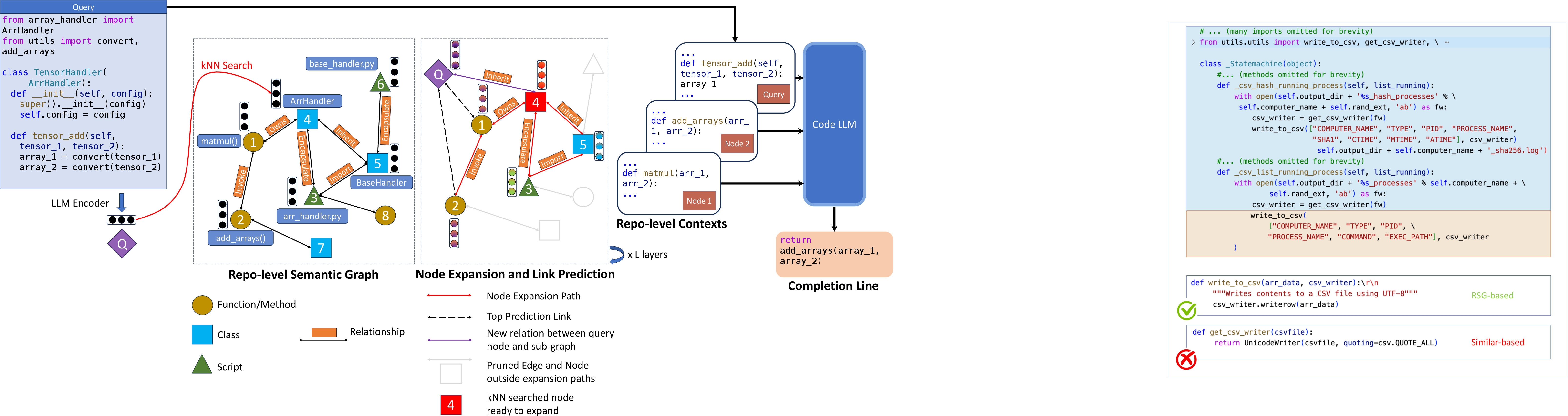
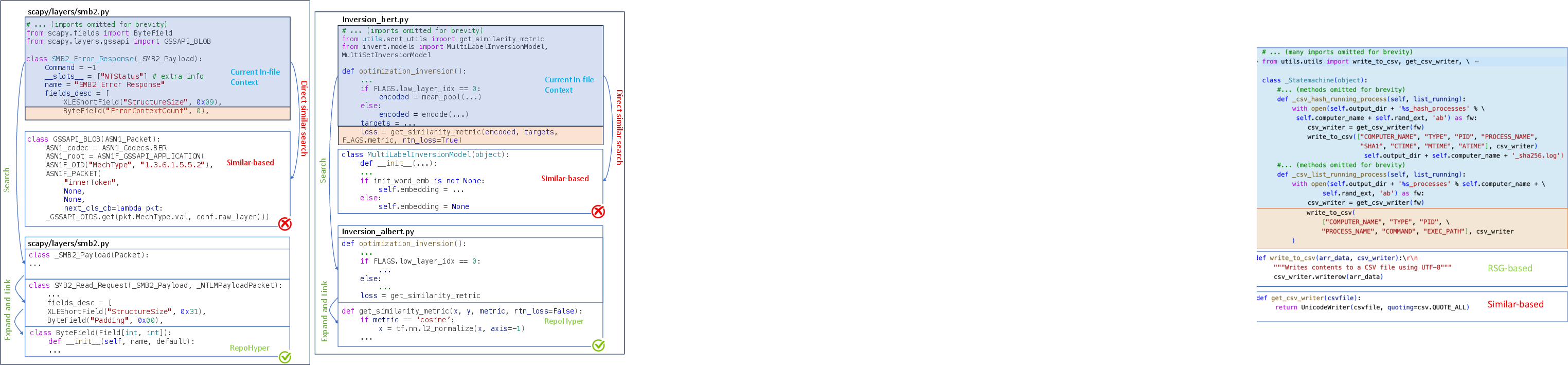
RepoHyper: Search-Expand-Refine on Semantic Graphs for Repository-Level Code Completion
Abstract: Code LLMs (CodeLLMs) have demonstrated impressive proficiency in code completion tasks. However, they often fall short of fully understanding the extensive context of a project repository, such as the intricacies of relevant files and class hierarchies, which can result in less precise completions. To overcome these limitations, we present \tool, a multifaceted framework designed to address the complex challenges associated with repository-level code completion. Central to RepoHYPER is the {\em Repo-level Semantic Graph} (RSG), a novel semantic graph structure that encapsulates the vast context of code repositories. Furthermore, RepoHyper leverages Expand and Refine retrieval method, including a graph expansion and a link prediction algorithm applied to the RSG, enabling the effective retrieval and prioritization of relevant code snippets. Our evaluations show that \tool markedly outperforms existing techniques in repository-level code completion, showcasing enhanced accuracy across various datasets when compared to several strong baselines. Our implementation of RepoHYPER can be found at https://github.com/FSoft-AI4Code/RepoHyper.
- Guiding language models of code with global context using monitors. arXiv preprint arXiv:2306.10763.
- Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Codeplan: Repository-level coding using llms and planning. arXiv preprint arXiv:2309.12499.
- Codetf: One-stop transformer library for state-of-the-art code llm. arXiv preprint arXiv:2306.00029.
- Evaluating large language models trained on code.
- Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595.
- Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691.
- Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359.
- Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion. arXiv preprint arXiv:2310.11248.
- Cocomic: Code completion by jointly modeling in-file and cross-file context. arXiv preprint arXiv:2212.10007.
- Unixcoder: Unified cross-modal pre-training for code representation. arXiv preprint arXiv:2203.03850.
- Deepseek-coder: When the large language model meets programming – the rise of code intelligence.
- Inductive representation learning on large graphs. In NIPS.
- Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938.
- Starcoder: may the source be with you!
- Context-aware code generation framework for code repositories: Local, global, and third-party library awareness. arXiv preprint arXiv:2312.05772.
- Repobench: Benchmarking repository-level code auto-completion systems.
- Repocoder: Repository-level code completion through cross-file context retrieval. arXiv preprint arXiv:2303.12570.
- Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568.
- OpenDialKG: Explainable conversational reasoning with attention-based walks over knowledge graphs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 845–854, Florence, Italy. Association for Computational Linguistics.
- Codegen2: Lessons for training llms on programming and natural languages. arXiv preprint arXiv:2305.02309.
- Codegen: An open large language model for code with multi-turn program synthesis.
- Carbon emissions and large neural network training.
- Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409.
- Codebleu: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297.
- Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Repofusion: Training code models to understand your repository.
- Repository-level prompt generation for large language models of code. In ICML 2022 Workshop on Knowledge Retrieval and Language Models.
- Repository-level prompt generation for large language models of code. In International Conference on Machine Learning, pages 31693–31715. PMLR.
- CodeT5+: Open code large language models for code understanding and generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1069–1088, Singapore. Association for Computational Linguistics.
- Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. arXiv preprint arXiv:2109.00859.
- Rlpg: A reinforcement learning based code completion system with graph-based context representation. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2021, page 1119–1129, New York, NY, USA. Association for Computing Machinery.
- Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. arXiv preprint arXiv:2401.07339.
- Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

