- The paper presents a dynamic, multi-stage framework that combines a planner, an RL agent, and a reasoner for enhanced visual reasoning.
- It employs iterative instruction sampling and state memory to adapt decisions based on historical feedback, achieving 48.6% accuracy on OK-VQA.
- Experimental evaluations across OK-VQA, RefCOCO, and GQA demonstrate HYDRA's robust performance and generalizability in complex visual tasks.
HYDRA: A Hyper Agent for Dynamic Compositional Visual Reasoning
Introduction
Visual reasoning (VR) involves constructing a representation of a visual scene and reasoning through it, often in response to textual queries or prompts. This area of research has been enhanced by the use of Large Vision-LLMs (VLMs), but these require significant datasets and computational resources. Moreover, monolithic approaches struggle with generalization across diverse tasks. Compositional visual reasoning addresses these limitations by decomposing tasks into simpler components, leveraging commonsense knowledge encoded in LLMs.
HYDRA is a dynamic multi-stage compositional visual reasoning framework that combines a planner, a reasoner, and a reinforcement learning (RL) agent to interact dynamically during the reasoning process. This design enhances decision-making by adapting actions based on historical feedback, improving overall effectiveness.
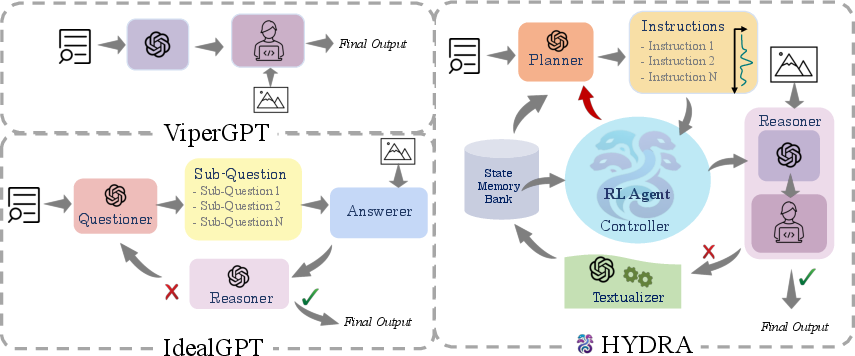
Figure 1: An overview of HYDRA showing its interaction modules for compositional visual reasoning.
Framework Design
HYDRA is composed of key modules: the planner, controller (RL agent), reasoner, and textualizer, supplemented by a State Memory Bank and meta information. The planner generates instruction samples based on the input query and historical state information. The RL agent evaluates and selects the optimum instruction to proceed with the reasoning task. Unsuccessful outputs are processed into text by the textualizer for future iterations.
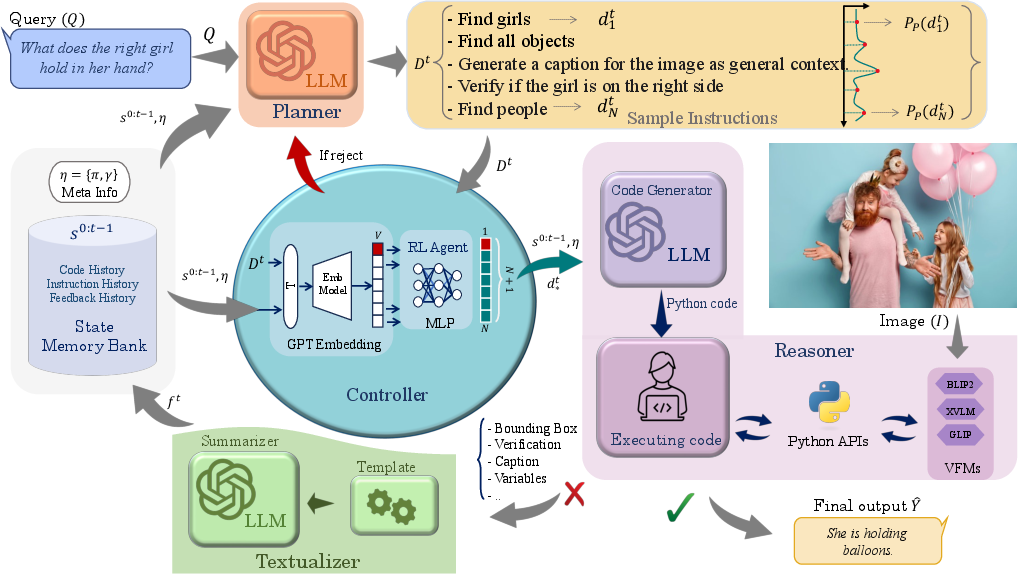
Figure 2: Detailed design of HYDRA illustrating the flow of information between modules.
