- The paper introduces the R²T-LLM framework, reformulating traffic flow prediction as a next-token generative task using multi-modal urban data.
- It leverages advanced prompt engineering and low-rank adaptation of Llama2-7B-chat to produce both precise forecasts and natural language explanations.
- The experiments show superior performance and homogeneity over deep-learning baselines, demonstrating improved robustness and accountability in urban forecasting.
Responsible and Reliable Traffic Flow Prediction with LLMs (R²T-LLM)
Introduction
The paper introduces R²T-LLM, a framework for traffic flow prediction based on LLMs, focusing on both accuracy and responsible explainability. The methodology stands in contrast to deep-learning graph-based or temporal architectures, seeking to address the complexity of spatio-temporal dependencies and the opacity of deep neural networks in transportation forecasting. By reformulating traffic prediction as a generative language modeling task, R²T-LLM leverages multi-modal urban traffic data—comprising sensor flows, Points-of-Interest (PoIs), weather attributes, and holidays—into a unified text-based representation, enabling LLMs to learn both forecasting and explanatory reasoning.
R²T-LLM reframes traffic forecasting as next-token prediction. Historical traffic flow values and external context (weather, date, PoI distributions, holidays) are tokenized and input as structured prompts. The autoregressive LLM predicts future traffic states and simultaneously generates textual rationales.
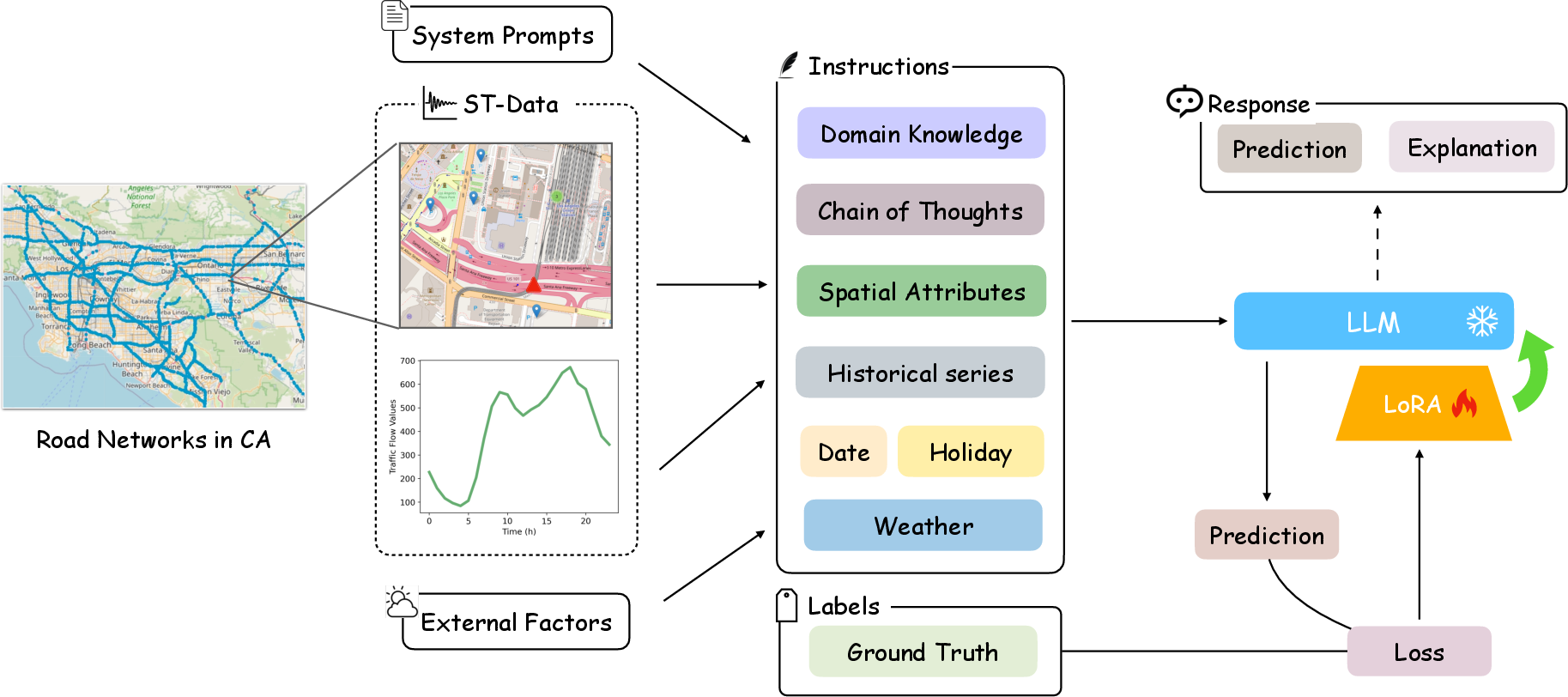
Figure 1: R²T-LLM framework: Conversion of multi-modal traffic flow data into textual prompts enables the LLM to infer latent spatio-temporal relationships for prediction and explanation.
