- The paper redefines emergent abilities by showing that pre-training loss, not model size, predicts downstream task performance.
- It demonstrates a threshold effect where performance improves significantly once a critical low loss is achieved.
- Experiments across various model scales confirm that optimized pre-training loss is key to unlocking novel LLM capabilities.
Understanding Emergent Abilities of LLMs from the Loss Perspective
The paper "Understanding Emergent Abilities of LLMs from the Loss Perspective" investigates the enigmatic phenomena of emergent abilities exhibited in LLMs. It challenges the conventional wisdom that these emergent capabilities are solely a function of model or data size and proposes a novel exploration through the lens of pre-training loss.
Emergent Abilities and Pre-training Loss
Emergent abilities in LLMs refer to capabilities that become apparent in larger models but are absent in their smaller counterparts. This work argues against the prevailing belief that these abilities are size-dependent. Instead, it suggests that the pre-training loss—a metric indicative of a model's learning status—serves as a more relevant predictor of emergent abilities.
Key Observations
- Loss as a Predictor: The study demonstrates that models with the same pre-training loss achieve comparable performance on downstream tasks, irrespective of their size. This finding implies that pre-training loss, rather than sheer model size or compute, is predictive of downstream task performance.
- Threshold Effect: Emergent abilities appear when the pre-training loss falls below a certain threshold. Before reaching this threshold, model performance aligns with random guessing, suggesting a phase transition akin to grokking once this critical pre-training loss value is surpassed.
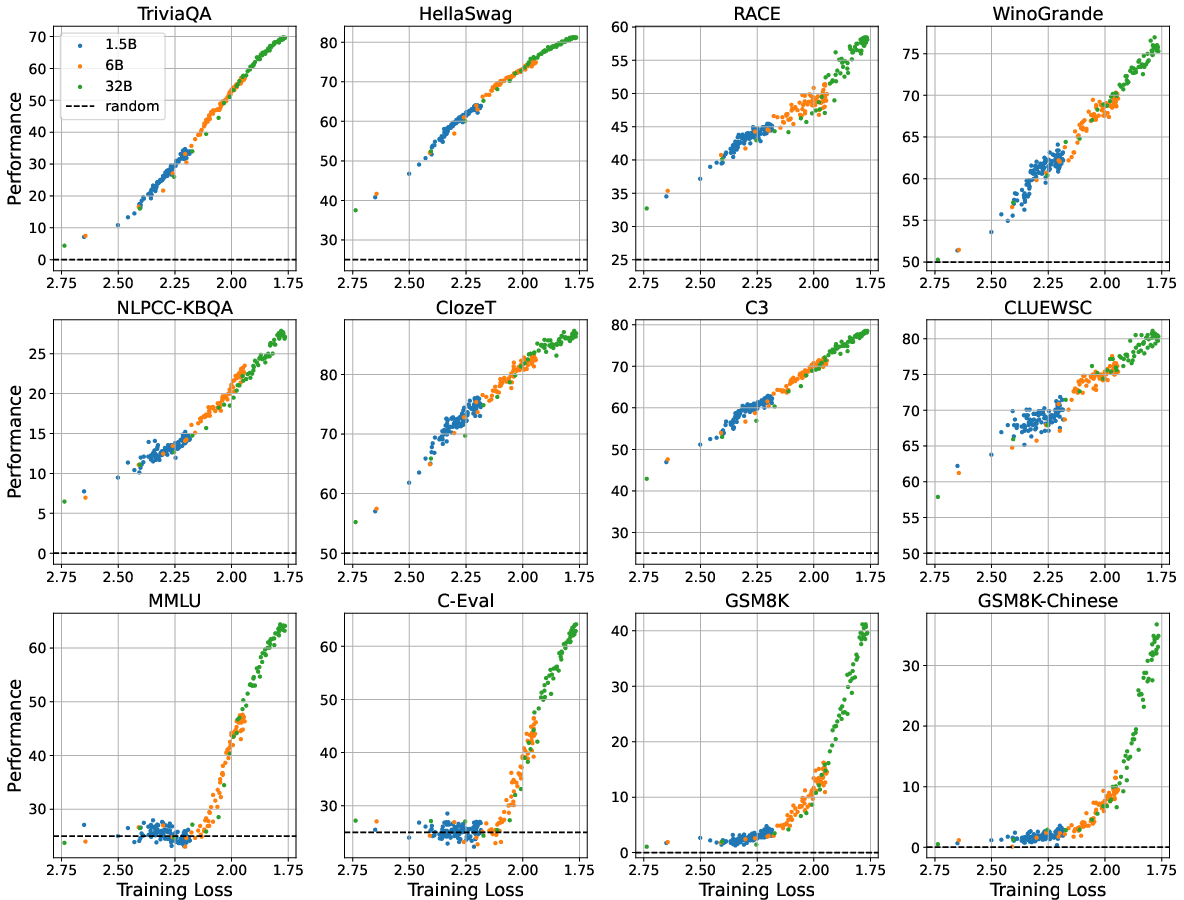
Figure 1: The performance-vs-loss curves of 1.5B, 6B, and 32B models indicating the threshold beyond which performance improves significantly.
