- The paper finds that log probabilities serve as robust estimates for semantic plausibility, outperforming explicit prompt methods in both base and instruction-tuned models.
- It shows that base models align more closely with human plausibility judgments compared to instruction-tuned variants, highlighting tuning limitations.
- The study demonstrates that context-dependent log probability measurements at the word level closely replicate human sensitivity to semantic cues.
Log Probabilities and Semantic Plausibility in LLMs
The paper "Log Probabilities Are a Reliable Estimate of Semantic Plausibility in Base and Instruction-Tuned LLMs" examines the effectiveness of using log probabilities (LL) as a metric for assessing semantic plausibility in LLMs. The study explores both base models and instruction-tuned variants, focusing on their abilities to perform plausibility judgments in a variety of linguistic scenarios.
Experiment 1: Explicit vs. Implicit Plausibility Judgments
The study involves a careful analysis of LLMs' capacity to distinguish plausible from implausible sentences. The models, both base and instruction-tuned, are evaluated using log probabilities and a series of explicitly designed prompts.
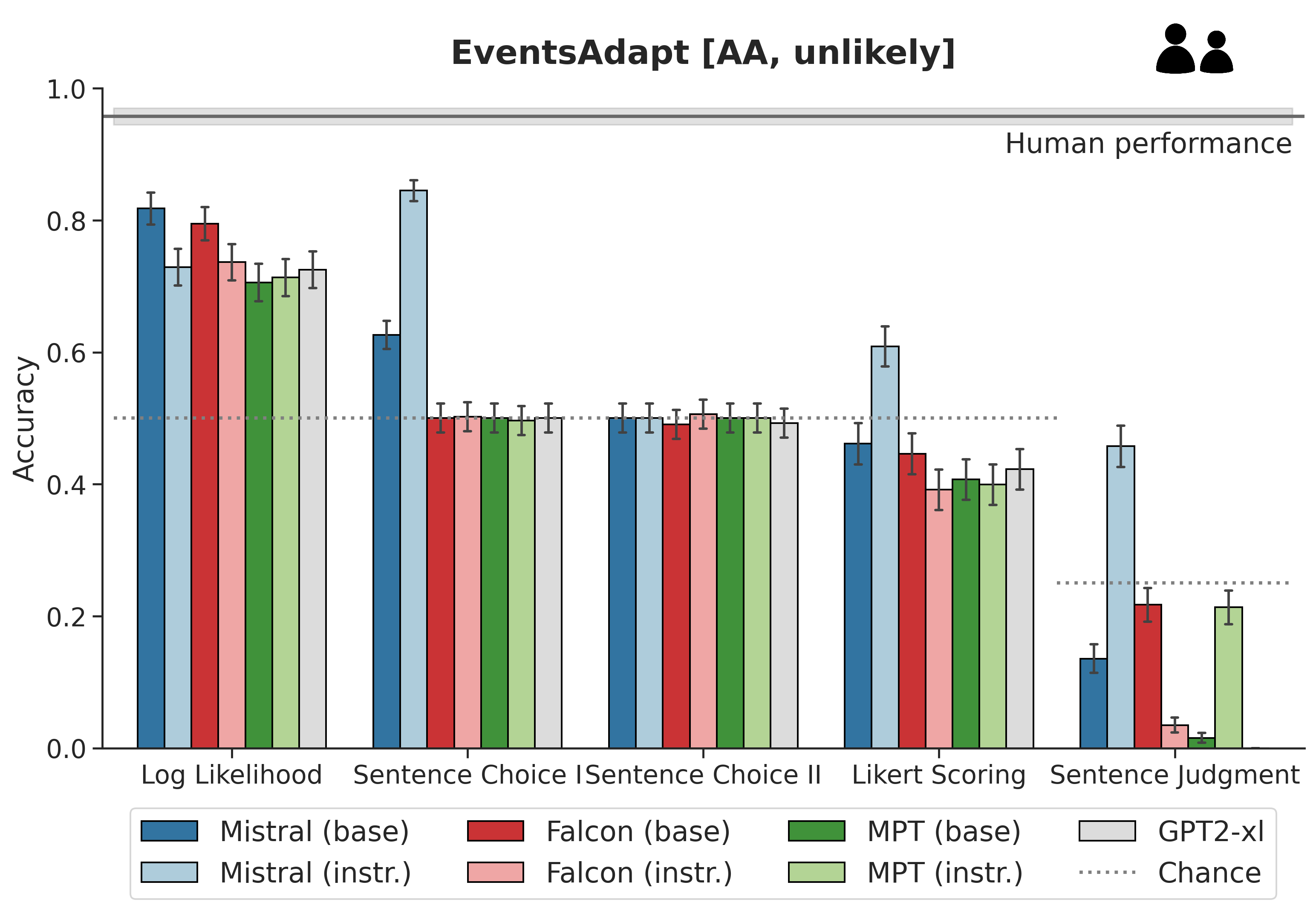
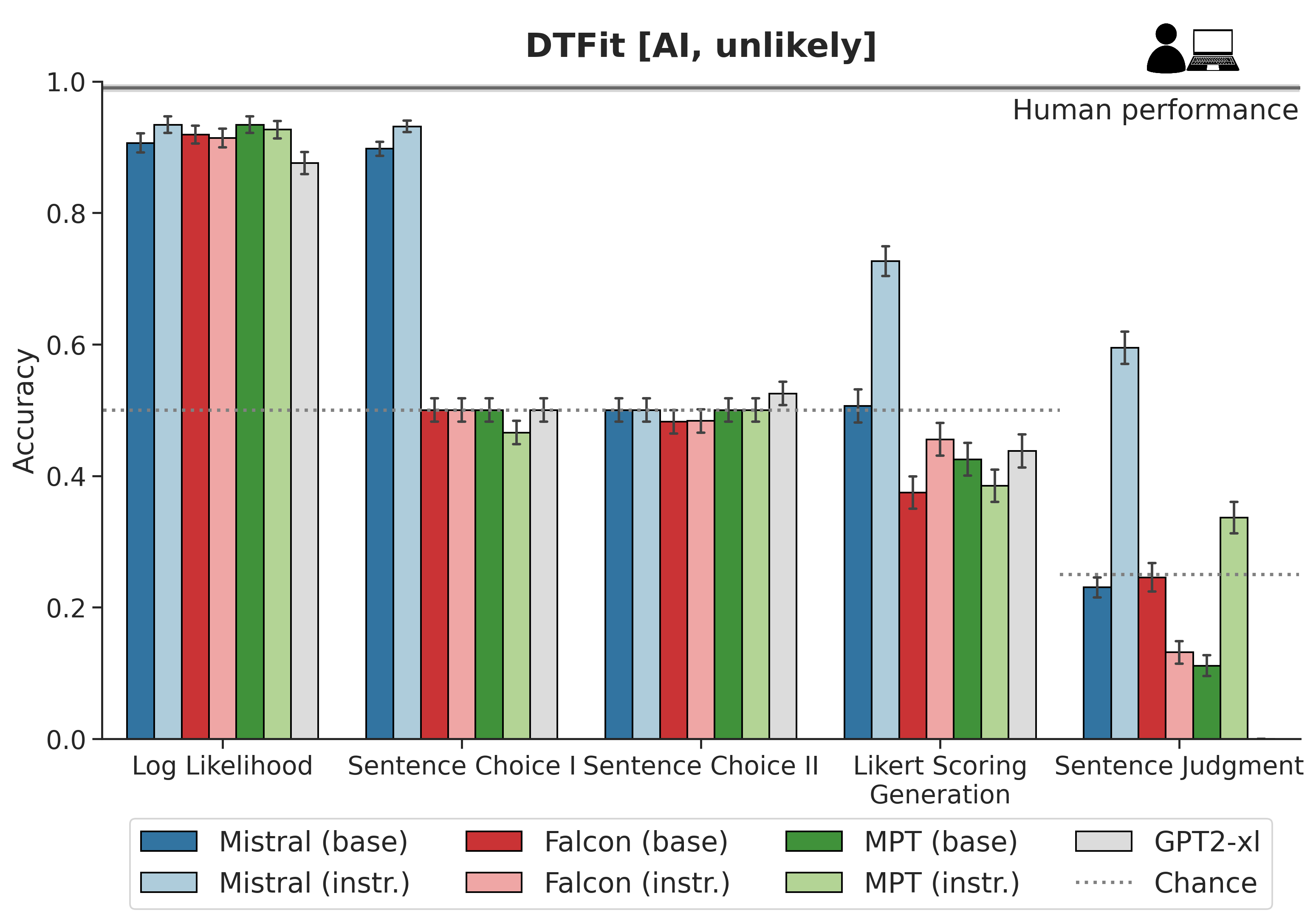
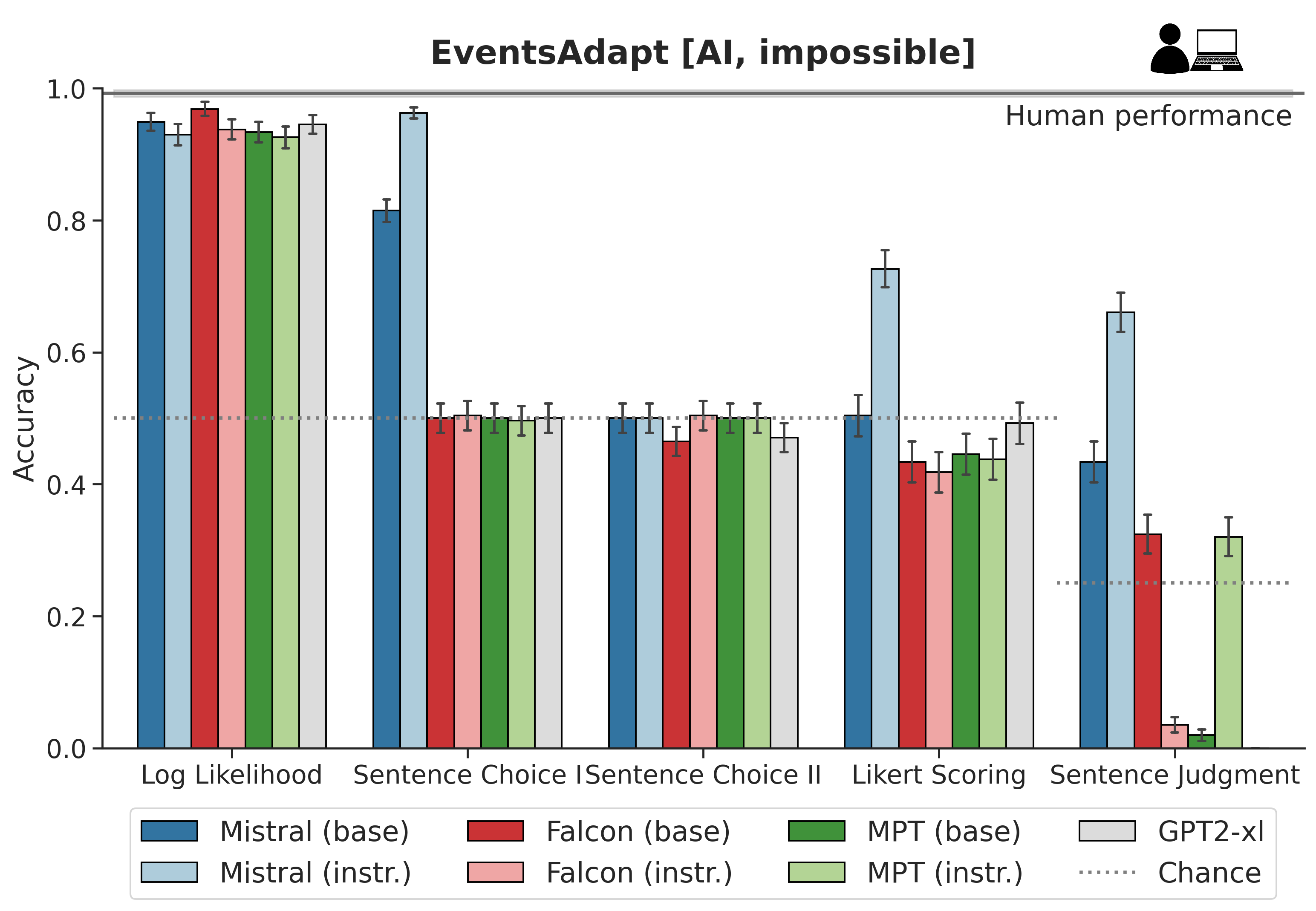
Figure 1: Results of implicit vs. explicit plausibility judgment performance experiments.
Datasets and Experimental Setup
The research utilizes datasets adapted from previous studies, including EventsAdapt and DTFit, which contain sentences varying in plausibility. Human plausibility judgments provide a benchmark for model performance. Various prompt-based methods were employed to assess explicit prompting abilities against implicit LL-based measurements.
Key Results
- LL vs. Prompting: LL scores consistently outperform prompt-based evaluations in capturing semantic plausibility, indicating a direct relationship between LL and inherent plausibility.
- Base vs. Instruction-Tuned Models: Instruction-tuned models generally show less consistency with human plausibility judgments compared to their base counterparts, suggesting potential downsides of instruction-tuning in this context.
- Human Comparison: While LLMs demonstrate above-chance performance, they fall short of human capabilities, especially in complex scenarios involving animate protagonists.
Experiment 2: Context-Dependent Plausibility
The study extends its analysis to context-dependent plausibility judgments, investigating the modulation of semantic plausibility by contextual information in LLMs.
