"We Have No Idea How Models will Behave in Production until Production": How Engineers Operationalize Machine Learning
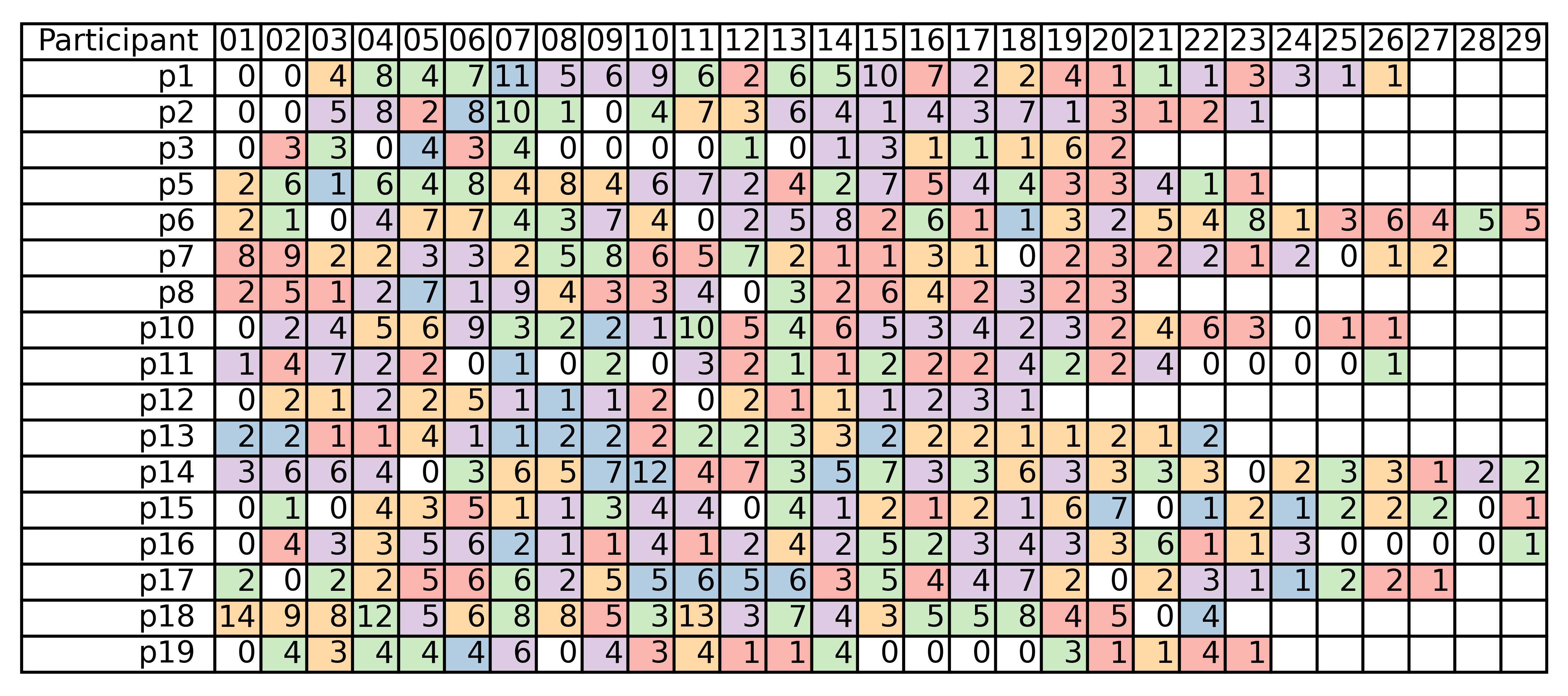
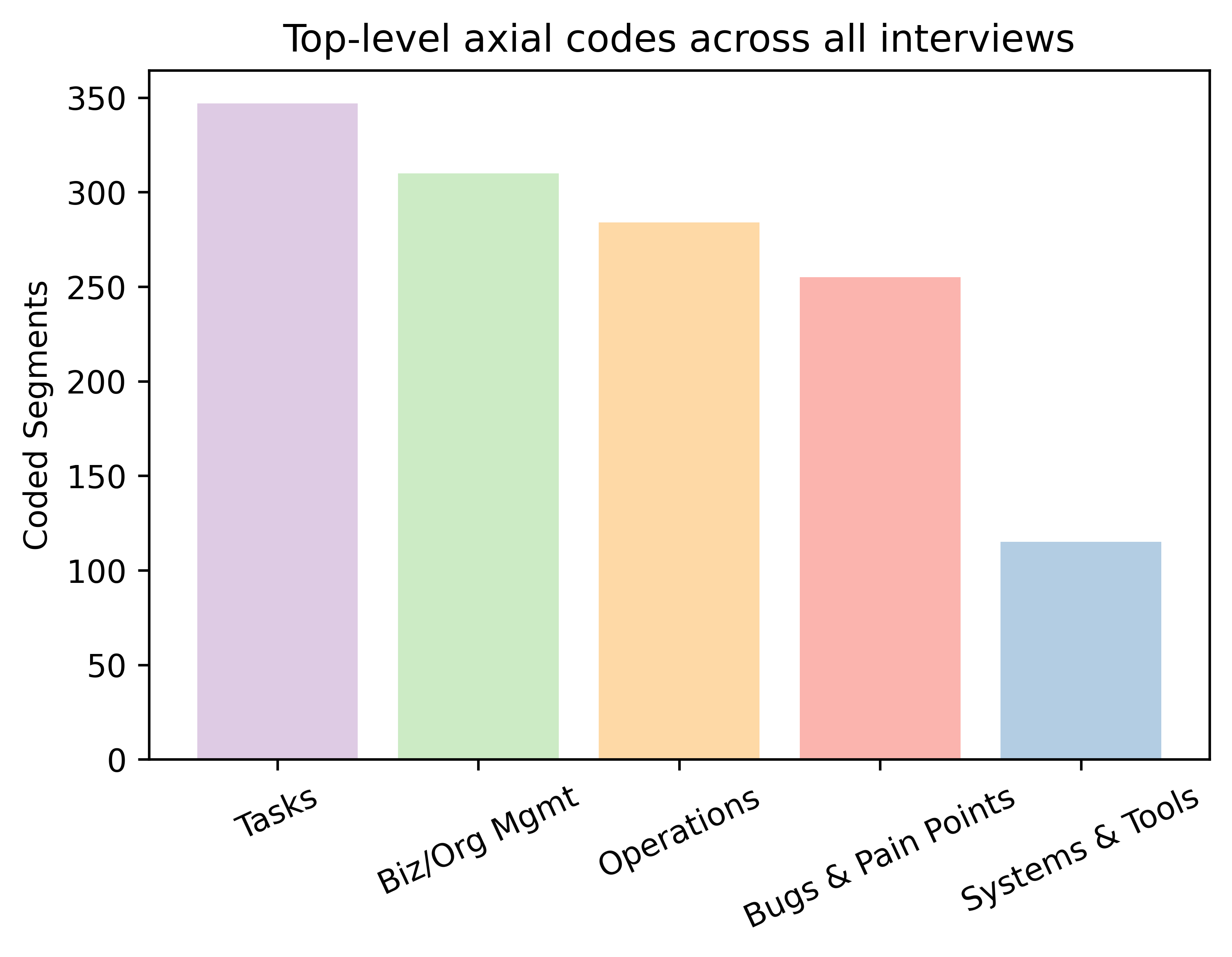
Abstract: Organizations rely on machine learning engineers (MLEs) to deploy models and maintain ML pipelines in production. Due to models' extensive reliance on fresh data, the operationalization of machine learning, or MLOps, requires MLEs to have proficiency in data science and engineering. When considered holistically, the job seems staggering -- how do MLEs do MLOps, and what are their unaddressed challenges? To address these questions, we conducted semi-structured ethnographic interviews with 18 MLEs working on various applications, including chatbots, autonomous vehicles, and finance. We find that MLEs engage in a workflow of (i) data preparation, (ii) experimentation, (iii) evaluation throughout a multi-staged deployment, and (iv) continual monitoring and response. Throughout this workflow, MLEs collaborate extensively with data scientists, product stakeholders, and one another, supplementing routine verbal exchanges with communication tools ranging from Slack to organization-wide ticketing and reporting systems. We introduce the 3Vs of MLOps: velocity, visibility, and versioning -- three virtues of successful ML deployments that MLEs learn to balance and grow as they mature. Finally, we discuss design implications and opportunities for future work.
