- The paper demonstrates that VoT prompting significantly improves spatial reasoning in LLMs by eliciting internal 'mind’s eye' visualizations.
- It employs a zero-shot methodology across tasks like natural language navigation and visual tiling, achieving success rates up to 87.1% compared to 57.4%.
- The findings suggest promising applications in robotics and spatial decision-making while outlining directions for further enhancement of visual-spatial models.
Mind's Eye of LLMs: Visualization-of-Thought Elicits Spatial Reasoning in LLMs
Introduction
This paper presents an innovative approach to enhancing spatial reasoning capabilities in LLMs through a concept termed Visualization-of-Thought (VoT) prompting. Despite the remarkable performance of LLMs in various reasoning tasks, their spatial reasoning abilities have not been extensively explored. The VoT method takes inspiration from the human cognitive function known as the "Mind's Eye," which involves creating mental images for spatial awareness and decision-making (Figure 1).

Figure 1: Humans can enhance their spatial awareness and inform decisions by creating mental images during the spatial reasoning process. Similarly, LLMs can create internal mental images. We propose the VoT prompting to elicit the "mind's eye" of LLMs for spatial reasoning by visualizing their thoughts at each intermediate step.
Methodology
Visualization-of-Thought Prompting
The methodology behind VoT is inspired by the human cognitive process of spatial reasoning, which often involves creating mental images and using them to enhance decision-making. VoT is a zero-shot prompting methodology that enhances the visuospatial capabilities of LLMs by encouraging the generation of internal mental images to guide reasoning tasks in a manner similar to the human mind's visualization process (Figure 2). This approach leverages the inherent ability of LLMs to create mental images informed by text-based prompts, an ability possibly augmented by exposure to text-based visual art and related data during pre-training.







Figure 2: Example of visual tiling with masked polyomino pieces. Variants of those polyomino pieces including rotation and reflection are not shown in this figure.
Experimental Setup
To evaluate the efficacy of VoT, the authors implemented three spatial reasoning tasks: natural language navigation, visual navigation, and visual tiling. These tasks challenge LLMs to demonstrate spatial awareness through interaction with 2D grid world models and assess their capacity for multi-hop reasoning and understanding of geometric shapes and spatial relationships.
Visual Navigation Challenge: A key component of this experiment involves guiding an LLM through a synthetic 2D grid world using visual directions, aiming for a symbolic internal representation of the LLM's reasoning process. This challenge encompasses sub-tasks like route planning and next step prediction, which necessitate the LLM to demonstrate competence in multi-hop spatial reasoning. Figure 3 provides examples of the grid configuration under varying settings of k.






Figure 3: Examples of a navigation map under different settings of k, with emoji of house indicating the starting point, and emoji of office indicating the destination.
Experimental Evaluation
Experimental Setup
In evaluating the VoT strategy, different settings of GPT-4 and an additional multimodal model (GPT-4V) were adopted. Experiments were run under different zero-shot prompting conditions, with varying degrees of instruction specificity on visualization (Table 1).
Results and Analysis
The empirical results (Table 1) reveal that GPT-4 VoT outperforms other models in all tested tasks. There is a marked performance gap between GPT-4 VoT and its counterparts, highlighting the efficacy of VoT in enabling LLMs to perform enhanced spatial reasoning.
This performance difference is attributed to the VoT's capability to prompt LLMs to generate and use visual state tracking, shown in Figure 4. The success rate, particularly in tasks necessitating spatial tracking, shows a substantial rise with explicit VoT prompts compared to Chain-of-Thought (CoT) prompts or when visualization is disabled.

Figure 4: Common behaviors of VoT and CoT prompting in visual tiling task, with the overall track rate of 87.1\% and 57.4\% respectively.
Case Study on Visualization and Thought Processes
The analysis demonstrates that LLMs can inherently generate visual state tracking in most tasks but are prompted more effectively to do so using VoT. Notably, the ability to process multi-modal inputs in a grounded and sequential manner significantly enhances reasoning accuracy, especially in complex spatial reasoning tasks.
Interestingly, VoT prompting does not necessarily outperform when tasks are solvable through existing logical reasoning without the need for visualization, as evidenced in the natural language navigation task where removing "use visualization" resulted in decreased performance (Table 1; Figure 5).

