- The paper introduces the cRSSM, a novel approach that integrates context directly into the latent dynamics of the Dreamer architecture to boost zero-shot generalization.
- The methodology evaluates cRSSM against baseline methods on CartPole and DMC Walker, demonstrating significant performance gains especially in pixel-based observation scenarios.
- The paper also highlights counterfactual dreaming and latent disentanglement, enabling synthetic environment rollouts that enhance sample efficiency and adaptability in RL.
Contextual World Models for Zero-Shot Generalization in RL
Motivation and Problem Setting
Zero-shot generalization (ZSG) in reinforcement learning remains a critical challenge, especially for model-based reinforcement learning (MBRL) agents expected to perform in previously unseen, parameter-shifted environments. This work studies ZSG in the contextual reinforcement learning (cRL) paradigm where context variables parametrizing the underlying dynamics (such as gravity or pole length) are observable. The focus is on analyzing and improving the Dreamer architecture's ability to generalize in both in-distribution and out-of-distribution (OOD) scenarios by leveraging context-aware world modeling.
The paper proposes the contextual recurrent state-space model (cRSSM), which extends the DreamerV3 architecture with explicit context conditioning. In cRSSM, context variables are introduced at each stage in both the generative and inference models of Dreamer's world model. This modification allows context to directly influence the latent Markovian state inference, latent dynamics, observation, and reward prediction, without altering the overall network topology.
The key probabilistic components are:
- Deterministic state: ht=fθ(ht−1,zt−1,at−1,c)
- Stochastic state: zt∼pθ(zt∣ht)
- Observation model: Conditioned on both ht, zt, and c
- Reward model: Similarly conditioned
Systematic context integration ensures that the latent space is disentangled with respect to context, supporting both observed and counterfactual context inference ("dreaming of many worlds").
Baselines and Naive Context Integration
The evaluation contrasts cRSSM with several baselines:
- Default-context: Training on a single default context value.
- Hidden-context (domain randomization): No explicit context integration; learning across varying, randomly sampled context values.
- Concat-context: Context is concatenated to observation vectors before encoding, requiring the model to implicitly retain context within the Markovian state representation.
Experimental Protocol and Generalization Tasks
Experiments are conducted on the Contextual CARL RL benchmark using CartPole and DMC Walker environments. Evaluation spans:
- Single context variation: Training with variation in one context parameter
- Dual context variation: Sampling from joint context parameter distributions
- Observation modalities: Both standard featurized (state-based) and pixel-based input
Evaluation regions include strict interpolation (within training support), mixed interpolation/extrapolation (OOD in one factor), and challenging full extrapolation (OOD in all factors).
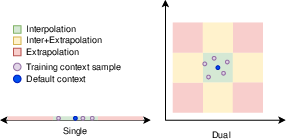
Figure 2: Training contexts and evaluation regions for single and dual context variation.
Quantitative Analysis: Zero-Shot Policy Generalization
Strong numerical results demonstrate:
- Domain randomization (hidden-context) outperforms default-context in all generalization settings, particularly pronounced in pixel-based observation scenarios.
- Explicit context conditioning (cRSSM, concat-context) consistently yields higher OOD generalization than hidden-context. In pixel-based CartPole, cRSSM achieves significantly higher reward in extrapolated pole lengths and gravity settings.
Pixel-based results highlight the advantage of principled context integration, with cRSSM outperforming concat-context and hidden-context by a substantial margin in nontrivial extrapolation scenarios.