- Verification on Different Models: The relationship between pre-training loss and task performance was validated through experiments with models of various sizes, including the LLaMA model series, confirming that the observed trends are robust and not confined to specific architectures or datasets.
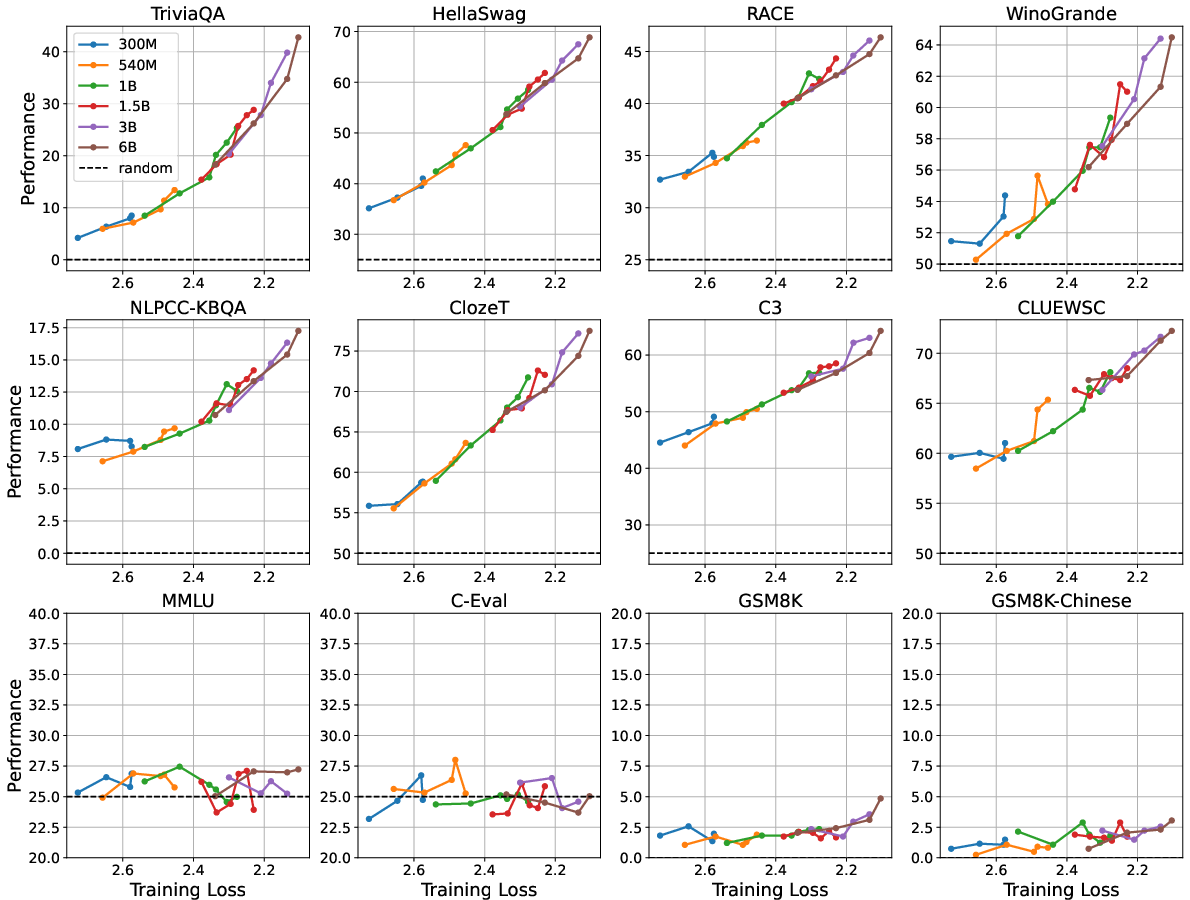
Figure 2: The performance-vs-loss curves of smaller models pre-trained with different numbers of training tokens.
Defining Emergent Abilities
The paper redefines emergent abilities from the loss perspective as abilities that manifest in models achieving lower pre-training loss. The emergent capabilities cannot be anticipated by extrapolating performance trends from models with higher loss values. This reconceptualization implies that previously observed size-related emergent properties may be better explained by examining pre-training loss milestones.