The approach exploits the compositionality of language modeling for structured urban concepts, allowing for context-aware forecasting, awareness of event periodicity, and incorporation of externalities without bespoke model adaptation. The formalization captures:
XT:T+H,Ii=Pθ(XT−H−1:T−1,Ei)
where XT:T+H are future flow values, Ei are externalities, and Ii is the explanation; the mapping is learned by the LLM through language token manipulation.
Prompt Engineering and Multi-Modal Integration
A critical component is prompt engineering. Prompts for R²T-LLM consist of:
- System Prompts: Domain role specification and few-shot examples, embedding context expertise into the generative process.
- Chain of Thought (CoT): Sequential questioning to stimulate rational inference in the LLM, focusing on spatio-temporal factors.
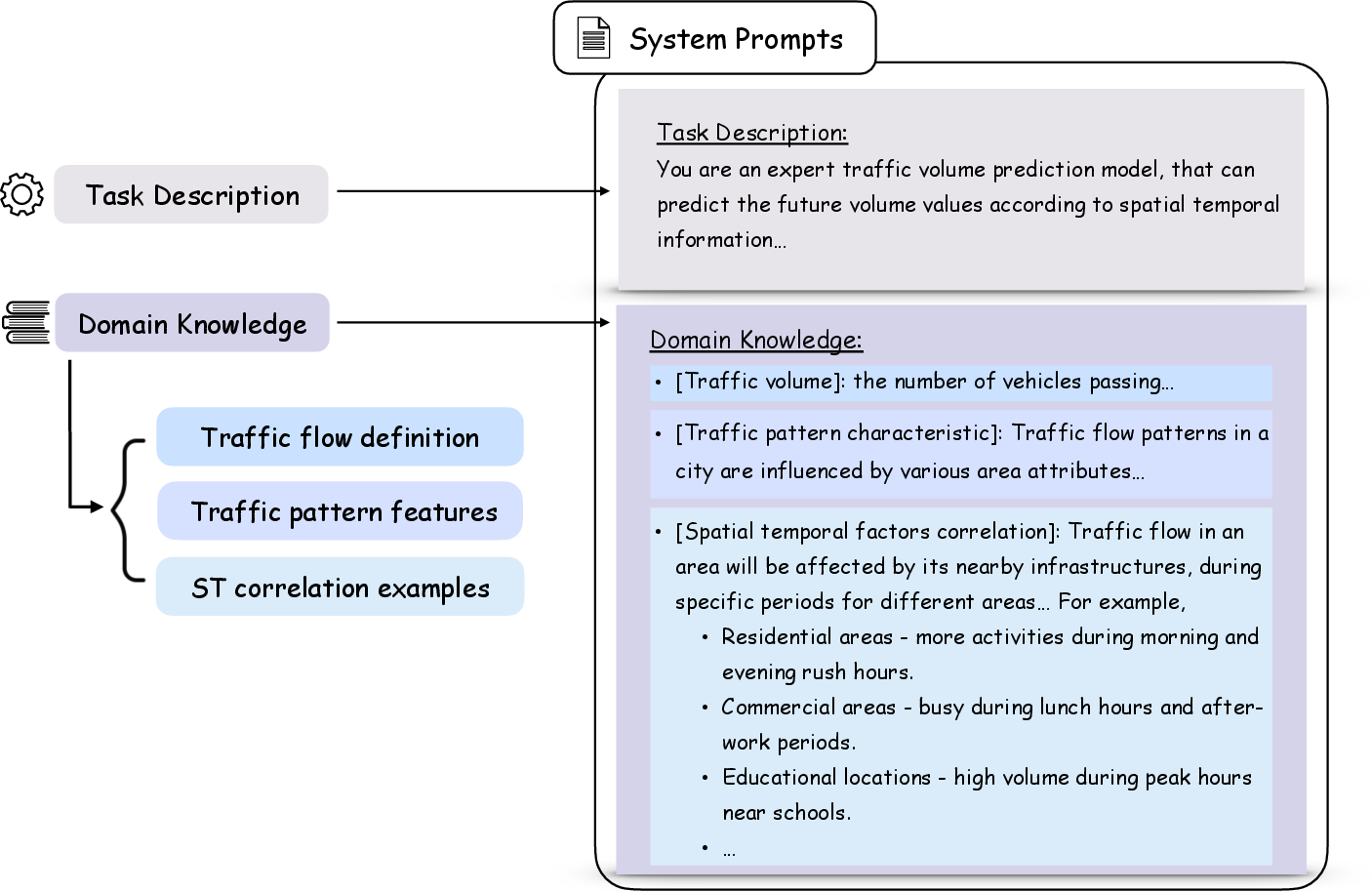
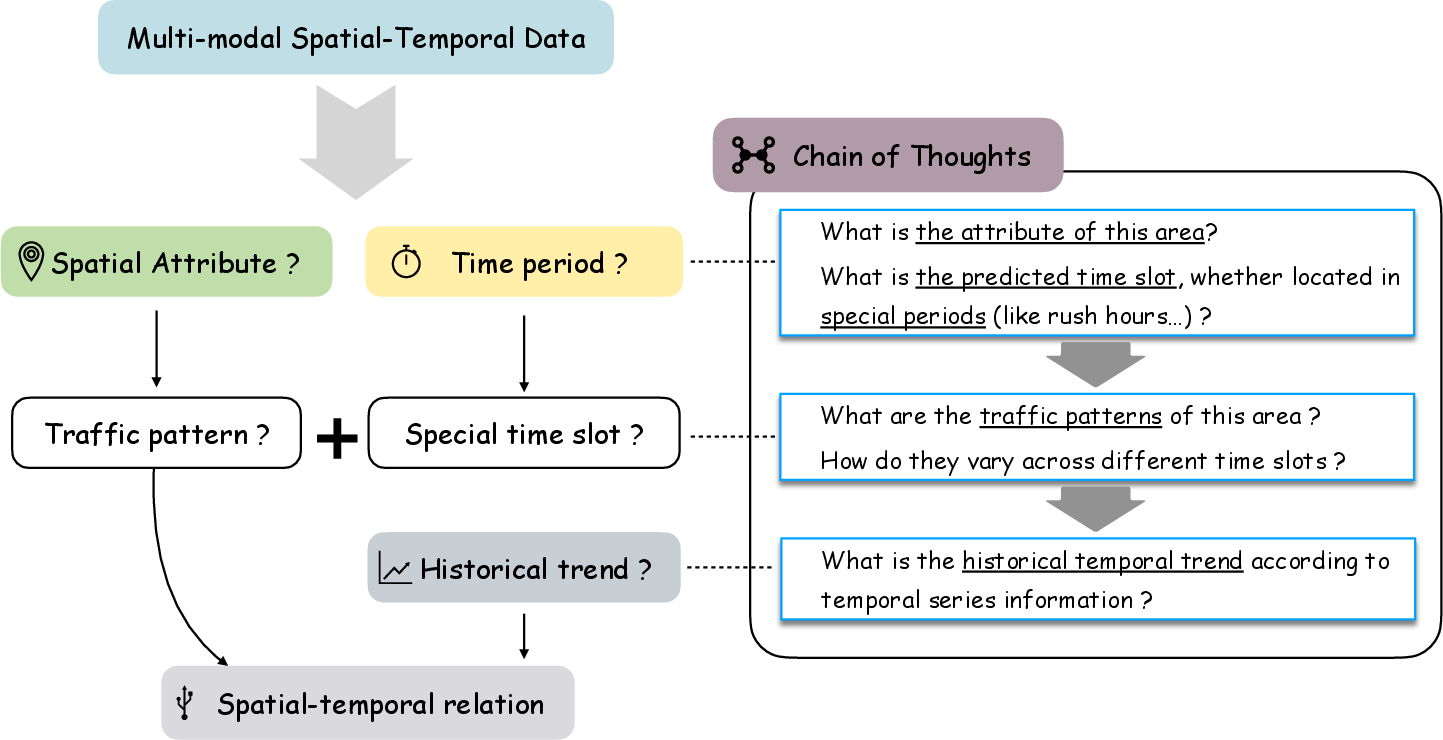
Figure 2: Construction of system prompts and chain-of-thoughts, embedding domain knowledge and reasoning steps into the input context.