- Ease.ML: A Lifecycle Management System for MLDev and MLOps. In Conference on Innovative Data Systems Research (CIDR 2021). https://www.microsoft.com/en-us/research/publication/ease-ml-a-lifecycle-management-system-for-mldev-and-mlops/
- Sridhar Alla and Suman Kalyan Adari. 2021. What is mlops? In Beginning MLOps with MLFlow. Springer, 79–124.
- Software Engineering for Machine Learning: A Case Study. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 291–300. https://doi.org/10.1109/ICSE-SEIP.2019.00042
- Anonymous. 2021. ML Reproducibility Systems: Status and Research Agenda. https://openreview.net/forum?id=v-6XBItNld2
- Challenges and Experiences with {{\{{MLOps}}\}} for Performance Diagnostics in {{\{{Hybrid-Cloud}}\}} Enterprise Software Deployments. In 2020 USENIX Conference on Operational Machine Learning (OpML 20).
- A Machine Learning Model Helps Process Interviewer Comments in Computer-assisted Personal Interview Instruments: A Case Study. Field Methods (2022), 1525822X221107053.
- Data Debugging and Exploration with Vizier. In Proceedings of the 2019 International Conference on Management of Data (Amsterdam, Netherlands) (SIGMOD ’19). Association for Computing Machinery, New York, NY, USA, 1877–1880. https://doi.org/10.1145/3299869.3320246
- Data Validation for Machine Learning. In Proceedings of SysML. https://mlsys.org/Conferences/2019/doc/2019/167.pdf
- VisTrails: visualization meets data management. In Proceedings of the 2006 ACM SIGMOD international conference on Management of data. 745–747.
- The CRISP-DM user guide. In 4th CRISP-DM SIG Workshop in Brussels in March, Vol. 1999. sn.
- Towards a unified query language for provenance and versioning. In 7th {normal-{\{{USENIX}normal-}\}} Workshop on the Theory and Practice of Provenance (TaPP 15).
- Ji Young Cho and Eun-Hee Lee. 2014. Reducing confusion about grounded theory and qualitative content analysis: Similarities and differences. Qualitative report 19, 32 (2014).
- An introduction to agile methods. Adv. Comput. 62, 03 (2004), 1–66.
- Clipper: A {{\{{Low-Latency}}\}} Online Prediction Serving System. In 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). 613–627.
- John W Creswell and Cheryl N Poth. 2016. Qualitative inquiry and research design: Choosing among five approaches. Sage publications.
- Susan B Davidson and Juliana Freire. 2008. Provenance and scientific workflows: challenges and opportunities. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data. 1345–1350.
- DevOps. Ieee Software 33, 3 (2016), 94–100.
- Mihail Eric. [n. d.]. MLOps is a mess but that’s to be expected. https://www.mihaileric.com/posts/mlops-is-a-mess/
- What makes users trust a chatbot for customer service? An exploratory interview study. In International conference on internet science. Springer, 194–208.
- Hindsight Logging for Model Training. In VLDB.
- Context: The missing piece in the machine learning lifecycle. In CMI.
- On Continuous Integration / Continuous Delivery for Automated Deployment of Machine Learning Models using MLOps. In 2021 IEEE Fourth International Conference on Artificial Intelligence and Knowledge Engineering (AIKE). 25–28. https://doi.org/10.1109/AIKE52691.2021.00010
- Datasheets for datasets. Commun. ACM 64, 12 (2021), 86–92.
- Samadrita Ghosh. 2021. Mlops challenges and how to face them. https://neptune.ai/blog/mlops-challenges-and-how-to-face-them
- MLOps challenges in multi-organization setup: Experiences from two real-world cases. In 2021 IEEE/ACM 1st Workshop on AI Engineering-Software Engineering for AI (WAIN). IEEE, 82–88.
- How many interviews are enough? An experiment with data saturation and variability. Field methods 18, 1 (2006), 59–82.