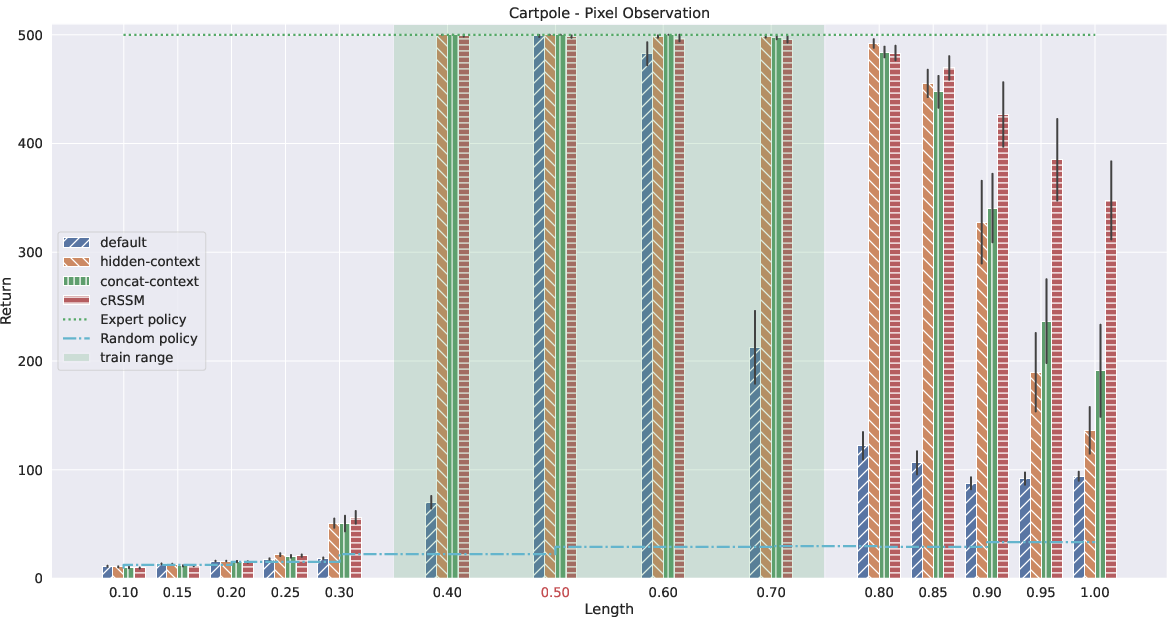
Figure 1: Generalization capabilities of Dreamer with pixel-observations when varying the pole length in CartPole; cRSSM achieves near-expert rewards at OOD pole lengths.
Aggregate metrics (IQM normalized to expert and random baselines), show context-aware models achieving high reliability and confidence in both interpolation and extrapolation:


Figure 3: Feature based IQM for aggregated comparison across methods and generalization settings.
Counterfactual Dreaming and Latent Disentanglement
A unique aspect of cRSSM is the capability for "counterfactual" imagination: encoding a latent trajectory from context cF, then decoding or simulating under cCF. Qualitative visualizations show that cRSSM produces semantically correct OOD reconstructions (e.g., CartPole scenes with novel pole lengths), whereas concat-context fails to adjust reconstructions outside its training data manifold.


Figure 4: Qualitative results for model generative ability on novel context—cRSSM enables true counterfactual dreams with minimal error in extrapolation and maximal deviation in true counterfactuals.
This demonstrates that cRSSM achieves a meaningful disentanglement, using context as the ground truth for generative modeling of the environment, in line with theoretical desiderata for OOD robustness.
Implications and Future Directions
The explicit modeling of context within the world model architecture is necessary for OOD robustness in high-dimensional settings, with significant implications for scalable, robust RL deployment in the real world. The counterfactual dream capability opens further avenues:
- Extension to hidden (inferred) contexts: Real-world settings will often lack direct access to variable parameters, requiring latent context inference.
- Data augmentation via counterfactual rollouts: Synthetic experience generation conditioned on novel contexts can further enhance zero-/few-shot adaptation and improve sample efficiency.
- Benchmarking RL generalization: The methodology and evaluation protocol raise the standard for robust RL research beyond narrow in-domain success.
Conclusion
This work provides strong evidence that systematic, architecture-level context integration in world models is essential for robust zero-shot policy generalization in partially observable, parameter-varying MDPs. The cRSSM extension to Dreamer enables agents to achieve OOD generalization far beyond prior baselines, supports meaningful counterfactual inference, and substantially advances the methodological toolkit for general RL research and deployment (2403.10967).