- The paper introduces VideoAgent, which integrates structured temporal and object memory to enhance video reasoning and understanding.
- It employs unified memory components using tools like LaViLa, ViCLIP, RT-DETR, and SQL-based querying to efficiently process video segments.
- VideoAgent outperforms baselines on benchmarks such as EgoSchema, Ego4D NLQ, and NExT-QA, demonstrating robust long-term temporal reasoning.
VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding
Introduction
The paper "VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding" introduces a sophisticated approach for tackling video understanding tasks, specifically addressing the challenge of capturing long-term temporal relations in lengthy videos. Traditional end-to-end video-LLMs often struggle to handle extensive spatial-temporal details, leading to performance bottlenecks. To overcome these limitations, the authors propose VideoAgent, a memory-augmented multimodal system that efficiently integrates and processes video data using structured memory representations.
Methodology
VideoAgent operates through a unified memory framework that structures video data into two primary components: temporal memory and object memory.
Temporal Memory
Temporal memory stores event-level descriptions extracted from short video segments. This is achieved by leveraging LaViLa, a video captioning model, which processes 2-second video segments to generate detailed captions. Additionally, ViCLIP is employed to derive video segment features which, in tandem with the caption embeddings, populate the temporal memory.
Object Memory
Object memory enhances video understanding by tracking objects and persons across video frames, ensuring temporally consistent details. This memory is constructed using an object detection pipeline (RT-DETR combined with ByteTrack) and an object re-identification (re-ID) process. The re-ID component uses an ensemble of CLIP and DINOv2 features to eliminate duplications and reliably identify objects across various frames.
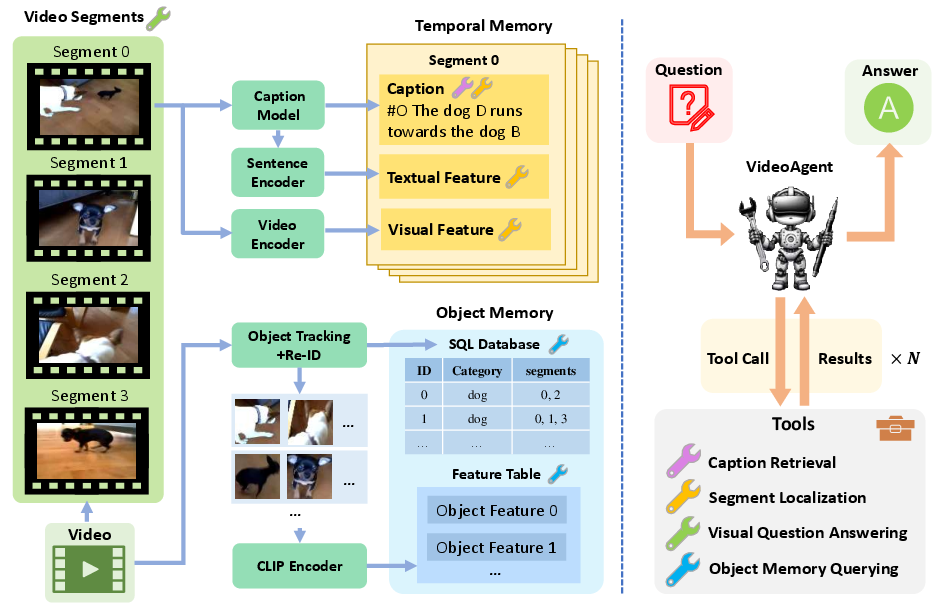
Figure 1: An overview of VideoAgent. Left: structured video representations; Right: tool interaction for task-solving.
VideoAgent employs a set of carefully curated tools designed for memory interaction and task execution.
- Caption Retrieval: Accesses specific event descriptions from the temporal memory for given video segments.
- Segment Localization: Identifies relevant video segments through similarity scoring between query text and both video and caption features.
- Visual Question Answering: Utilizes Video-LLaVA to extract additional information from specific video segments.
- Object Memory Querying: Executes complex queries on the object memory using SQL, assisting in sophisticated object-related analyses.
The inference process is iterative, where the system selects and applies tools based on task requirements until an optimal solution is derived.