- Proactive Wrangling: Mixed-Initiative End-User Programming of Data Transformation Scripts. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology (Santa Barbara, California, USA) (UIST ’11). Association for Computing Machinery, New York, NY, USA, 65–74. https://doi.org/10.1145/2047196.2047205
- Ground: A Data Context Service.. In CIDR.
- Trials and tribulations of developers of intelligent systems: A field study. 2016 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC) (2016), 162–170.
- Understanding and visualizing data iteration in machine learning. In Proceedings of the 2020 CHI conference on human factors in computing systems. 1–13.
- Improving Fairness in Machine Learning Systems: What Do Industry Practitioners Need?. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems - CHI ’19. ACM Press, Glasgow, Scotland Uk, 1–16. https://doi.org/10.1145/3290605.3300830
- Youyang Hou and Dakuo Wang. 2017. Hacking with NPOs: Collaborative Analytics and Broker Roles in Civic Data Hackathons. Proc. ACM Hum.-Comput. Interact. 1, CSCW, Article 53 (dec 2017), 16 pages. https://doi.org/10.1145/3134688
- Taverna: a tool for building and running workflows of services. Nucleic acids research 34, suppl_2 (2006), W729–W732.
- Chip Huyen. 2020. Machine learning tools landscape V2 (+84 new tools). https://huyenchip.com/2020/12/30/mlops-v2.html
- Towards mlops: A framework and maturity model. In 2021 47th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). IEEE, 1–8.
- Wrangler: Interactive visual specification of data transformation scripts. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 3363–3372.
- Enterprise Data Analysis and Visualization: An Interview Study. IEEE Transactions on Visualization and Computer Graphics 18, 12 (2012), 2917–2926. https://doi.org/10.1109/TVCG.2012.219
- Model assertions for debugging machine learning.
- Variolite: Supporting Exploratory Programming by Data Scientists.. In CHI, Vol. 10. 3025453–3025626.
- The Emerging Role of Data Scientists on Software Development Teams. In Proceedings of the 38th International Conference on Software Engineering (Austin, Texas) (ICSE ’16). Association for Computing Machinery, New York, NY, USA, 96–107. https://doi.org/10.1145/2884781.2884783
- Data scientists in software teams: State of the art and challenges. IEEE Transactions on Software Engineering 44, 11 (2017), 1024–1038.
- Monitoring and explainability of models in production. ArXiv abs/2007.06299 (2020).
- Johannes Köster and Sven Rahmann. 2012. Snakemake—a scalable bioinformatics workflow engine. Bioinformatics 28, 19 (2012), 2520–2522.
- Machine Learning Operations (MLOps): Overview, Definition, and Architecture. https://doi.org/10.48550/ARXIV.2205.02302
- Sanjay Krishnan and Eugene Wu. 2017. PALM: Machine Learning Explanations For Iterative Debugging. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics - HILDA’17. ACM Press, Chicago, IL, USA, 1–6. https://doi.org/10.1145/3077257.3077271
- Sean Kross and Philip Guo. 2021. Orienting, Framing, Bridging, Magic, and Counseling: How Data Scientists Navigate the Outer Loop of Client Collaborations in Industry and Academia. Proc. ACM Hum.-Comput. Interact. 5, CSCW2, Article 311 (oct 2021), 28 pages. https://doi.org/10.1145/3476052
- Sean Kross and Philip J Guo. 2019. Practitioners teaching data science in industry and academia: Expectations, workflows, and challenges. In Proceedings of the 2019 CHI conference on human factors in computing systems. 1–14.
- Requirements and Reference Architecture for MLOps: Insights from Industry. (2022).
- A Survey of Deep Learning Applications to Autonomous Vehicle Control. IEEE Transactions on Intelligent Transportation Systems 22 (2021), 712–733.
- Demystifying a Dark Art: Understanding Real-World Machine Learning Model Development. https://doi.org/10.48550/ARXIV.2005.01520
- Cheng Han Lee. 2020. 3 data careers decoded and what it means for you. https://www.udacity.com/blog/2014/12/data-analyst-vs-data-scientist-vs-data-engineer.html
- A survey of DevOps concepts and challenges. ACM Computing Surveys (CSUR) 52, 6 (2019), 1–35.
