A Safe Harbor for AI Evaluation and Red Teaming
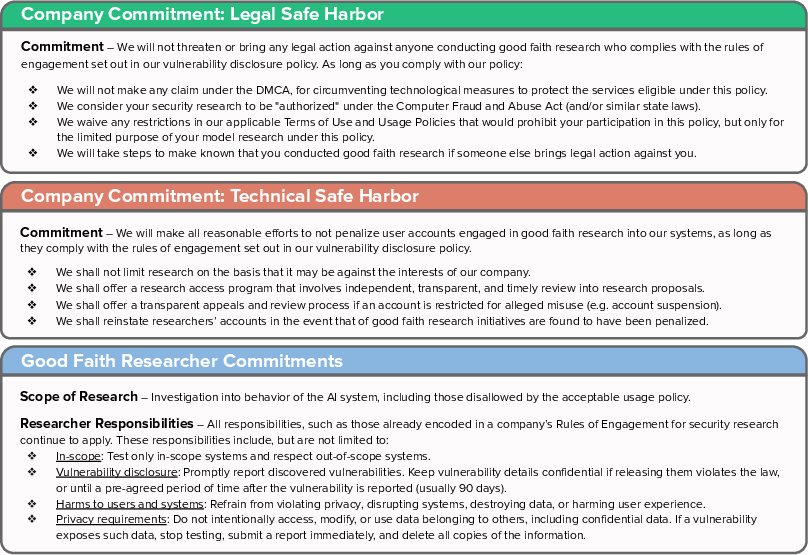
Abstract: Independent evaluation and red teaming are critical for identifying the risks posed by generative AI systems. However, the terms of service and enforcement strategies used by prominent AI companies to deter model misuse have disincentives on good faith safety evaluations. This causes some researchers to fear that conducting such research or releasing their findings will result in account suspensions or legal reprisal. Although some companies offer researcher access programs, they are an inadequate substitute for independent research access, as they have limited community representation, receive inadequate funding, and lack independence from corporate incentives. We propose that major AI developers commit to providing a legal and technical safe harbor, indemnifying public interest safety research and protecting it from the threat of account suspensions or legal reprisal. These proposals emerged from our collective experience conducting safety, privacy, and trustworthiness research on generative AI systems, where norms and incentives could be better aligned with public interests, without exacerbating model misuse. We believe these commitments are a necessary step towards more inclusive and unimpeded community efforts to tackle the risks of generative AI.
- Research threats: Legal threats against security researchers. https://github.com/disclose/research-threats, 2021.
- A safe harbor for platform research. Knight Columbia, 1 2022. URL https://knightcolumbia.org/content/a-safe-harbor-for-platform-research.
- Ada Lovelace Institute. Post-summit civil society communique, 11 2023. URL https://www.adalovelaceinstitute.org/news/post-summit-civil-society-communique/.
- Bug hunters’ perspectives on the challenges and benefits of the bug bounty ecosystem. In 32nd USENIX Security Symposium (USENIX Security). https://doi. org/10.48550/arXiv, volume 2301, 2023.
- Frontier ai regulation: Managing emerging risks to public safety, 2023.
- Anthropic. Core views on ai safety: When, why, what, and how. https://www.anthropic.com/news/core-views-on-ai-safety, 3 2023a.
- Anthropic. Frontier threats red teaming for ai safety. Anthropic, 7 2023b. URL https://www.anthropic.com/index/frontier-threats-red-teaming-for-ai-safety.
- Anthropic. Responsible disclosure policy, December 2023. URL https://www.anthropic.com/responsible-disclosure-policy.
- Barclay, L. Facebook banned me for life because i help people use it less, 10 2021. URL https://slate.com/technology/2021/10/facebook-unfollow-everything-cease-desist.html.
- Barrabi, T. Sam altman — who warned ai poses ‘risk of extinction’ to humanity — is also a ‘doomsday prepper’. New York Post, 6 2023. URL https://nypost.com/2023/06/05/sam-altman-who-warned-ai-poses-risk-of-extinction-to-humanity-is-also-a-doomsday-prepper/.