Multi-modal features are unified as text. PoIs are clustered by spatial proximity and summarized categorically; historical flows are numerically transcribed; weather and holidays are textually encoded for semantic parsing.
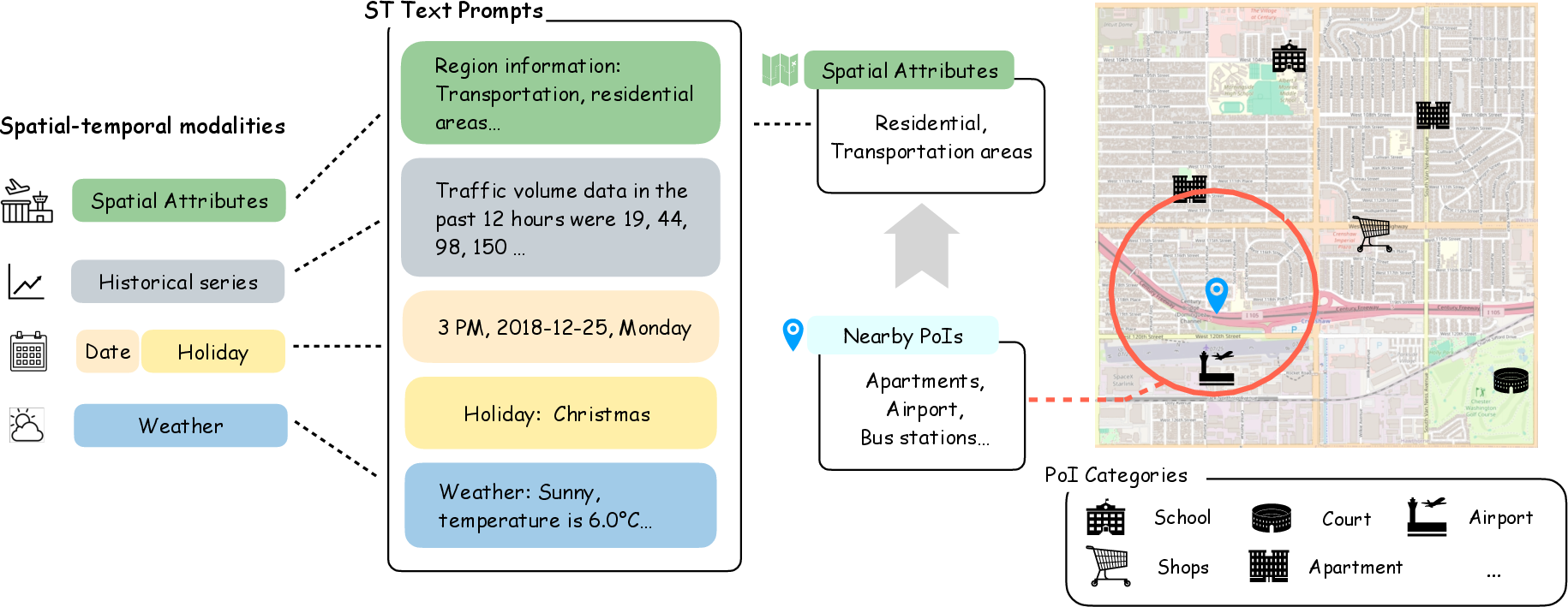
Figure 3: Spatial-temporal text prompt construction, where sensor, regional attributes, historical flow series, and external factors are represented in consistent textual form for input to the LLM.
This design aligns the model’s training context with human-curated traffic reasoning, permitting robust generalization and enhanced explainability.
Supervised Fine-Tuning and Model Adaptation
R²T-LLM is fine-tuned atop Llama2-7B-chat via the LoRA approach, exploiting low-rank adaptation for efficient parameter tuning and resource conservation. Only a subset of attention weights are updated:
W′=W+BA
where W are frozen, A and B are learned low-rank adapters. The objective is next-token prediction, framed as language modeling over traffic data and explanation:
LFT(D)=−j=1∑nlogP(Yj∣Y1:j−1;X1:n)
This conditioning allows R²T-LLM to produce both numerical forecasts and responsible explanations in a conversational format.
Experimental Results
Empirical evaluation on the CATraffic dataset demonstrates that R²T-LLM achieves superior performance relative to classical and deep learning baselines (LSTM, DCRNN, AGCRN, STGCN, GWNET, ASTGCN, STTN, STGODE, DSTAGNN). Noteworthy, R²T-LLM consistently outperforms all baselines across MAE and MAPE metrics over multiple horizons.