- MLOps: Practices, Maturity Models, Roles, Tools, and Challenges-A Systematic Literature Review. ICEIS (1) (2022), 308–320.
- The CLEAR Benchmark: Continual LEArning on Real-World Imagery. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). https://openreview.net/forum?id=43mYF598ZDB
- Mike Loukides. 2012. What is DevOps? ” O’Reilly Media, Inc.”.
- DevOps in practice: A multiple case study of five companies. Information and Software Technology 114 (2019), 217–230.
- Co-Designing Checklists to Understand Organizational Challenges and Opportunities around Fairness in AI. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–14. https://doi.org/10.1145/3313831.3376445
- Who needs MLOps: What data scientists seek to accomplish and how can MLOps help?. In 2021 IEEE/ACM 1st Workshop on AI Engineering-Software Engineering for AI (WAIN). IEEE, 109–112.
- Beatriz MA Matsui and Denise H Goya. 2022. MLOps: five steps to guide its effective implementation. In Proceedings of the 1st International Conference on AI Engineering: Software Engineering for AI. 33–34.
- Model cards for model reporting. In Proceedings of the conference on fairness, accountability, and transparency. 220–229.
- MLReef. 2021. Global mlops and ML Tools Landscape: Mlreef. https://about.mlreef.com/blog/global-mlops-and-ml-tools-landscape/
- Akshay Naresh Modi et al. 2017. TFX: A TensorFlow-Based Production-Scale Machine Learning Platform. In KDD 2017.
- A unifying view on dataset shift in classification. Pattern Recognition 45, 1 (2012), 521–530. https://doi.org/10.1016/j.patcog.2011.06.019
- Practices and Infrastructures for ML Systems–An Interview Study in Finnish Organizations. (2022).
- Michael Muller. 2014. Curiosity, creativity, and surprise as analytic tools: Grounded theory method. In Ways of Knowing in HCI. Springer, 25–48.
- How data science workers work with data: Discovery, capture, curation, design, creation. In Proceedings of the 2019 CHI conference on human factors in computing systems. 1–15.
- Vamsa: Automated provenance tracking in data science scripts. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1542–1551.
- Evaluating a model - advice for applying machine learning. https://www.coursera.org/lecture/advanced-learning-algorithms/evaluating-a-model-26yGi
- Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift. In NeurIPS.
- Challenges of Real-World Reinforcement Learning:Definitions, Benchmarks & Analysis. Machine Learning Journal (2021).
- Challenges in Deploying Machine Learning: A Survey of Case Studies. ACM Comput. Surv. (apr 2022). https://doi.org/10.1145/3533378 Just Accepted.
- Samir Passi and Steven J. Jackson. 2017. Data Vision: Learning to See Through Algorithmic Abstraction. Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing (2017).
- Samir Passi and Steven J Jackson. 2018. Trust in data science: Collaboration, translation, and accountability in corporate data science projects. Proceedings of the ACM on Human-Computer Interaction 2, CSCW (2018), 1–28.
- Investigating statistical machine learning as a tool for software development. In International Conference on Human Factors in Computing Systems.
- Data management challenges in production machine learning. In Proceedings of the 2017 ACM International Conference on Management of Data. 1723–1726.
- Data Lifecycle Challenges in Production Machine Learning: A Survey. SIGMOD Record 47, 2 (2018), 12.
- Adoption of machine learning systems for medical diagnostics in clinics: qualitative interview study. Journal of Medical Internet Research 23, 10 (2021), e29301.
- Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift. In NeurIPS.
- Snorkel: Rapid training data creation with weak supervision. In Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases, Vol. 11. NIH Public Access, 269.
- A multivocal literature review of mlops tools and features. In 2022 48th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). IEEE, 84–91.
- A data quality-driven view of mlops. arXiv preprint arXiv:2102.07750 (2021).
- A Survey on Data Collection for Machine Learning: A Big Data - AI Integration Perspective. IEEE Transactions on Knowledge and Data Engineering (2019), 1–1. https://doi.org/10.1109/TKDE.2019.2946162 Conference Name: IEEE Transactions on Knowledge and Data Engineering.
