A Structure-Preserving Kernel Method for Learning Hamiltonian Systems
Published 15 Mar 2024 in stat.ML, cs.LG, and math.DS | (2403.10070v2)
Abstract: A structure-preserving kernel ridge regression method is presented that allows the recovery of nonlinear Hamiltonian functions out of datasets made of noisy observations of Hamiltonian vector fields. The method proposes a closed-form solution that yields excellent numerical performances that surpass other techniques proposed in the literature in this setup. From the methodological point of view, the paper extends kernel regression methods to problems in which loss functions involving linear functions of gradients are required and, in particular, a differential reproducing property and a Representer Theorem are proved in this context. The relation between the structure-preserving kernel estimator and the Gaussian posterior mean estimator is analyzed. A full error analysis is conducted that provides convergence rates using fixed and adaptive regularization parameters. The good performance of the proposed estimator together with the convergence rate is illustrated with various numerical experiments.
The paper presents a novel structure-preserving kernel ridge regression that reliably recovers Hamiltonian functions from noisy observations.
It extends the Representer Theorem to a differential setting, yielding a closed-form, convex estimator that preserves the symplectic structure of the dynamics.
The method achieves superior performance and lower computational cost compared to neural approaches, with rigorous error bounds and convergence guarantees.
Structure-Preserving Kernel Methods for Learning Hamiltonian Systems
Introduction and Problem Setting
This work introduces a structure-preserving kernel ridge regression approach for learning Hamiltonian systems from noisy vector field observations. The primary goal is to recover potentially high-dimensional and nonlinear Hamiltonian functions from finite, noise-corrupted samples of Hamiltonian vector fields. The method is designed to guarantee that the learned vector field is genuinely Hamiltonian, as opposed to approaches that may violate the symplectic or gradient structure required by Hamiltonian dynamics.
The inverse problem targeted is: Given samples {z(n),xσ2(n)}n=1N, where each z(n) is a state in phase space and xσ2(n) is a noisy observation of the Hamiltonian vector field at z(n), infer the underlying scalar-valued Hamiltonian H. The observed data obeys
xσ2(n)=J∇H(z(n))+ε(n),
where J is the canonical symplectic matrix and ε(n) is noise with variance σ2.
The proposed learning strategy constrains the hypothesis class to Hamiltonian vector fields Xh=J∇h with h restricted to a Reproducing Kernel Hilbert Space (RKHS) HK. The estimation problem is formulated as
A central technical contribution is the extension of the Representer Theorem to this structure-preserving context, leading to what the authors denote as the "Differential Representer Theorem". This results in a closed-form solution for the estimator,
hλ,N=i=1∑N⟨ci,∇1K(z(i),⋅)⟩,
where c is computed using a differential Gram matrix involving derivatives of the kernel. The solution is convex and unique due to the positive semidefiniteness of the differential Gram matrix.
Connection to Gaussian Process Regression
The authors establish conditions under which the posterior mean of a Gaussian process regression (GPR) with a suitable kernel and noise model coincides with the structure-preserving kernel estimator. Specifically, when λ=Nσ2, the GPR posterior mean and the structure-preserving kernel estimate coincide, even though the regression loss involves gradients due to the Hamiltonian structure: ϕN=hλ,N=N1(AN∗AN+λI)−1AN∗xσ2,N
where AN encodes the action of the symplectic gradient at each data point.
This equivalence is only valid when the regularization/noise relationship is precisely matched, which the authors highlight as a subtlety not addressed in earlier works claiming broader GPR equivalence.
Error Analysis and Convergence Rates
A detailed error and convergence analysis is provided using both Γ-convergence and operator techniques:
1. PAC bounds for a fixed λ:
The estimator converges in RKHS norm to the ground truth as the number of samples increases, under mild smoothness assumptions.
2. Rates with adaptive regularization (λ∼N−α):
The estimator converges at rate
∥hλ,N−H∥HK≲N−min{αγ,21(1−3α)},
for α∈(0,31) and γ determined by a source smoothness condition.
Under an additional coercivity assumption linking L2 and RKHS norms, rates improve to allow larger α<1/2.
3. Flow Approximation Guarantees:
Theoretical guarantees are given that the learned Hamiltonian induces flows close to those generated by the true Hamiltonian, in the sup norm over initial conditions and time, with explicit dependence on RKHS error.
