- The paper introduces a two-phase Think-and-Execute framework that uses pseudocode to decompose reasoning into a generalized 'Think' phase and a tailored 'Execute' phase.
- Experimental evaluations on Big-Bench Hard show that this approach outperforms direct prompting, zero-shot CoT, and PoT methods across various algorithmic tasks.
- Ablation studies reveal that components like intermediate print statements and code pre-training are critical for effective reasoning transfer to smaller models.
Think-and-Execute: Improving Algorithmic Reasoning in LMs
This paper introduces Think-and-Execute, a novel framework designed to enhance algorithmic reasoning in LLMs. The core idea is to decompose the reasoning process into two distinct phases: Think, where the model identifies a task-level logic applicable across all instances, and Execute, where this logic is tailored to each specific instance and its execution is simulated. By using pseudocode to represent the task-level logic, Think-and-Execute aims to overcome the limitations of instance-specific reasoning approaches like Chain-of-Thought (CoT) and Program-of-Thought (PoT).
Framework Overview
The Think-and-Execute framework (Figure 1) operates in two primary stages:
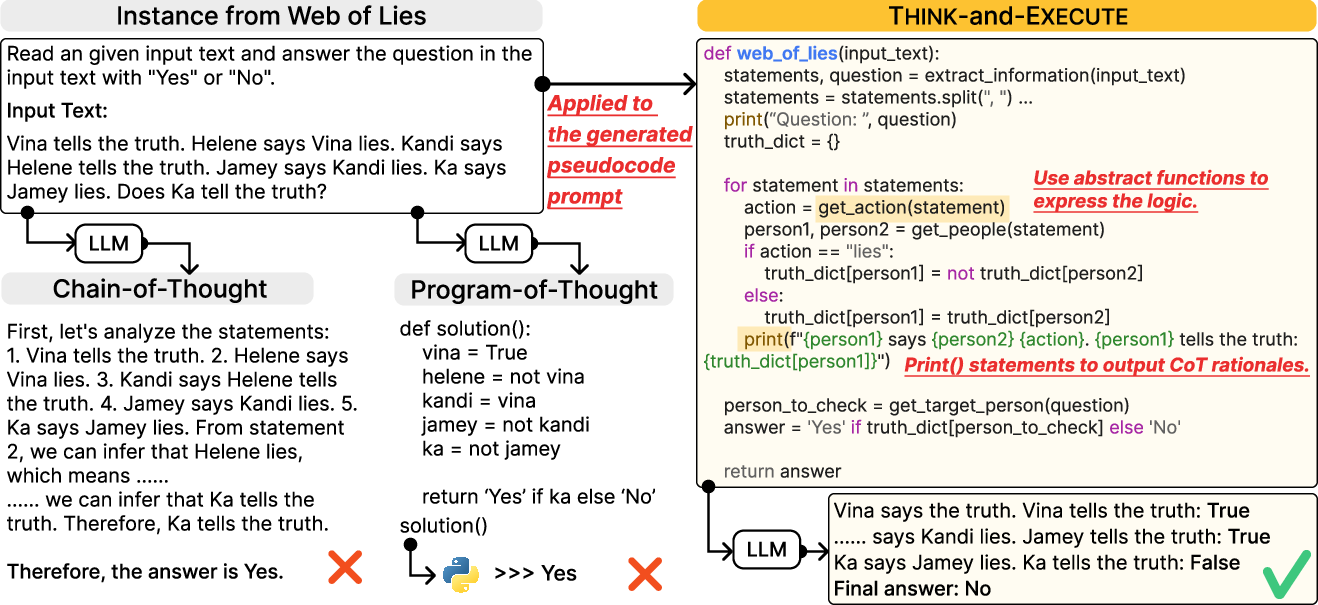
Figure 1: An illustration of Think-and-Execute, compared with Zero-shot Chain-of-Thought and Program-of-Thoughts.
- Think: An Instructor LM (I) analyzes a given task and generates a pseudocode prompt (P) that encapsulates the underlying logic required to solve the task. This involves:
- Constructing a meta prompt with demonstrations from other tasks.
- Generating an analysis of the target task, identifying key reasoning patterns.
- Creating a pseudocode prompt based on the analysis, which breaks down the reasoning steps.
- Execute: A Reasoner LM (R) uses the generated pseudocode prompt (P) to conduct reasoning for a specific instance. This involves:
- Tailoring the logic in P to the given instance.
