieved a substantial reduction in CER, evidencing its effectiveness in handling speech recognition tasks, albeit at a relatively higher bitrate than the baseline.
Conclusion
In conclusion, the X-LANCE team's participation in the Interspeech 2024 challenge demonstrated a comprehensive understanding and application of discrete speech tokens across multiple domains. Their systems not only showcased competitive performance metrics but also shed light on effective token usage strategies that may influence future developments in speech processing technologies.