Differential Reproducing Property and Structure
A central analytical component is the formulation and proof of a differential reproducing property for differentiable kernels on unbounded domains. For a sufficiently regular kernel K, gradients and higher derivatives of functions in HK remain in the RKHS and satisfy their own reproducing identities. This property is critical to defining the learning problem in a mathematically rigorous fashion and proves robust enough for non-compact domains with Gaussian kernels and certain Sobolev kernels.
Numerical Experiments
The numerical study demonstrates superior performance of the structure-preserving kernel estimator in a range of classical, non-convex, and singular Hamiltonian systems. For instance:
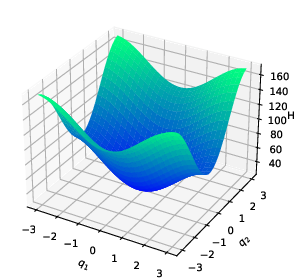
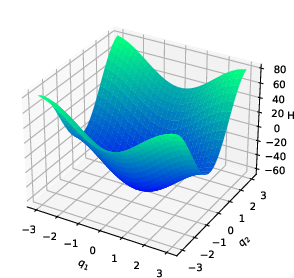
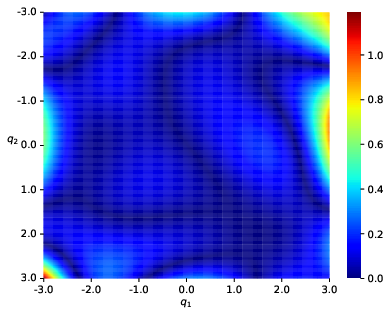
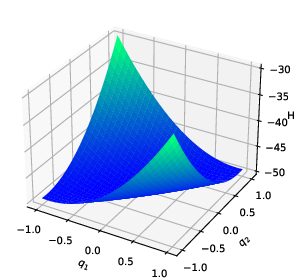
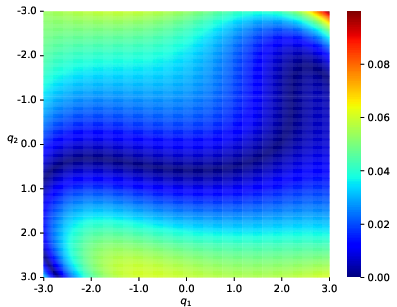
Double pendulum system: The estimated potential closely matches ground truth, with low error in the region populated by data.
Figure 1: Double pendulum—ground truth, reconstruction, and error after vertical shift.
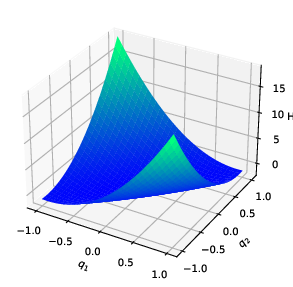
Non-convex potentials and systems with singularities: Even with highly non-convex or singular potentials, the method captures qualitative features and achieves lower reconstruction error compared to Hamiltonian neural network (HNN) methods particularly when training data is limited or the objective function is highly non-convex.
Noise robustness and sample complexity: Experiments across noise levels and sample sizes confirm the quantitative error bounds and convergence behavior predicted theoretically.
Comparison with HNNs: The kernel method achieves lower error and dramatically lower computational cost than HNNs that require iterative gradient optimization.
Implications and Perspectives
The structure-preserving kernel regression paradigm offers several theoretical and practical advantages:
Guaranteed Structure: By construction, all learned vector fields are Hamiltonian, preserving invariants and symplectic geometry.
Closed-form Solutions: The convexity and closed-form estimator distinguishes this approach from neural network methods, which may require heuristics to enforce structure and are sensitive to initialization.
Theoretical Guarantees: The analysis covers both finite and infinite data regimes, providing sharp error and convergence rates depending on kernel and system regularity.
Generalizability: The formalism can be extended beyond Hamiltonian systems to any dynamics where the vector field is a linear action on function gradients, potentially handling generalized gradient flows and port-Hamiltonian systems.
Further theoretical advances may extend this framework to systems on manifolds, controlled systems, and statistical learning from trajectory (as opposed to vector field) data, necessitating an overview with symplectic and variational integrator theory.
Conclusion
This paper formulates and solves the structure-preserving learning of Hamiltonian systems via a kernel ridge regression approach, with strong theoretical guarantees and practical advantages for high-dimensional nonlinear systems. Its closed-form solution, rigorous error bounds, and superior empirical performance with small datasets position it as a robust alternative to neural net-based approaches for learning physical dynamical systems (2403.10070).
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.