LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
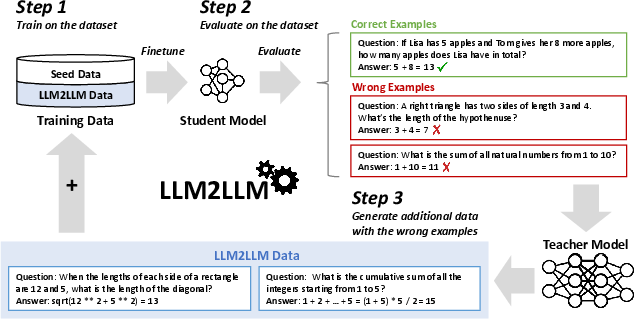
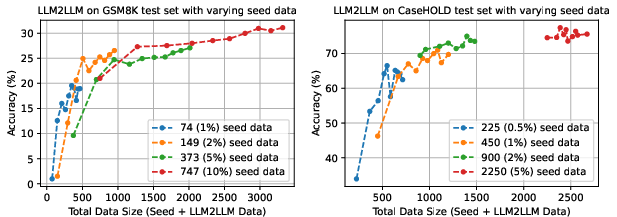
Abstract: Pretrained LLMs are currently state-of-the-art for solving the vast majority of natural language processing tasks. While many real-world applications still require fine-tuning to reach satisfactory levels of performance, many of them are in the low-data regime, making fine-tuning challenging. To address this, we propose LLM2LLM, a targeted and iterative data augmentation strategy that uses a teacher LLM to enhance a small seed dataset by augmenting additional data that can be used for fine-tuning on a specific task. LLM2LLM (1) fine-tunes a baseline student LLM on the initial seed data, (2) evaluates and extracts data points that the model gets wrong, and (3) uses a teacher LLM to generate synthetic data based on these incorrect data points, which are then added back into the training data. This approach amplifies the signal from incorrectly predicted data points by the LLM during training and reintegrates them into the dataset to focus on more challenging examples for the LLM. Our results show that LLM2LLM significantly enhances the performance of LLMs in the low-data regime, outperforming both traditional fine-tuning and other data augmentation baselines. LLM2LLM reduces the dependence on labor-intensive data curation and paves the way for more scalable and performant LLM solutions, allowing us to tackle data-constrained domains and tasks. We achieve improvements up to 24.2% on the GSM8K dataset, 32.6% on CaseHOLD, 32.0% on SNIPS, 52.6% on TREC and 39.8% on SST-2 over regular fine-tuning in the low-data regime using a Llama-2-7B student model. Our code is available at https://github.com/SqueezeAILab/LLM2LLM .
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Palm 2 technical report, 2023.
- Ext5: Towards extreme multi-task scaling for transfer learning. In International Conference on Learning Representations, 2021.
- Synthetic and natural noise both break neural machine translation. arXiv preprint arXiv:1711.02173, 2017.
- Weak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023.
- Instruction mining: When data mining meets large language model finetuning, 2023.
- Alpagasus: Training a better alpaca with fewer data, 2023.
- Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335, 2024.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces. arXiv preprint arXiv:1805.10190, 2018.
- Claude Coulombe. Text data augmentation made simple by leveraging nlp cloud apis. arXiv preprint arXiv:1812.04718, 2018.
- Auggpt: Leveraging chatgpt for text data augmentation, 2023.
- Rephrase and respond: Let large language models ask better questions for themselves, 2023.
- Gpt-4 turbo v.s. gpt-4 comparison. https://github.com/da03/implicit_chain_of_thought/tree/main/gpt4_baselines, 2023.
- Jon Durbin. Jondurbin/airoboros-l2-70b-3.1.2 · hugging face, Oct 2023.
- Using gpt-4 to augment unbalanced data for automatic scoring, 2023.
- A survey of data augmentation approaches for NLP. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 968–988, Online, August 2021. Association for Computational Linguistics.
- Chain-of-thought hub: A continuous effort to measure large language models’ reasoning performance, 2023.
- Specializing smaller language models towards multi-step reasoning. arXiv preprint arXiv:2301.12726, 2023.
- Koala: A dialogue model for academic research. Blog post, April 2023.
- Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998, 2023.
- Language models can teach themselves to program better, 2023.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks, 2023.
- Data augmentation using pre-trained transformer models. In Proceedings of the 2nd Workshop on Life-long Learning for Spoken Language Systems, pages 18–26, 2020.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Self-alignment with instruction backtranslation. arXiv preprint arXiv:2308.06259, 2023.
- Learning question classifiers. In COLING 2002: The 19th International Conference on Computational Linguistics, 2002.
- Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, 2004.
- Tinygsm achieving 80% on gsm8k with small language models, 2023.
- Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172, 2023.
- The flan collection: designing data and methods for effective instruction tuning. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023.
- Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023.
- Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
- Cross-task generalization via natural language crowdsourcing instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3470–3487, 2022.
- Orca 2: Teaching small language models how to reason. arXiv preprint arXiv:2311.11045, 2023.
- Crosslingual generalization through multitask finetuning. In Annual Meeting of the Association for Computational Linguistics, 2023.
- Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707, 2023.
- Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452, 2023.
- instructgpt, 2022.
- Rephrase, augment, reason: Visual grounding of questions for vision-language models, 2023.
- Arthur L Samuel. Some studies in machine learning using the game of checkers. IBM Journal of research and development, 44(1.2):206–226, 2000.
- Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations, 2021.
- Beyond human data: Scaling self-training for problem-solving with language models. arXiv preprint arXiv:2312.06585, 2023.
- Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013.
- Alpaca: A strong, replicable instruction-following model. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7, 2023.
- Gerald Tesauro et al. Temporal difference learning and td-gammon. Communications of the ACM, 38(3):58–68, 1995.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Zeroshotdataaug: Generating and augmenting training data with chatgpt. arXiv preprint arXiv:2304.14334, 2023.
- Self-instruct: Aligning language models with self-generated instructions. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, Toronto, Canada, July 2023. Association for Computational Linguistics.
- Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, 2022.
- Knowda: All-in-one knowledge mixture model for data augmentation in few-shot nlp. arXiv preprint arXiv:2206.10265, 2022.
- Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2021.
- EDA: Easy data augmentation techniques for boosting performance on text classification tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 6382–6388, Hong Kong, China, November 2019. Association for Computational Linguistics.
- Instructiongpt-4: A 200-instruction paradigm for fine-tuning minigpt-4, 2023.
- Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
- Zeroprompt: Scaling prompt-based pretraining to 1,000 tasks improves zero-shot generalization. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 4235–4252, 2022.
- Gpt3mix: Leveraging large-scale language models for text augmentation. arXiv preprint arXiv:2104.08826, 2021.
- Metamath: Bootstrap your own mathematical questions for large language models, 2023.
- Self-rewarding language models. arXiv preprint arXiv:2401.10020, 2024.
- Self-taught optimizer (stop): Recursively self-improving code generation, 2023.
- Star: Bootstrapping reasoning with reasoning, 2022.
- mixup: Beyond empirical risk minimization. In International Conference on Learning Representations, 2018.
- When does pretraining help? assessing self-supervised learning for law and the casehold dataset. In Proceedings of the 18th International Conference on Artificial Intelligence and Law. Association for Computing Machinery, 2021.
- Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364, 2023.
- Lima: Less is more for alignment, 2023.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.