- Belanger, A. 100+ researchers say they stopped studying x, fearing elon musk might sue them. https://arstechnica.com/tech-policy/2023/11/100-researchers-say-they-stopped-studying-x-fearing-elon-musk-might-sue-them/, 11 2023.
- Ai auditing: The broken bus on the road to ai accountability, 2024.
- Blog, G. Rebooting responsible disclosure: a focus on protecting end users. https://security.googleblog.com/2010/07/rebooting-responsible-disclosure-focus.html, 7 2010.
- Emergent autonomous scientific research capabilities of large language models, 2023.
- The foundation model transparency index, 2023a.
- Improving transparency in ai language models: A holistic evaluation. Foundation Model Issue Brief Series, 2023b. URL https://hai.stanford.edu/foundation-model-issue-brief-series.
- Commission on information disorder final report. Technical report, Aspen Institute, November 2021. URL https://www.aspeninstitute.org/wp-content/uploads/2021/11/Aspen-Institute_Commission-on-Information-Disorder_Final-Report.pdf. Recommendations for transparency.
- Brittain, B. OpenAI says New York Times ’hacked’ ChatGPT to build copyright lawsuit. Reuters, Feb 2024. URL https://www.reuters.com/technology/cybersecurity/openai-says-new-york-times-hacked-chatgpt-build-copyright-lawsuit-2024-02-27/.
- Brodkin, J. Missouri threatens to sue a reporter who flagged a security flaw. https://www.wired.com/story/missouri-threatens-sue-reporter-state-website-security-flaw/, 10 2021.
- Structured access for third-party research on frontier ai models: Investigating researchers’ model access requirements, 2023. URL https://www.governance.ai/research-paper/structured-access-for-third-party-research-on-frontier-ai-models.
- Bugcrowd. Vulnerability disclosure policy: What is it & why is it important? Bugcrowd Blog, 12 2023. URL https://www.bugcrowd.com/blog/vulnerability-disclosure-policy-what-is-it-why-is-it-important/.
- Artificial influence: An analysis of ai-driven persuasion. arXiv preprint arXiv:2303.08721, 2023.
- Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pp. 2633–2650, 2021.
- Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23), pp. 5253–5270, 2023.
- Black-box access is insufficient for rigorous ai audits, 2024.
- CFAA. Computer Fraud and Abuse Act. 18 U.S.C. § 1030, 1986.
- Jailbreaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419, 2023.
- Colannino, J. The copyright office expands your security research rights. https://github.blog/2021-11-23-copyright-office-expands-security-research-rights/, 23 2021.
- Commission, F. T. The ftc voice cloning challenge. https://www.ftc.gov/news-events/contests/ftc-voice-cloning-challenge, 2023.
- Who audits the auditors? recommendations from a field scan of the algorithmic auditing ecosystem. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, pp. 1571–1583, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450393522. doi: 10.1145/3531146.3533213. URL https://doi.org/10.1145/3531146.3533213.
- DeLong, L. A. Facebook disables ad observatory; academicians and journalists fire back. NYU Center for Cybersecurity, 8 2021. URL https://cyber.nyu.edu/2021/08/21/facebook-disables-ad-observatory-academicians-and-journalists-fire-back/.
- Department of Justice. Department of justice announces new policy for charging cases under the computer fraud and abuse act. Press Release, 5 2022. URL https://www.justice.gov/opa/pr/department-justice-announces-new-policy-charging-cases-under-computer-fraud-and-abuse-act.
- Toxicity in chatgpt: Analyzing persona-assigned language models. arXiv preprint arXiv:2304.05335, 2023.
- It’s time to open the black box of social media. https://www.scientificamerican.com/article/its-time-to-open-the-black-box-of-social-media/, 4 2022. 5 min read.
- DMCA. Digital Millennium Copyright Act. 17 U.S.C. § 1201, 1998a.
- DMCA. Digital millennium copyright act. 17 U.S.C. § 1204(a), 1998b.
- Douglas Heaven, W. How to make a chatbot that isn’t racist or sexist. MIT Technology Review, 10 2020. URL https://www.technologyreview.com/2020/10/23/1011116/chatbot-gpt3-openai-facebook-google-safety-fix-racist-sexist-language-ai/.