- Demystifying mlops and presenting a recipe for the selection of open-source tools. Applied Sciences 11, 19 (2021), 8861.
- Improving reproducibility of data science pipelines through transparent provenance capture. Proceedings of the VLDB Endowment 13, 12 (2020), 3354–3368.
- “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. In proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–15.
- Sebastian Schelter et al. 2018. Automating Large-Scale Data Quality Verification. In PVLDB’18.
- Hidden Technical Debt in Machine Learning Systems. In NIPS.
- Adoption and Effects of Software Engineering Best Practices in Machine Learning. In Proceedings of the 14th ACM / IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM) (Bari, Italy) (ESEM ’20). Association for Computing Machinery, New York, NY, USA, Article 3, 12 pages. https://doi.org/10.1145/3382494.3410681
- Rethinking Streaming Machine Learning Evaluation. ArXiv abs/2205.11473 (2022).
- Bolt-on, Compact, and Rapid Program Slicing for Notebooks. Proc. VLDB Endow. (sep 2023).
- Shreya Shankar and Aditya G. Parameswaran. 2022. Towards Observability for Production Machine Learning Pipelines. ArXiv abs/2108.13557 (2022).
- James P Spradley. 2016. The ethnographic interview. Waveland Press.
- An Empirical Analysis of Backward Compatibility in Machine Learning Systems. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2020).
- Steve Nunez. 2022. Why AI investments fail to deliver. https://www.infoworld.com/article/3639028/why-ai-investments-fail-to-deliver.html [Online; accessed 15-September-2022].
- Anselm Strauss and Juliet Corbin. 1994. Grounded theory methodology: An overview. (1994).
- Towards CRISP-ML (Q): a machine learning process model with quality assurance methodology. Machine learning and knowledge extraction 3, 2 (2021), 392–413.
- Masashi Sugiyama et al. 2007. Covariate Shift Adaptation by Importance Weighted Cross Validation. In JMLR.
- MLOps - Definitions, Tools and Challenges. In 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC). 0453–0460. https://doi.org/10.1109/CCWC54503.2022.9720902
- Damian A Tamburri. 2020. Sustainable mlops: Trends and challenges. In 2020 22nd international symposium on symbolic and numeric algorithms for scientific computing (SYNASC). IEEE, 17–23.
- MLOps: A taxonomy and a methodology. IEEE Access 10 (2022), 63606–63618.
- Manasi Vartak. 2016. ModelDB: a system for machine learning model management. In HILDA ’16.
- Human-AI Collaboration in Data Science: Exploring Data Scientists’ Perceptions of Automated AI. Proc. ACM Hum.-Comput. Interact. 3, CSCW, Article 211 (nov 2019), 24 pages. https://doi.org/10.1145/3359313
- Joyce Weiner. 2020. Why AI/data science projects fail: how to avoid project pitfalls. Synthesis Lectures on Computation and Analytics 1, 1 (2020), i–77.
- Wikipedia contributors. 2022. MLOps — Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/w/index.php?title=MLOps&oldid=1109828739 [Online; accessed 15-September-2022].
- A Fine-Grained Analysis on Distribution Shift. ArXiv abs/2110.11328 (2021).
- Goals, Process, and Challenges of Exploratory Data Analysis: An Interview Study. ArXiv abs/1911.00568 (2019).
- Production machine learning pipelines: Empirical analysis and optimization opportunities. In Proceedings of the 2021 International Conference on Management of Data. 2639–2652.
- Whither AutoML? Understanding the Role of Automation in Machine Learning Workflows. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (Yokohama, Japan) (CHI ’21). Association for Computing Machinery, New York, NY, USA, Article 83, 16 pages. https://doi.org/10.1145/3411764.3445306
- M. Zaharia et al. 2018. Accelerating the Machine Learning Lifecycle with MLflow. IEEE Data Eng. Bull. 41 (2018), 39–45.
- How do data science workers collaborate? roles, workflows, and tools. Proceedings of the ACM on Human-Computer Interaction 4, CSCW1 (2020), 1–23.
- OneLabeler: A Flexible System for Building Data Labeling Tools. In CHI Conference on Human Factors in Computing Systems. 1–22.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.