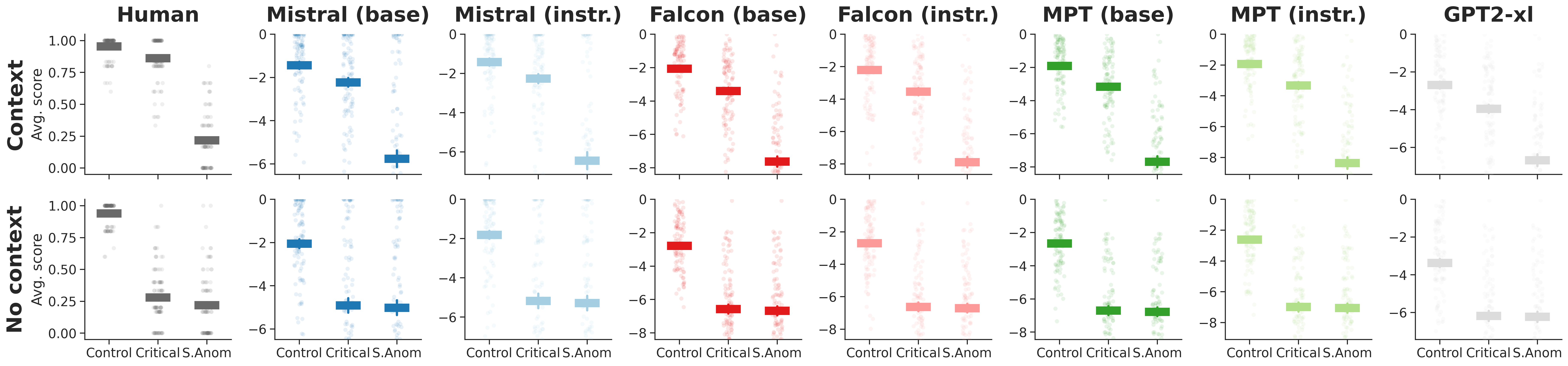
Figure 2: Target word LLs replicate patterns of human sentence sensibility judgments.
Methodology
A dataset consisting of three contexts (Control, SemAnom, and Critical) is used to evaluate context sensitivity. The study measures both target word and sentence LLs to determine how context influences plausibility assessments.
Findings
- Word vs. Sentence LLs: Target word LLs show greater modulation by context compared to entire sentences, aligning more closely with human judgment patterns.
- Context Sensitivity: Models adjust plausibility judgments based on contextual cues but exhibit limitations in sentence-level predictions post-encountering anomalous stimuli.
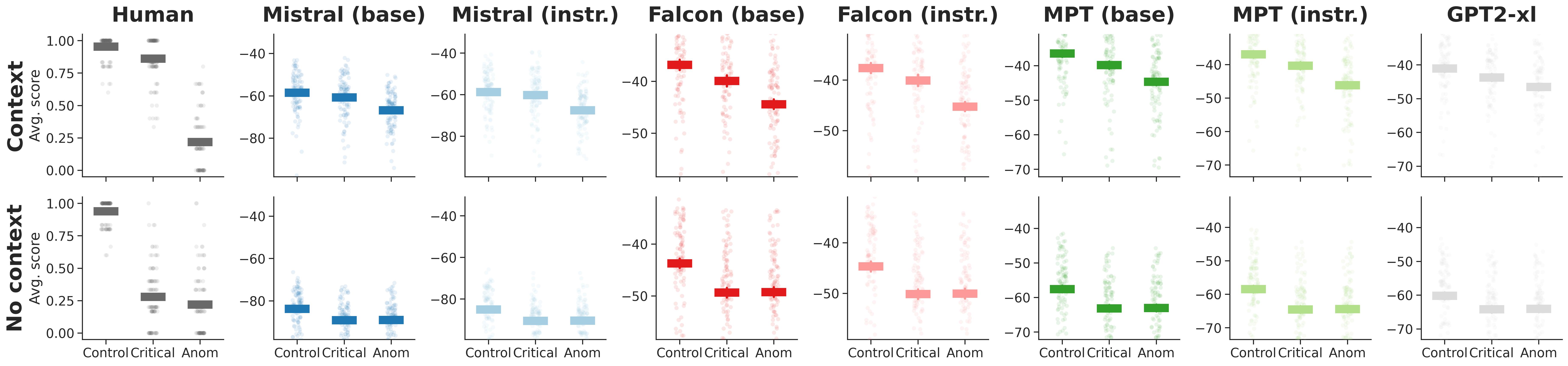
Figure 3: Replicating the sensibility-judgment task in LLMs using sentence LL measures. Human data from \citet{jouravlev2019tracking}.
Conclusion
The paper concludes that LL is a reliable measure of semantic plausibility in LLMs, providing a robust metric that surpasses many prompt-based methods, particularly in base models. Despite advances in instruction-tuning, these adjustments may not always enhance semantic plausibility alignment with human judgment. The findings suggest a continued role for LL evaluations in understanding LLMs' implicit knowledge.
The study highlights the need for further research on optimizing instruction-tuning processes to preserve or enhance the coherence with human semantic expectations. Additionally, improvements in LLM context sensitivity could enhance their application in real-world scenarios where context is vital for accurate language understanding.

