- The paper introduces an agent-based framework where an LLM directs iterative frame selection, achieving 54.1% and 71.3% zero-shot accuracy on EgoSchema and NExT-QA respectively.
- The paper employs a human-like reasoning process by using VLMs to convert frames to text and CLIP models for dynamic information retrieval, significantly enhancing frame efficiency.
- The paper demonstrates improved prediction accuracy on both short and hour-long videos compared to uniform sampling and baseline approaches such as GPT-4V.
Introduction
"VideoAgent" explores the use of LLMs as central agents in video understanding tasks. The research introduces VideoAgent, which iteratively searches through long-form videos to gather information necessary for answering questions. Its core novelty lies in deploying an LLM to manage this iterative search, with vision-LLMs (VLMs) and contrastive language-image models (CLIPs) acting as tools for information retrieval and translation. By simulating the human cognitive approach to video understanding, VideoAgent demonstrates the potential of agent-based systems, achieving superior zero-shot accuracy over existing methods on the EgoSchema and NExT-QA benchmarks.
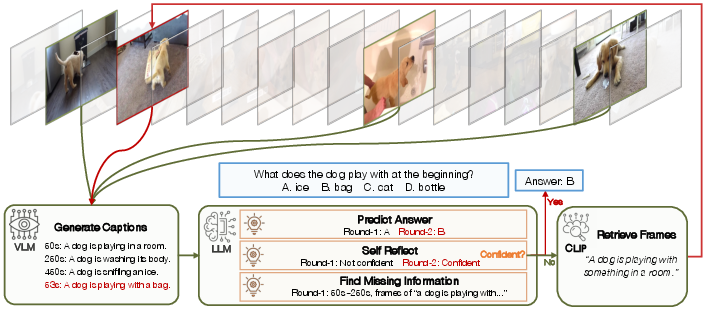
Figure 1: Overview of VideoAgent. Given a long-form video, VideoAgent iteratively searches and aggregates key information to answer the question. The process is controlled by a LLM as the agent, with the visual LLM (VLM) and contrastive language-image model (CLIP) serving as tools.
Methodology
The development of VideoAgent is centered around an iterative approach that mirrors human reasoning strategies. The system operates by performing a series of state, action, and observation steps:
- State: The current comprehension of the video based on viewed frames.
- Action: Determining whether to answer or seek additional frames.
- Observation: Acquiring new frames if further information is needed (Figure 2).
To begin, VideoAgent uses VLMs to convert video frames into textual descriptions, thereby establishing the initial state. Subsequently, an LLM is employed to predict an answer and assess if the current information is adequate. If insufficient, VideoAgent identifies what information is still needed and retrieves additional frames using CLIP models. This process aptly reduces the frames to process and is looped until the model can confidently provide an answer.
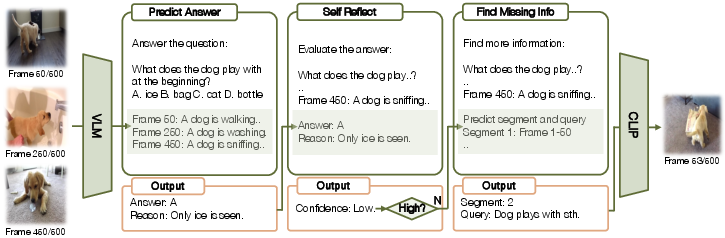
Figure 2: Detailed view of VideoAgent's iterative process. Each round starts with the state, which includes previously viewed video frames. The LLM then determines subsequent actions by answering prediction and self-reflection. If additional information is needed, new observations are acquired in the form of video frames.
Experimental Results
VideoAgent was rigorously tested against two benchmarks: EgoSchema and NExT-QA. It achieved 54.1% and 71.3% zero-shot accuracy on these datasets respectively, utilizing merely 8.4 and 8.2 frames on average. This outperforming efficiency underscores its superior ability to identify and gather relevant information.
The proposed iterative frame selection strategy enhances frame efficiency, significantly surpassing both uniform sampling methods and other baselines (Figure 3, left).