Figure 5: Route planning task is sensitive to prompts. After deleting the word "reasoning" from the VoT prompt, final answer and state is derived without conditioning on state visualization in many cases.
Furthermore, the experiments suggest that LLMs exhibit behaviors resembling a human-like mental simulation when conducting spatial reasoning, emphasizing a level of innate visual-spatial capacity (Figures 11 and 12 show detailed outputs for the natural language navigation task).
Figure 4: Common behaviors of VoT and CoT prompting in visual tiling task, with the overall track rate of 87.1\% and 57.4\% respectively.
Figure 5: Route planning task is sensitive to prompts. After deleting the word "reasoning" from the VoT prompt, final answer and state is derived without conditioning on state visualization in many cases.
Implementation and Experimentation
The paper details a series of synthetic tasks: (i) natural language navigation, (ii) visual navigation, and (iii) visual tiling, each designed to challenge and measure spatial reasoning abilities. The visual tasks utilized a 2D grid environment to simulate real-world navigation and geometric arrangements, as depicted in conveyed imagery (Figure 3). Implementation of VoT involved enabling LLMs to visually track mental images and integrate them into textual reasoning processes, drawing parallels with the human mind's eye mechanism.
The synthesis of the dataset focused on different complexities and input formats, presenting a comprehensive ground for assessing spatial reasoning. The authors evaluated VoT across various tasks and models, employing metrics such as accuracy and success rate (Table 2). Exemplars of VoT prompting are provided in Figure 6, where reasoning traces and visualizations are generated in a coherent, interleaved manner.
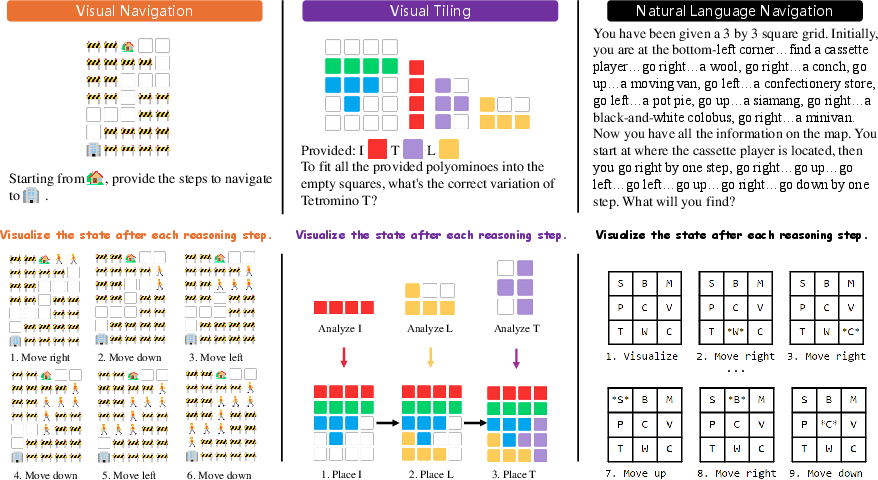
Figure 6: Examples of VoT prompting in three tasks, where LLM generates reasoning traces and visualizations in an interleaved manner to track the state over time.
Results and Analysis
The empirical results unequivocally demonstrate the efficacy of VoT prompting. GPT-4 VoT significantly outperformed other settings, achieving substantial gains across all evaluated tasks (Table 1). In the natural language navigation task, VoT led GPT-4 to surpass GPT-4 w/o Viz by 27% in the success rate measure. The exploration also uncovers that VoT prompt design sensitizes LLMs to visualization, enabling them to check the next steps before generating the final answer, unlike purely verbal reasoning (Figure 4).
The experiments on the visual tasks, such as visual navigation and visual tiling (Figure 3 and Figure 2), show that the VoT approach extends LLMs' ability to simulate and solve multi-hops spatial problems. The use of symbolic visual representations alongside reasoning traces allowed GPT-4 to more accurately solve the tasks. However, the study also uncovers issues with inconsistent visualizations and limitations in spatial understanding.
Implications and Future Directions
The findings from this paper hold significant implications for the future development of LLMs and multimodal models. The visualization-of-thought process proposes a new paradigm for enhancing spatial reasoning in AI, offering pathways for integrating more sophisticated mental image generation into MLLMs. This could significantly benefit robotics, navigation systems, and even AI-driven decision-making in spatially complex domains.
The VoT prompting offers a distinct method for leveraging visualization in AI, moving beyond text or logical form representation. Future work could investigate further into the seamless coupling of real-world spatial datasets, automatic data augmentation, and advanced visuospatial models to ameliorate the mind's eye in LLMs, subsequently advancing their inherent reasoning capabilities.
Conclusion
The paper presents Visualization-of-Thought (VoT) prompting, a novel approach to enhancing the spatial reasoning abilities of LLMs. Modeled after the human Mind’s Eye cognitive function, VoT facilitates the visualization of intermediate reasoning processes, notably improving performance on spatial reasoning tasks. The research highlights the potential of implementing mental image manipulation akin to the human mind's eye to develop more robust and spatially adept AI systems. Future work should focus on broadened 3D semantic representation and diversified task domains, further advancing AI's cognitive capabilities.