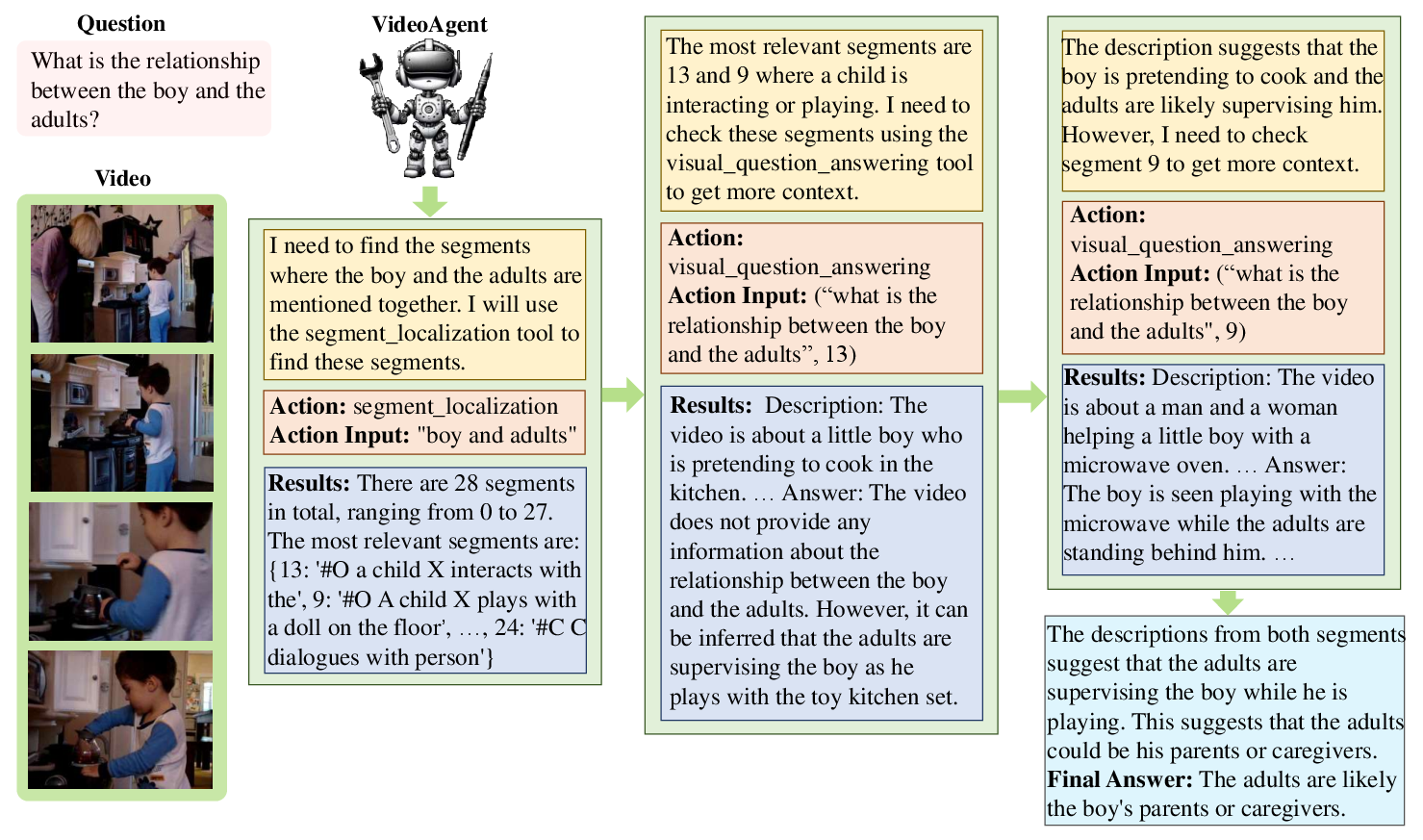
Figure 2: Example of VideoAgent inference, highlighting multiple tool-use steps.
VideoAgent's capabilities were rigorously tested across multiple benchmark datasets, including EgoSchema, Ego4D NLQ, and NExT-QA.
EgoSchema
VideoAgent showcased impressive results, achieving significant accuracy improvements over competitors like Video-LLaVA and mPLUG-Owl, with an accuracy of 62.8% on the EgoSchema subset. Its structured memory enhanced reasoning ability, particularly on complex video-level reasoning tasks.
Ego4D NLQ
In the Ego4D NLQ task, VideoAgent outperformed several baselines such as 2D-TAN and VSLNet. It demonstrated strong zero-shot performance, particularly with its ensemble approach to segment localization.
NExT-QA
For the diverse question types in NExT-QA, VideoAgent excelled in causal questions requiring temporal reasoning, surpassing state-of-the-art models and illustrating the effectiveness of its unified memory strategy.
Conclusion
VideoAgent integrates advanced LLMs with a novel memory architecture to significantly advance the field of video understanding. By focusing on structured memory representations and strategic tool use, VideoAgent offers a scalable solution for processing extensive video data, providing insights that are well-suited for real-world applications in complex environments. Future work may explore expanded applications across new domains, further enhancing the capabilities of multimodal agents.