- Elazari, A. We Need Bug Bounties for Bad Algorithms, May 2018a. URL https://www.vice.com/en/article/8xkyj3/we-need-bug-bounties-for-bad-algorithms.
- Elazari, A. Hacking the law: Are bug bounties a true safe harbor? In Enigma 2018 (Enigma 2018), 2018b.
- Elazari, A. Private ordering shaping cybersecurity policy: The case of bug bounties. An edited, final version of this paper in Rewired: Cybersecurity Governance, Ryan Ellis and Vivek Mohan eds. Wiley, 2019.
- Coming in from the cold: A safe harbor from the cfaa and the dmca §1201 for security researchers. Berkman Klein Center Research Publication No. 2018-4. Assembly Publication Series, Berkman Klein Center for Internet & Society, Harvard University, 2018. URL http://nrs.harvard.edu/urn-3:HUL.InstRepos:37135306.
- European Council. Proposal for a regulation of the european parliament and of the council laying down harmonised rules on artificial intelligence (artificial intelligence act) and amending certain union legislative acts, 2024. URL https://data.consilium.europa.eu/doc/document/ST-5662-2024-INIT/en/pdf.
- Is tricking a robot hacking? Berkeley Technology Law Journal, 34(3):891–918, 2019.
- Executive Office of the President. Safe, secure, and trustworthy development and use of artificial intelligence. Executive Order, 10 2023. URL https://www.federalregister.gov/documents/2023/10/30/2023-24110/safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence. Federal Register Vol. 88, No. 210 (October 30, 2023).
- Llm agents can autonomously hack websites. arXiv preprint arXiv:2402.06664, 2024.
- Ai red-teaming is not a one-stop solution to ai harms: Recommendations for using red-teaming for ai accountability. Data & Society, 10 2023. URL https://datasociety.net/library/ai-red-teaming-is-not-a-one-stop-solution-to-ai-harms-recommendations-for-using-red-teaming-for-ai-accountability/.
- Mart: Improving llm safety with multi-round automatic red-teaming. arXiv preprint arXiv:2311.07689, 2023.
- Generative ai has an intellectual property problem. Harvard Business Review, 04 2023. URL https://hbr.org/2023/04/generative-ai-has-an-intellectual-property-problem.
- Asymmetric ideological segregation in exposure to political news on facebook. Science, 381(6656):392–398, 2023. doi: 10.1126/science.ade7138. URL https://www.science.org/doi/abs/10.1126/science.ade7138.
- Greene, T. C. Sdmi cracks revealed. https://www.theregister.com/2001/04/23/sdmi_cracks_revealed/, 4 2001.
- The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work. The New York Times, Dec 2023. URL https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html.
- Gupta, R. Laion and the challenges of preventing ai-generated csam. https://www.techpolicy.press/laion-and-the-challenges-of-preventing-ai-generated-csam/, 1 2024.
- Hacker, P. Comments on the final trilogue version of the ai act, January 2023. URL https://media.licdn.com/dms/document/media/D4E1FAQE9w01juCUvIw/feedshare-document-pdf-analyzed/0/1706022316786?e=1707350400&v=beta&t=PQMy2m6nOfRLfkHd4pO-ZJ0JJWvehexHNLmWJLgLYrA.
- HackerOne. Hackerone gold standard safe harbor. HackerOne, 2023. URL https://hackerone.com/security/safe_harbor.
- Introducing google’s secure ai framework, June 2023. URL https://blog.google/technology/safety-security/introducing-googles-secure-ai-framework/.
- Foundation models and fair use. arXiv preprint arXiv:2303.15715, 2023.
- An overview of catastrophic ai risks. arXiv preprint arXiv:2306.12001, 2023.
- The facebook files: A wall street journal investigation. https://www.wsj.com/articles/the-facebook-files-11631713039, 2021.
- Hu, K. Chatgpt sets record for fastest-growing user base - analyst note. Reuters, February 2023. URL https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/.
- Catastrophic jailbreak of open-source llms via exploiting generation, 2023a.
- Privacy implications of retrieval-based language models. arXiv preprint arXiv:2305.14888, 2023b.