In this setup, HYDRA dynamically synthesizes perception outputs using both LLMs and visual foundation models (VFMs). The RL agent plays a critical role by making decisions about the validity of instruction samples, allowing the framework to adjust actions in real-time.
Experimental Evaluation
HYDRA was evaluated on several visual reasoning tasks across diverse datasets: OK-VQA for knowledge-dependent questions, RefCOCO for visual grounding, and GQA for compositional image question answering. Results indicate that HYDRA consistently outperforms existing state-of-the-art models across these tasks, demonstrating its robustness and adaptability. Notably, HYDRA achieved an accuracy of 48.6% on the OK-VQA dataset, marking significant improvement over previous models.
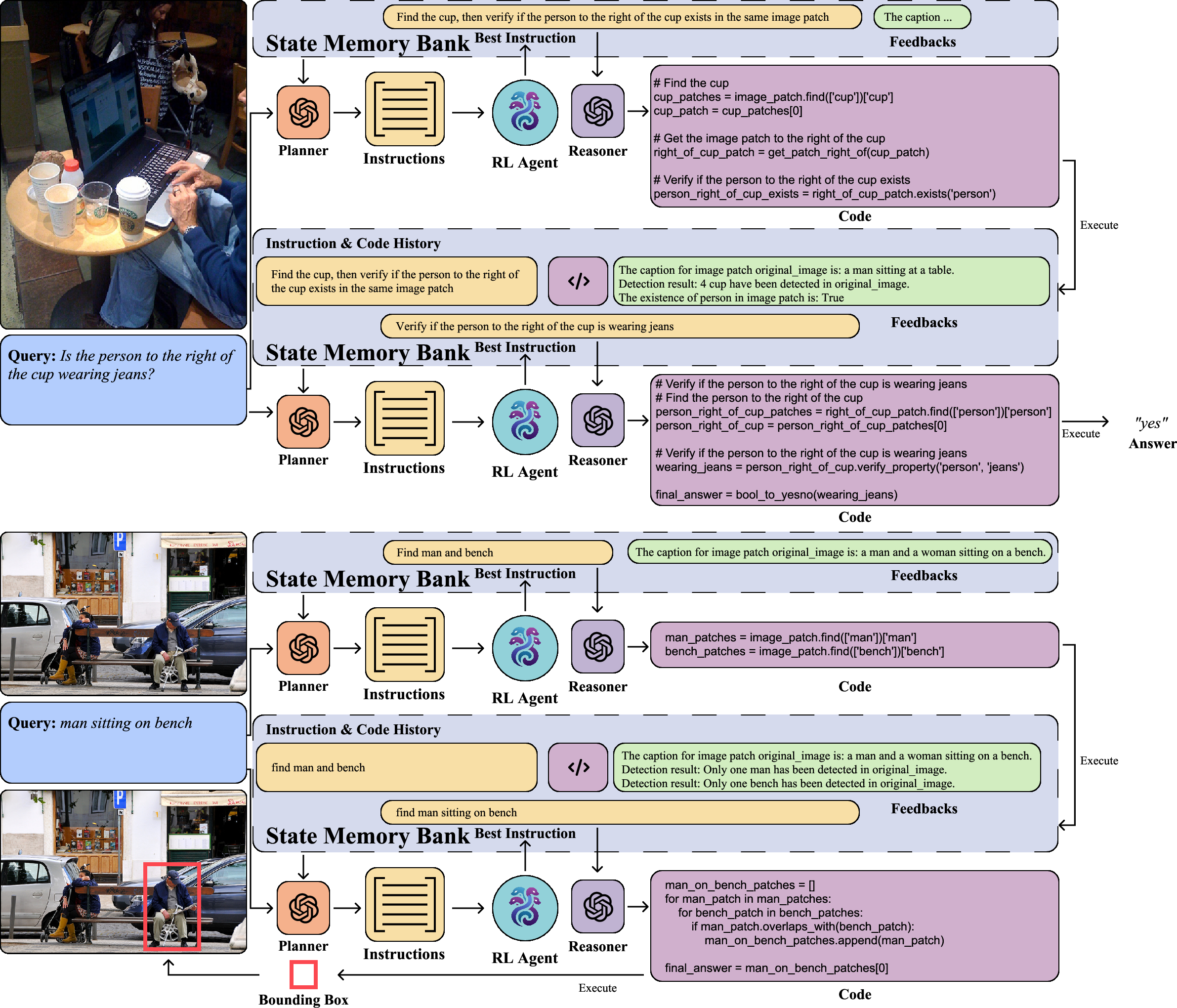
Figure 3: HYDRA's intermediate reasoning steps for visual question answering and visual grounding tasks.