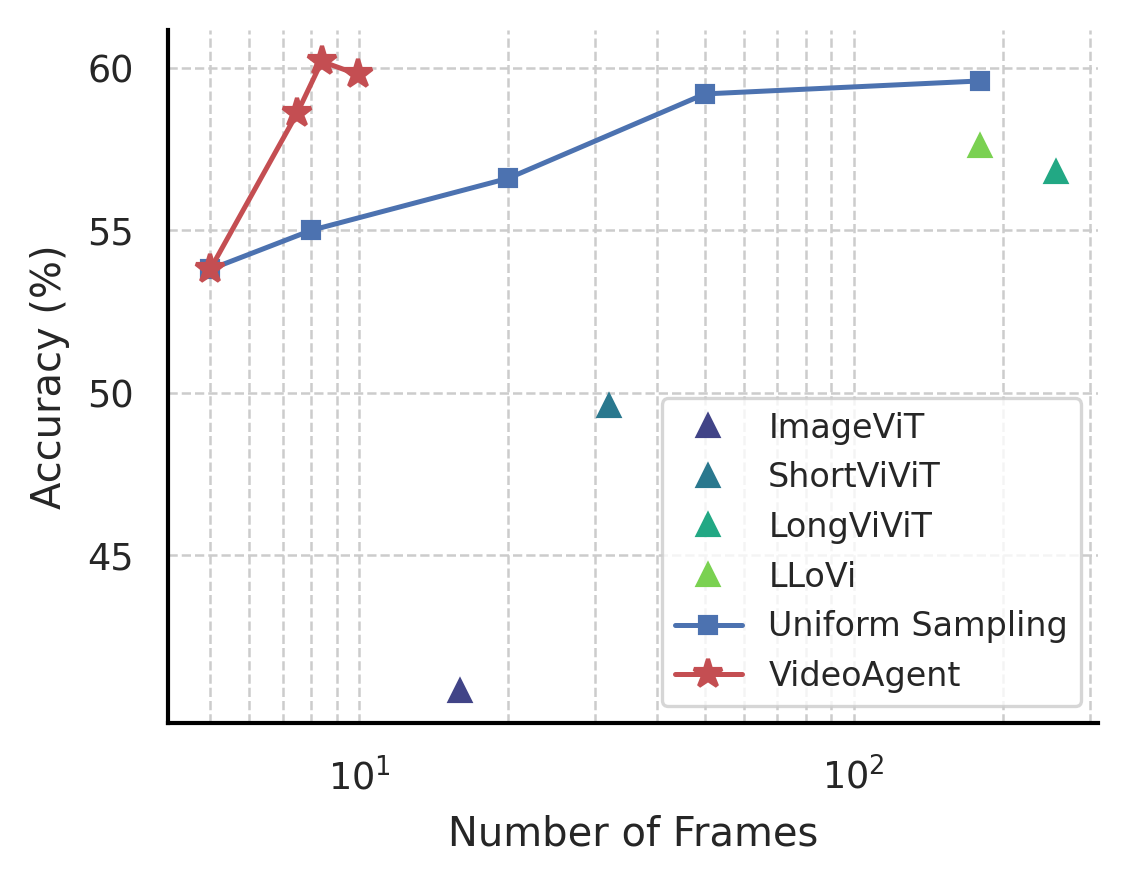
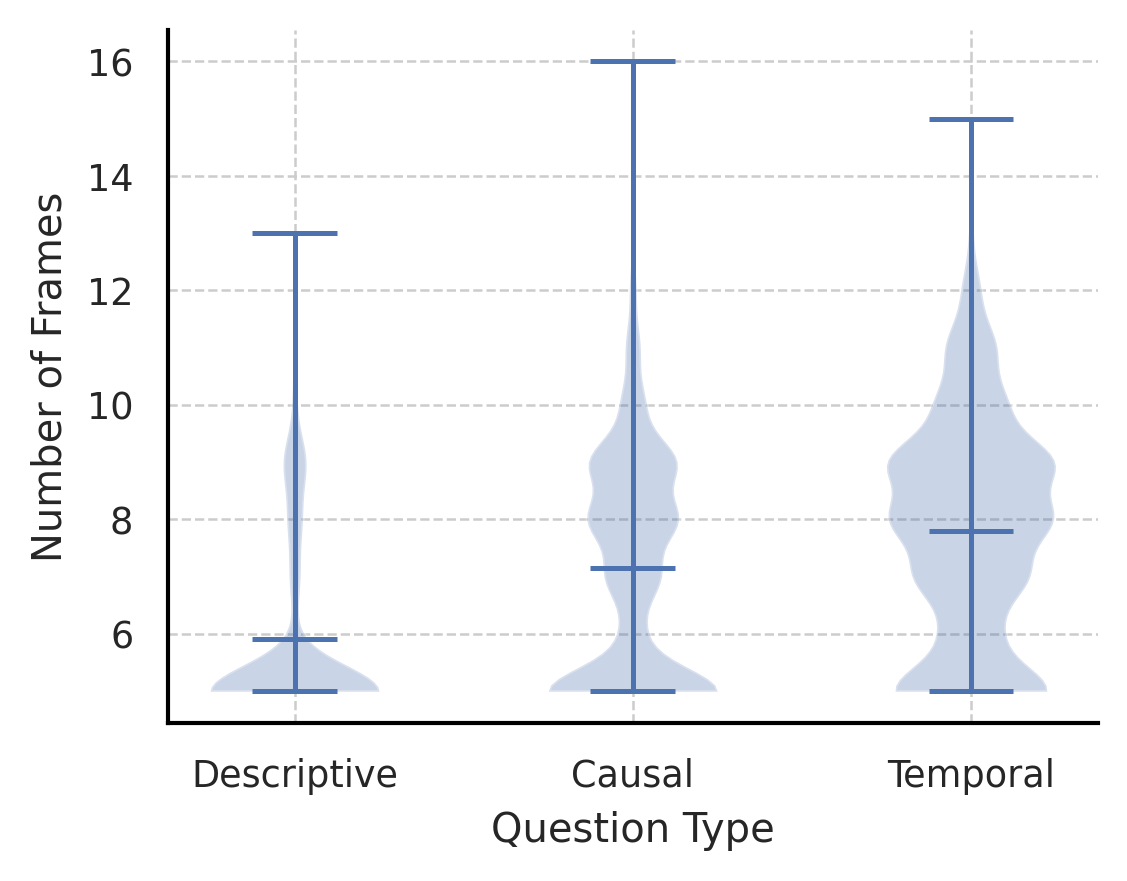
Figure 3: (Left) Frame efficiency compared to uniform sampling and previous methods. X-axis is in log scale. Our method achieves exceptional frame efficiency for long-form video understanding. (Right) Number of frames for different types of NExT-QA questions. Min, mean, max, distribution are plotted. VideoAgent selects more frames on questions related to temporal reasoning than causal reasoning and descriptive questions.
Case Studies
Case studies further illustrate the effectiveness of VideoAgent. In NExT-QA tests, VideoAgent adeptly identified missing information and required frames iteratively to bridge information gaps, leading to accurate predictions (Figure 4). It also demonstrated proficiency in processing hour-long YouTube videos, achieving correct frame identification and enhanced prediction accuracy in comparison to baseline approaches like GPT-4V (Figure 5).

Figure 4: Case study on NExT-QA. VideoAgent accurately identifies missing information in the first round, bridges the information gap in the second round, and thereby makes the correct prediction.

Figure 5: Case study on hour-long videos. VideoAgent accurately identifies the key frame during the second iteration, subsequently making an accurate prediction. Conversely, GPT-4V, when relying on 48 uniformly sampled frames up to its maximum context length, does not get successful prediction. However, by integrating the frame pinpointed by VideoAgent, GPT-4V is able to correctly answer the question.
Conclusion
VideoAgent has introduced a novel agent-based framework capped by its capability to mimic human reasoning in long-form video understanding. The approach not only sets new benchmarks for performance but also highlights the value of iterative and adaptive frame selection. Future developments could focus on refining these methods further or integrating more advanced LLMs to potentially move beyond caption-based systems for even greater efficiencies in video understanding tasks.