- Inflection. Our policy on frontier safety, 2023. URL https://inflection.ai/frontier-safety.
- Innovation, Science and Economic Development Canada. Voluntary code of conduct on the responsible development and management of advanced generative ai systems, September 2023. URL https://ised-isde.canada.ca/site/ised/en/voluntary-code-conduct-responsible-development-and-management-advanced-generative-ai-systems.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
- Jonathan, S. Ny times sues openai, microsoft for infringing copyrighted works. Reuters, 12 2023. URL https://www.reuters.com/legal/transactional/ny-times-sues-openai-microsoft-infringing-copyrighted-work-2023-12-27/.
- On the societal impact of open foundation models. 2024.
- Bug bounties for algorithmic harms?, 2022. URL https://www.ajl.org/bugs.
- Understanding catastrophic forgetting in language models via implicit inference. arXiv preprint arXiv:2309.10105, 2023.
- Krawiec, K. D. Cosmetic compliance and the failure of negotiated governance. Wash. ULQ, 81:487, 2003.
- Lakatos, S. A revealing picture: Ai-generated ‘undressing’ images move from niche pornography discussion forums to a scaled and monetized online business. Technical report, Graphika, Dec 2023. URL https://public-assets.graphika.com/reports/graphika-report-a-revealing-picture.pdf.
- Lambert, N. Undoing rlhf and the brittleness of safe llms, 10 2023. URL https://www.interconnects.ai/p/undoing-rlhf.
- Multi-step jailbreaking privacy attacks on chatgpt. arXiv preprint arXiv:2304.05197, 2023a.
- Chatgpt as an attack tool: Stealthy textual backdoor attack via blackbox generative model trigger. arXiv preprint arXiv:2304.14475, 2023b.
- The time is now to develop community norms for the release of foundation models, 2022. URL https://crfm.stanford.edu/2022/05/17/community-norms.html.
- Holistic evaluation of language models. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=iO4LZibEqW. Featured Certification, Expert Certification.
- Goal-oriented prompt attack and safety evaluation for llms. arXiv e-prints, pp. arXiv–2309, 2023.
- The data provenance initiative: A large scale audit of dataset licensing & attribution in ai. arXiv preprint arXiv:2310.16787, 2023.
- Generative ai has a visual plagiarism problem. IEEE Spectrum, 1 2024. URL https://spectrum.ieee.org/midjourney-copyright.
- Black box adversarial prompting for foundation models. In The Second Workshop on New Frontiers in Adversarial Machine Learning, 2023.
- Meta. Overview of meta ai safety policies prepared for the uk ai safety summit, 2023. URL https://transparency.fb.com/en-gb/policies/ai-safety-policies-for-safety-summit/.
- Midjourney. Terms of service, December 2023. URL https://docs.midjourney.com/docs/terms-of-service.
- Conflicts of interest and the case of auditor independence: Moral seduction and strategic issue cycling. Academy of management review, 31(1):10–29, 2006.
- Mozilla. How safe are our online platforms? let’s open the door for social media researchers. https://foundation.mozilla.org/en/campaigns/unknown-influence/, 2023.
- Model alignment protects against accidental harms, not intentional ones, 12 2023a. URL https://www.aisnakeoil.com/p/model-alignment-protects-against.
- Generative ai companies must publish transparency reports, 2023b. URL https://knightcolumbia.org/blog/generative-ai-companies-must-publish-transparency-reports.
- Scalable extraction of training data from (production) language models. arXiv preprint arXiv:2311.17035, 2023.
- National Science Foundation. Democratizing the future of ai r&d: Nsf to launch national ai research resource pilot. https://new.nsf.gov/news/democratizing-future-ai-rd-nsf-launch-national-ai, 1 2024.
- https://www.longtermresilience.org/post/report-launch-examining-risks-at-the-intersection-of-ai-and-bio, 10 2023. URL https://www.longtermresilience.org/post/report-launch-examining-risks-at-the-intersection-of-ai-and-bio.
- NIST. Nist seeks collaborators for consortium supporting artificial intelligence safety, 2023. URL https://www.nist.gov/news-events/news/2023/11/nist-seeks-collaborators-consortium-supporting-artificial-intelligence.