Figure 4: Additional qualitative examples of HYDRA's application to visual tasks.
Key Contributions
- Incremental Reasoning: HYDRA stores information from previous states, refining its reasoning over multiple steps.
- Dynamic Interaction: The RL agent facilitates hyper decision-making, improving the framework's adaptability in complex scenarios.
- Instruction Sampling: HYDRA generates multiple instructional samples, each varying in complexity, enhancing decision quality.
Failure Analysis
While HYDRA achieves superior performance, complex scenarios can lead to failures if LLM-based modules make errors. Future development will focus on enhancing RL agent capabilities to mitigate such limitations.
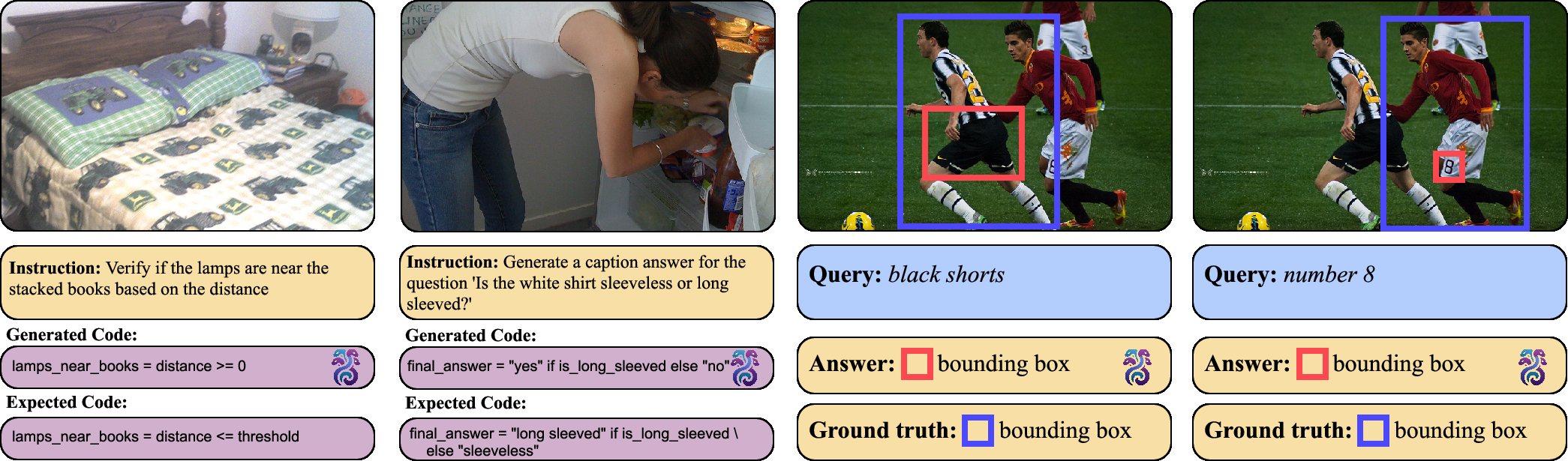
Figure 5: Example of a failure case highlighting areas for potential improvement.
Conclusion
HYDRA stands as a powerful framework for dynamic compositional visual reasoning, combining effective instruction generation, reasoning, and reinforcement learning to improve adaptability and decision-making in visual tasks. Future work will aim to fine-tune its modules for further robustness and explore additional interactions to enhance overall finding efficacy.