CodeUltraFeedback: An LLM-as-a-Judge Dataset for Aligning Large Language Models to Coding Preferences
(2403.09032)Abstract
Evaluating the alignment of LLMs with user-defined coding preferences is a challenging endeavour that requires assessing intricate textual LLMs' outputs. By relying on automated metrics and static analysis tools, existing benchmarks fail to assess nuances in user instructions and LLM outputs, highlighting the need for large-scale datasets and benchmarks for LLM preference alignment. In this paper, we introduce CodeUltraFeedback, a preference dataset of 10,000 complex instructions to tune and align LLMs to coding preferences through AI feedback. We generate responses to the instructions using a pool of 14 diverse LLMs, which we then annotate according to their alignment with five coding preferences using the LLM-as-a-Judge approach with GPT-3.5, producing both numerical and textual feedback. We also present CODAL-Bench, a benchmark for assessing LLM alignment with these coding preferences. Our results show that CodeLlama-7B-Instruct, aligned through reinforcement learning from AI feedback (RLAIF) with direct preference optimization (DPO) using CodeUltraFeedback's AI feedback data, outperforms 34B LLMs on CODAL-Bench, validating the utility of CodeUltraFeedback for preference tuning. Furthermore, we show our DPO-aligned CodeLlama model improves functional correctness on HumanEval+ compared to the unaligned base model. Therefore, our contributions bridge the gap in preference tuning of LLMs for code and set the stage for further advancements in model alignment and RLAIF for code intelligence. Our code and data are available at https://github.com/martin-wey/CodeUltraFeedback.
Overview
-
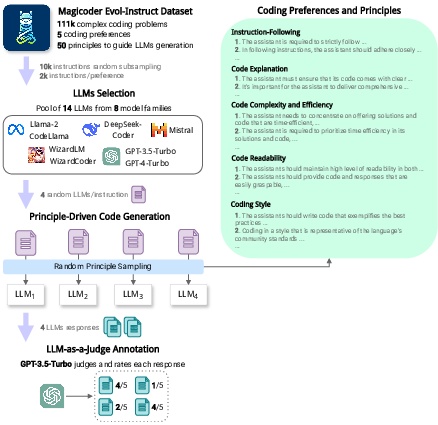
The paper introduces CodeUltraFeedback, a dataset with 10,000 instructions aimed at aligning LLMs with coding preferences, and CODAL-Bench, a benchmark for evaluating LLMs against coding preferences like readability and efficiency.
-
It emphasizes the need for benchmarks that account for non-functional requirements (coding preferences) in LLM-generated code, which influence the code's quality, maintainability, and performance.
-
Through initial experiments with models like GPT-3.5-Turbo and GPT-4-Turbo, it was found that CodeUltraFeedback effectively judges and enhances the alignment of LLMs with coding preferences.
-
Further experiments showed that by using CodeUltraFeedback for Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), smaller LLMs could achieve better alignment with coding preferences, even outperforming larger models.
Aligning LLMs to Coding Preferences: Introducing CodeUltraFeedback and CODAL-Bench
Introduction to CodeUltraFeedback and CODAL-Bench
Recent advancements have significantly extended the capabilities of LLMs in the domain of code generation, presenting new challenges and opportunities in aligning these models with specific coding preferences. A paramount issue in current research is the assessment of LLM-generated code, particularly in the context of non-functional requirements such as code readability, efficiency, and adherence to best practices. Traditional benchmarks do not adequately address these criteria, focusing instead on functional correctness or using rigid metrics that fail to capture the nuanced requirements of developers and users. In this paper, we present CodeUltraFeedback, a preference dataset containing 10,000 complex instructions, and CODAL-Bench, a benchmark constructed for evaluating LLM alignment over five coding preferences, including instruction following, code explanation, complexity and efficiency, readability, and coding style.
The Significance of Coding Preferences
Coding preferences, often encompassing non-functional requirements, significantly influence the quality, maintainability, and performance of code. Yet, existing methodologies for evaluating LLMs largely overlook these aspects. This gap highlights the necessity for approaches tailored to measure and tune LLMs according to such preferences. By focusing on a diversified set of preferences, our work aims to bring LLMs closer to meeting developer expectations, thereby enhancing the utility of their generated code in practical scenarios.
Constructing CodeUltraFeedback
The creation of CodeUltraFeedback involves a multistep process, starting with the definition of coding preferences and corresponding principles. The dataset includes responses from 14 diverse LLMs to complex instructions across the defined preferences, annotated using an LLM-as-a-Judge approach with GPT-3.5. This approach ensures both numerical ratings and textual feedback, providing a rich basis for understanding and improving LLM alignment with coding preferences. The methodology for dataset construction emphasizes the importance of diversity in LLM responses and the nuanced assessment of their alignment with coding preferences, setting the stage for comprehensive preference tuning.
The Role of CODAL-Bench
CODAL-Bench is introduced as a means to thoroughly evaluate the alignment of LLMs with the defined coding preferences. Through a meticulous single-answer grading scheme, CODAL-Bench leverages advanced LLMs such as GPT-3.5-Turbo or GPT-4-Turbo as judges, offering a nuanced approach to benchmarking. This strategy moves beyond the limitations of automated metrics and external tools commonly used in other benchmarks, enabling a more refined evaluation of LLM-generated code from a human-centric perspective.
Empirical Insights from Initial Experiments
Our exploration into CodeUltraFeedback's annotations underscores the robust judging capabilities of GPT-3.5-Turbo, which consistently recognized the superior quality of responses from LLMs like GPT-4-Turbo. These findings not only validate the efficacy of CodeUltraFeedback for preference tuning but also suggest an inherent lack of alignment in a majority of tested LLMs, including some of the more sophisticated models.
Advancing LLM Alignment with Coding Preferences
Further experiments demonstrate that tuning a smaller LLM, CodeLlama-7B-Instruct, using CodeUltraFeedback with Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), significantly enhances alignment with coding preferences. This improvement is evident across all preferences on CODAL-Bench, outstripping larger LLMs and underscoring the potential of our approach in refining model alignment. Moreover, this alignment process also results in better functional correctness, as measured on benchmarks such as HumanEval+, showcasing the dual benefits of our tuning methodology.
Conclusion and Outlook
By introducing CodeUltraFeedback and CODAL-Bench, our work takes a significant step toward addressing the challenges of aligning LLMs with coding preferences. The insights garnered from our empirical analyses affirm the utility of these resources in enhancing the capabilities of LLMs to meet developer expectations. As we look to the future, we envision expanded research into LLM tuning and evaluation methodologies, leveraging the foundational contributions of our work to foster further advancements in code intelligence.
Our materials, including models, datasets, benchmarks, and prompt templates, are openly available for researchers and practitioners interested in exploring and advancing the alignment of LLMs with coding preferences. We anticipate that the continued development and refinement of such resources will pave the way for more intuitive, efficient, and functionally robust code generation capabilities in LLMs.