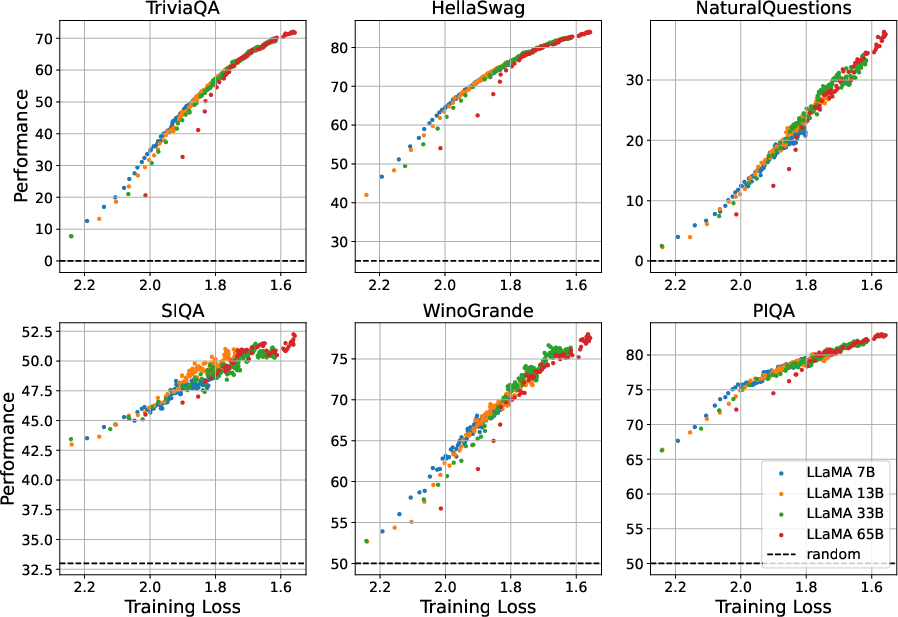
Figure 3: The performance-vs-loss curves of LLaMA models across various downstream tasks, reinforcing the consistency of the loss-performance relationship.
Implications and Future Directions
This study provides a critical insight into the potential of using pre-training loss as a proxy for predicting the emergence of new capabilities. By doing so, it invites a reconsideration of scaling strategies solely based on enlarging model architectures. Further exploration into optimizing training dynamics and learning frameworks to strategically reduce pre-training loss might unlock new abilities in LLMs.
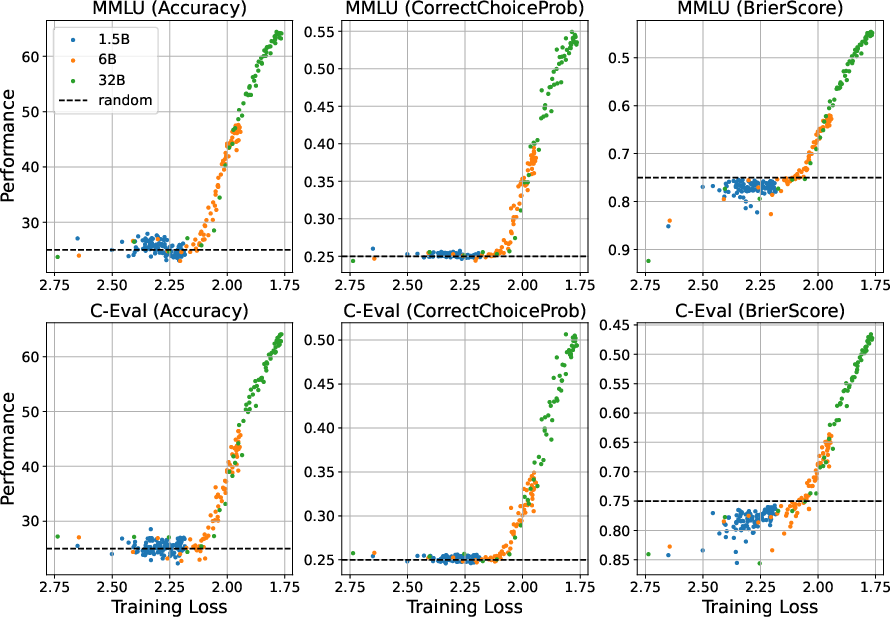
Figure 4: The performance-vs-loss curves of different metrics on MMLU and C-Eval, indicating continuous metrics do not negate the tipping point effect.
Future Work
Future research could explore understanding how tokenizer selection and corpus distribution impact pre-training loss and task performance, potentially paving the way for more data-efficient strategies to reach desired performance thresholds. Additionally, beyond pre-training, the role of fine-tuning regimes and their interplay with pre-training loss in shaping emergent abilities could be a promising area for exploration.
Conclusion
The definitive insight from this work is that pre-training loss serves as a crucial metric in understanding and predicting the capabilities of LLMs, enabling a departure from traditional model-size-centric views of emergent abilities. This provides a roadmap for future optimizations in the training of LLMs, focusing on achieving lower loss values to elicit novel capabilities. By redefining emergent abilities in terms of loss, this paper offers a structural framework for future advancements in the field of LLM development and application.