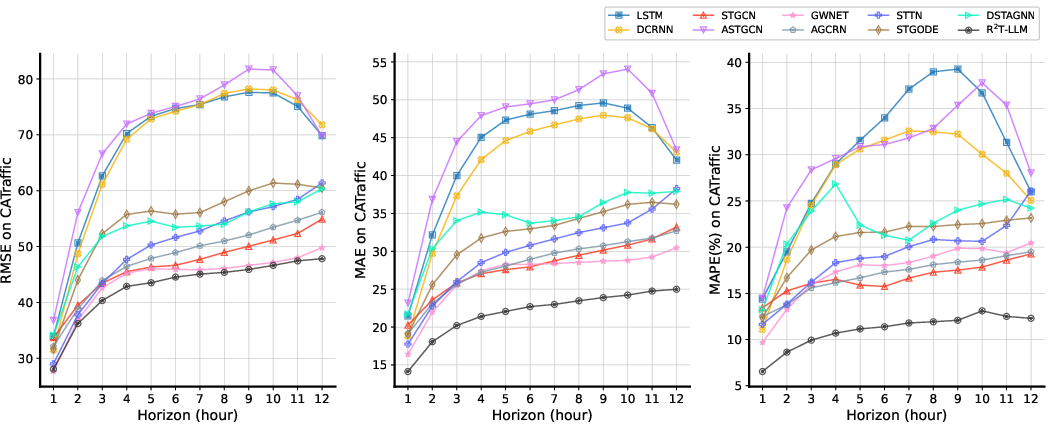
Figure 4: Time-step prediction comparison, showing R²T-LLM’s robustness over longer horizons versus deep learning baselines on the CATraffic dataset.
Spatial and Temporal Homogeneity
Analysis of spatial and temporal error distributions reveals R²T-LLM maintains strong homogeneity across different locations and daily cycles, outperforming baselines especially in regions with complex urban topology and in periods with volatile flow patterns.
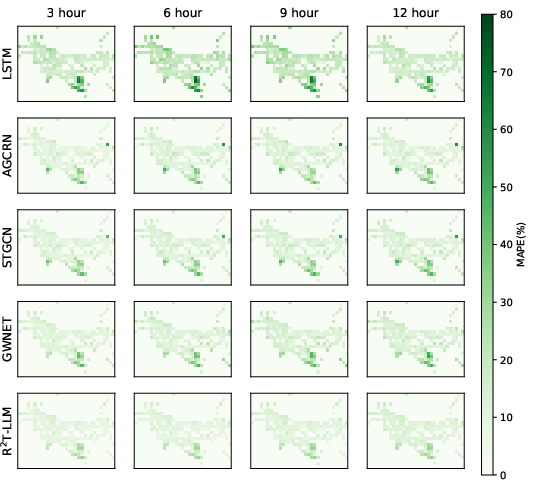
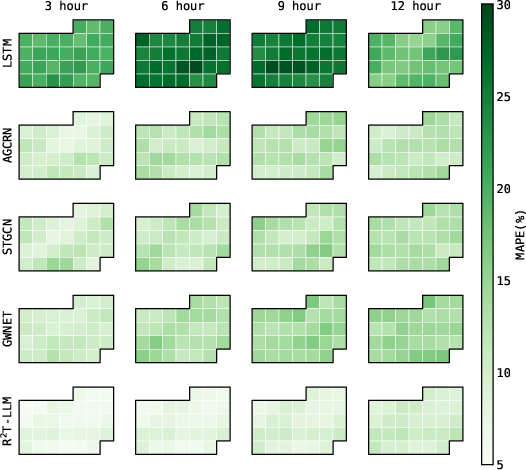
Figure 5: Spatial and temporal error maps for R²T-LLM and baselines, evidencing better homogeneity and reduced mean average percentage errors across time and geography.
Ablation Analysis
Component-wise ablation highlights the significance of temporal (date) information and spatial context (PoIs, weather) for reliable predictions. Date information exerts the largest impact on error; removing CoT reasoning and contextual knowledge degrades both accuracy and explainability.