- Simulating the execution of P, generating intermediate outputs (rationales) and the final answer.
The framework leverages the strengths of both task-level logic discovery and instance-specific adaptation to improve algorithmic reasoning. (Figure 2)
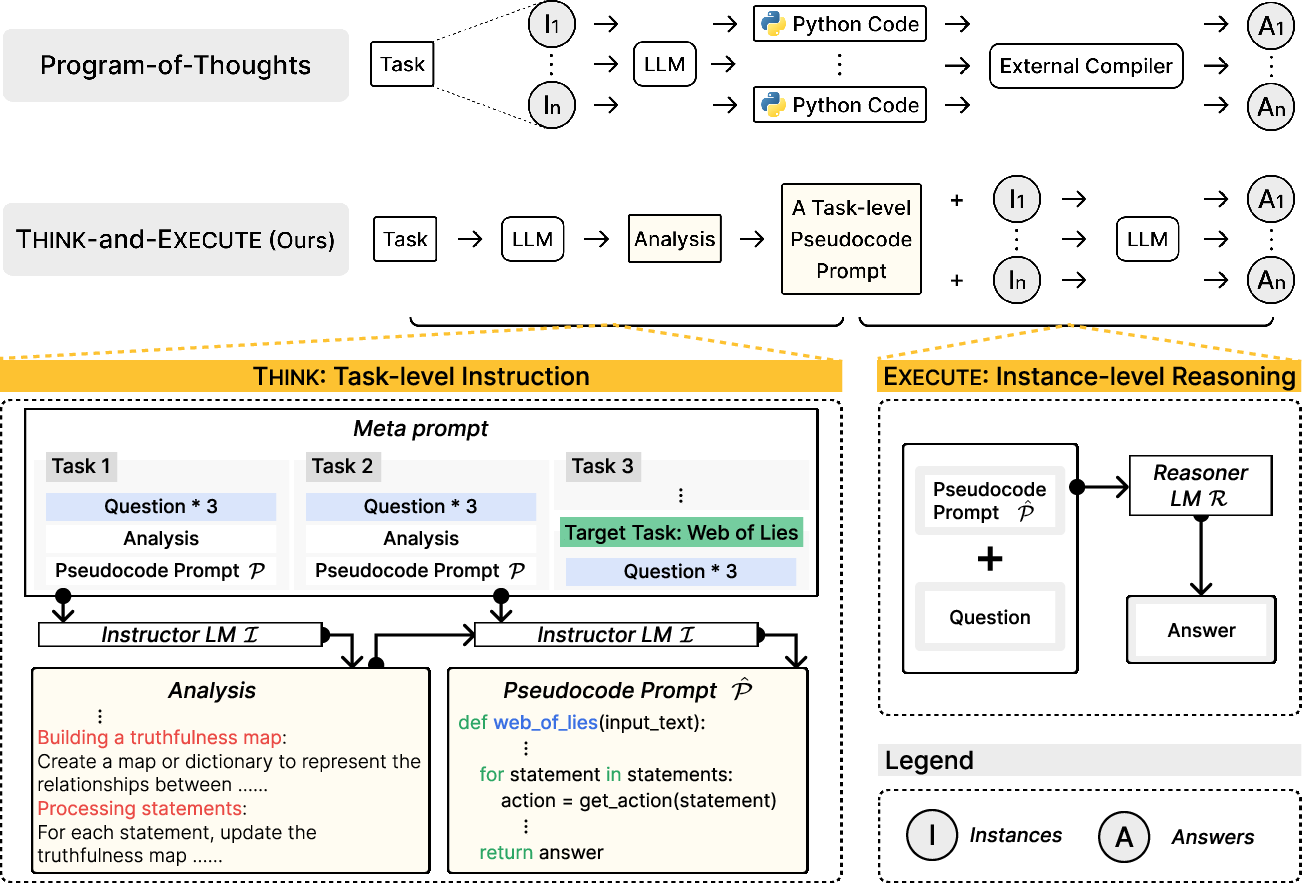
Figure 2: An overview of Think-and-Execute. In Think (Top), an LLM analyzes the given task provided in the meta prompt and generates a pseudocode prompt that describes the necessary logic for solving the task. Then, in Execute (Bottom), the LLM conducts reasoning for each instance by simulating the execution of the pseudocode prompt.
