Source-Aware Training Enables Knowledge Attribution in Language Models
(2404.01019)Abstract
LLMs learn a vast amount of knowledge during pretraining, but they are often oblivious to the source(s) of such knowledge. We investigate the problem of intrinsic source citation, where LLMs are required to cite the pretraining source supporting a generated response. Intrinsic source citation can enhance LLM transparency, interpretability, and verifiability. To give LLMs such ability, we explore source-aware training -- a post pretraining recipe that involves (i) training the LLM to associate unique source document identifiers with the knowledge in each document, followed by (ii) an instruction-tuning to teach the LLM to cite a supporting pretraining source when prompted. Source-aware training can easily be applied to pretrained LLMs off the shelf, and diverges minimally from existing pretraining/fine-tuning frameworks. Through experiments on carefully curated data, we demonstrate that our training recipe can enable faithful attribution to the pretraining data without a substantial impact on the model's quality compared to standard pretraining. Our results also highlight the importance of data augmentation in achieving attribution. Code and data available here: \url{https://github.com/mukhal/intrinsic-source-citation}
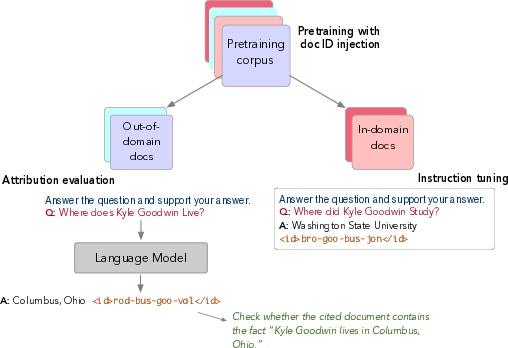
Overview
-
This paper introduces a method called source-aware training, designed to enable language models to cite the original documents from which their responses are derived, increasing transparency, interpretability, and verifiability.
-
Source-aware training consists of two phases: training language models to associate responses with the source document identifiers, and instruction-tuning to prompt models to cite these sources accurately.
-
Experimental results show that the strategy of document identifier injection and data augmentation significantly affects the model's citation abilities, maintaining quality performance on tasks like intrinsic citation and external datasets evaluation.
-
The approach has broad practical implications for developing trustworthy AI systems and sets the stage for future research on enhancing models' citation capabilities and investigating the balance between performance, citation accuracy, and training efficiency.
Source-Aware Training for LLMs: A New Approach to Knowledge Attribution
Introduction to Source-Aware Training
In the terrain of language model research, the capacity for models to accurately attribute their generated responses to specific pretraining sources is gaining critical importance. This work explore a methodological advancement known as source-aware training, aimed at enabling language models to inherently cite the original documents their responses are derived from. Such capability enriches models with greater transparency, interpretability, and verifiability—a trinity crucial for leveraging language models across a spectrum of applications demanding reliability and accountability.
Intrinsic Source Citation
The inherent challenge tackled in this study revolves around intrinsic source citation, where a model must identify and cite the pretraining source(s) underpinning its generated response. Distinct from retrieval-based or post-hoc citation methods, intrinsic source citation embeds the citation capability within the model, potentially leading to more accurate and faithful attribution. The source-aware training approach developed herein consists of two phases: (i) training language models to associate responses with unique identifiers of source documents, and (ii) instruction-tuning that teaches models to cite relevant pretraining sources upon request. The elegance of this procedure lies in its compatibility with existing pretrained models and its minimal departures from established pretraining and fine-tuning frameworks.
Methodological Overview
The source-aware training methodology encompasses:
- Continual Pretraining with Document Identifier Injection: A process where each document in the pretraining corpus is augmented with a unique identifier, allowing the model to learn the association between content and its source document identifier.
- Instruction Tuning for Citation: A fine-tuning stage using a subset of the pretraining data, preparing the model to cite the source of information when prompted with specific instructions.
Notably, the method involves experimenting with various strategies for document identifier injection, such as placing identifiers at the beginning, within, or at the end of documents. It crucially highlights the necessity of data augmentation for enhancing model performance in source attribution tasks.
Empirical Insights and Results
The study reveals several key findings:
- Injection Strategy and Model Performance: The location and frequency of document identifier injection significantly impact the model's ability to perform intrinsic citation, with certain strategies like repeating identifiers throughout a document showing promise.
- Model Quality Maintenance: Despite the additional training objectives introduced through source-aware training, the models maintain competent quality levels, as evidenced by performance on external datasets like Wikitext-v2.
- Instruction Tuning Effectiveness: The instruction tuning phase is paramount, enabling the models to not just recall but accurately attribute responses to the correct pretraining sources.
- Data Augmentation's Role: Document-level data augmentation emerges as a vital component for achieving accurate out-of-domain citation, underscoring the need for diverse exposure to training material.
Practical Implications and Future Directions
Practical implications of this research are substantial, carrying weight for the development of trustworthy AI systems. By endowing models with the capability to cite their knowledge sources, developers and users can gain insights into the provenance of model outputs, enhancing trust and enabling easier verification. The methodology also opens doors to refined model interpretability and paves the way for addressing concerns related to data privacy, copyright infringements, and information veracity within model training corpora.
Looking ahead, future research avenues could explore scaling source-aware training to larger datasets, refining document identifier strategies for more complex information types, and extending citation capabilities to encompass a wider array of knowledge forms beyond factual content. Additionally, investigating the balance between model performance, source citation accuracy, and training efficiency remains a fertile ground for further inquiry.
In summary, this work sets a foundational stone in the quest for building language models cognizant of their knowledge origins, marking a step forward in the journey towards AI systems that are not only powerful but also principled and accountable.