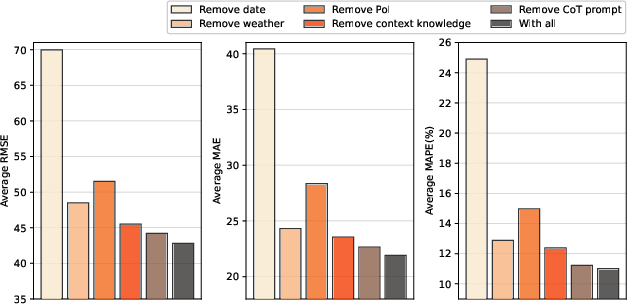
Figure 6: Ablation results demonstrating degradation in prediction performance with removal of key prompt components, especially date and PoI information.
Zero-shot experiments on previously unseen sensors in San Diego and TaxiBJ datasets show substantial improvements over Llama2 and GPT-3.5/4. R²T-LLM achieves markedly lower RMSE, MAE, and MAPE, indicating successful domain-adaptive transfer.
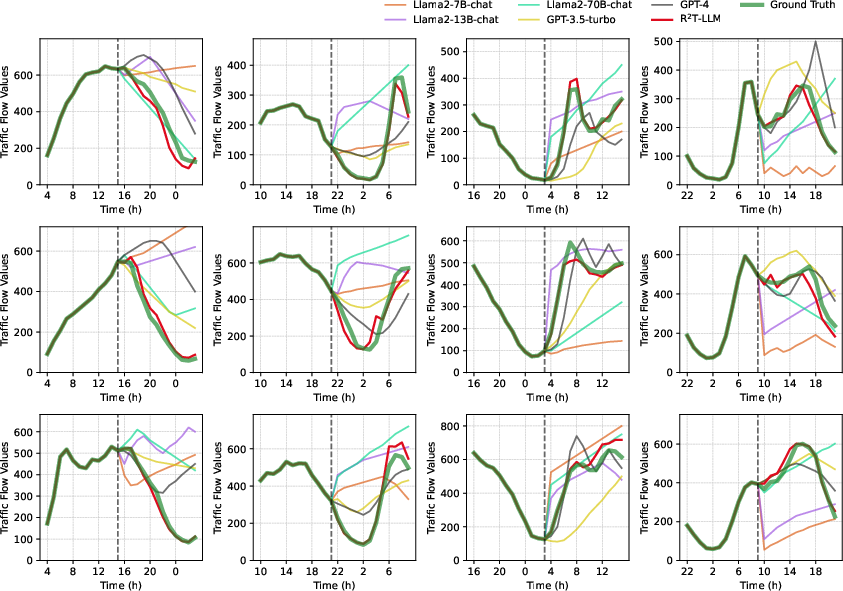
Figure 7: Visualization of zero-shot predictions, demonstrating R²T-LLM’s ability to extract relevant traffic trends and produce accurate forecasts with rich explanations, outperforming baseline LLMs.
Explainability and Responsible Output
R²T-LLM produces responsible traffic forecasts with interpretable explanations, accounting for externalities such as weather, holidays, and regional activities. Example outputs include causal reasoning for flow changes (e.g., reduction during holiday, congestion during rain, elevated volumes near commercial centers).
Practical Implications and Theoretical Insights
R²T-LLM offers compelling advantages for urban forecasting systems:
- Explainability: Direct integration of natural language explanations supports accountability and stakeholder understanding.
- Generalizability: The unified prompt-based approach facilitates adaptation to new cities or sensor configurations with minimal retraining.
- Scalability: LoRA-based adaptation reduces resource requirements, enabling city-scale inference.
- Input Modality Extensibility: The framework’s language foundation allows for simple inclusion of additional modalities (accidents, events, human mobility patterns).
- Integration Potential: The architecture is suited for deployment in urban brain or digital twin platforms, where multi-modal city data must be synthesized for decision support.
Limitations and Future Prospects
Despite excellent overall accuracy and explanation quality, R²T-LLM struggles with certain nuanced fluctuations and rare events, suggesting opportunities for further prompt refinement and multi-modal augmentation. Spatial awareness—explicit sensor graph encoding—remains an open direction for enhancing relational reasoning capabilities. Future work may entail cross-modal fusion, event-driven prompting, and scaling to multi-task urban intelligence.
Conclusion
R²T-LLM bridges the gap between predictive performance and responsible explainability in traffic flow forecasting. Through multi-modal data integration, sophisticated prompt design, and efficient LLM adaptation, it achieves robust, generalizable, and interpretable traffic predictions suitable for intelligent transportation applications. Prospective advancements include more granular spatial reasoning, enrichment of external factors, and deployment in integrated urban analytics pipelines.