Experimental Evaluation
The authors evaluated Think-and-Execute on seven algorithmic reasoning tasks from the Big-Bench Hard benchmark, comparing it against several baselines:
The results (Table 1) demonstrate that Think-and-Execute outperforms these baselines across various tasks and model sizes. Notably, Think-and-Execute achieves significant improvements over PoT, suggesting that discovering task-level logic is more beneficial than generating instance-specific code.
Ablation Studies
Ablation studies were conducted to assess the impact of different components of the pseudocode prompt (Figure 3). The results indicate that semantics and intermediate print() statements are crucial for guiding the LLMs' reasoning. Furthermore, generating an analysis before the pseudocode prompt also significantly improves performance.
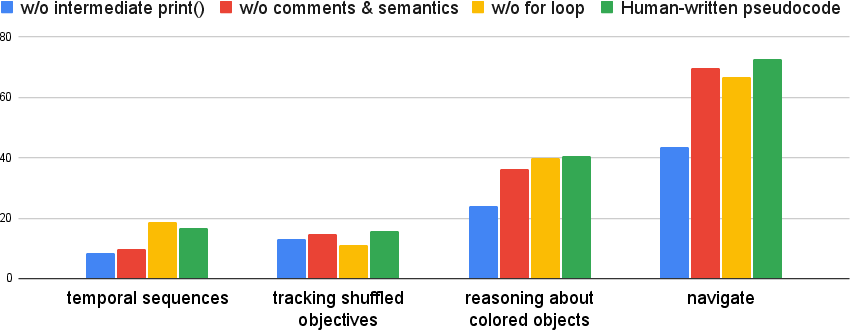
Figure 3: Ablation study of the components of pseudocode prompt using GPT-3.5-Turbo.
Code Pre-training Analysis
The paper investigates the impact of code pre-training on the reasoning capabilities of LMs when applying Think-and-Execute. A comparison between CodeLlama-13B and Llama-13B (Figure 4) reveals that CodeLlama-13B exhibits superior reasoning abilities, suggesting that knowledge of code, acquired through pre-training on code corpora, is essential for understanding task-level logic written in pseudocode.
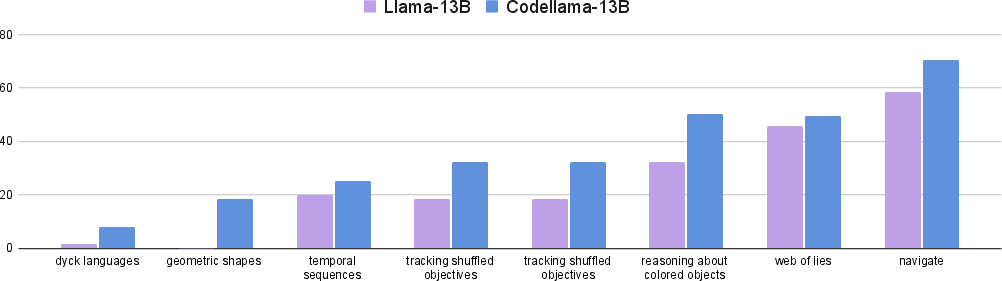
Figure 4: Analysis on the effect of code pre-training on the reasoning capability in applying Think-and-Execute. Without pre-training on code corpora the accuracies drop notably.
Key Findings
- Think-and-Execute significantly improves algorithmic reasoning compared to direct prompting, zero-shot CoT, and zero-shot PoT.
- Task-level pseudocode prompts benefit a wider range of algorithmic reasoning tasks than instance-specific Python code.
- The logic discovered by an LLM can be transferred to smaller LMs (SLMs), such as CodeLlama-7B and -13B.
- Pseudocode better describes the logic for solving a task than natural language.
- Code pre-training enhances the ability of LMs to understand and apply task-level logic written in pseudocode.
Implications and Future Directions
The Think-and-Execute framework offers a promising approach to improving algorithmic reasoning in LLMs by decoupling logic discovery from instance-specific execution. The use of pseudocode as an intermediate representation enables the transfer of knowledge to smaller models and facilitates more effective reasoning compared to natural language.
Future research could explore the application of Think-and-Execute to other reasoning domains, such as multi-hop reasoning and symbolic reasoning. Additionally, investigating methods for automating the generation of high-quality pseudocode prompts and exploring different pseudocode representations could further enhance the framework's performance.
Conclusion
The paper presents a compelling case for the Think-and-Execute framework as a means of enhancing algorithmic reasoning in LLMs. By decomposing the reasoning process and leveraging pseudocode, the framework achieves significant improvements over existing approaches and opens new avenues for research in this area.