- NIST. Test, evaluation & red-teaming, 2024. URL https://www.nist.gov/artificial-intelligence/executive-order-safe-secure-and-trustworthy-artificial-intelligence/test.
- OpenAI. Introducing chatgpt and whisper apis. 2023a. URL https://openai.com/blog/introducing-chatgpt-and-whisper-apis.
- OpenAI. Sharing and publication policy. https://openai.com/policies/sharing-publication-policy#research, 2023b.
- OpenAI. Researcher access program application, 2024. URL https://openai.com/form/researcher-access-program.
- An attacker’s dream? exploring the capabilities of chatgpt for developing malware. In Proceedings of the 16th Cyber Security Experimentation and Test Workshop, pp. 10–18, 2023.
- Supporting youth mental and sexual health information seeking in the era of artificial intelligence (ai) based conversational agents: Current landscape and future directions. Available at SSRN 4601555, 2023.
- Adversarial nibbler: A data-centric challenge for improving the safety of text-to-image models. arXiv preprint arXiv:2305.14384, 2023.
- Persily, N. A proposal for researcher access to platform data: The platform transparency and accountability act. Journal of Online Trust and Safety, 1(1), 2021.
- Pfefferkorn, R. America’s anti-hacking laws pose a risk to national security. https://www.brookings.edu/articles/americas-anti-hacking-laws-pose-a-risk-to-national-security/, 9 2021.
- Pfefferkorn, R. Shooting the messenger: Remediation of disclosed vulnerabilities as cfaa “loss”. Richmond Journal of Law & Technology, 29:89, 2022. URL https://jolt.richmond.edu/files/2022/11/Pfefferkorn-Manuscript-Final.pdf.
- Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693, 2023.
- Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. arXiv preprint arXiv:2305.13873, 2023.
- Outsider oversight: Designing a third party audit ecosystem for ai governance. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’22, pp. 557–571, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450392471. doi: 10.1145/3514094.3534181. URL https://doi.org/10.1145/3514094.3534181.
- Red-teaming the stable diffusion safety filter. arXiv preprint arXiv:2210.04610, 2022.
- From ChatGPT to HackGPT: Meeting the Cybersecurity Threat of Generative AI. MIT Sloan Management Review, 2023.
- Smoothllm: Defending large language models against jailbreaking attacks. arXiv preprint arXiv:2310.03684, 2023.
- Whose opinions do language models reflect? arXiv preprint arXiv:2303.17548, 2023.
- Scalable and transferable black-box jailbreaks for language models via persona modulation. In Socially Responsible Language Modelling Research, 2023.
- Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548, 2023.
- ” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models. arXiv preprint arXiv:2308.03825, 2023.
- Detecting pretraining data from large language models. In ICLR, 2024.
- Can large language models democratize access to dual-use biotechnology? arXiv preprint arXiv:2306.03809, 2023.
- Evaluating the social impact of generative ai systems in systems and society, 2023.
- Stupp, C. Fraudsters used ai to mimic ceo’s voice in unusual cybercrime case. https://www.wsj.com/articles/fraudsters-used-ai-to-mimic-ceos-voice-in-unusual-cybercrime-case-11567098001, 8 2019. WSJ PRO.
- The Coming Wave: Technology, Power, and the Twenty-First Century’s Greatest Dilemma. Penguin Random House, 2023.
- Sven Cattell. Generative red team recap, Oct 2023. URL https://aivillage.org/defcon%2031/generative-recap/.
- Tabassi, E. Artificial intelligence risk management framework (ai rmf 1.0), 2023-01-26 05:01:00 2023. URL https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=936225.
- The Hacking Policy Council, Dec 2023. URL https://assets-global.website-files.com/62713397a014368302d4ddf5/6579fcd1b821fdc1e507a6d0_Hacking-Policy-Council-statement-on-AI-red-teaming-protections-20231212.pdf.
- Generative ml and csam: Implications and mitigations, 2023. URL https://fsi.stanford.edu/publication/generative-ml-and-csam-implications-and-mitigations.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- United States Office of Management and Budget. Advancing governance, innovation, and risk management for agency use of artificial intelligence, October 2023. URL https://www.whitehouse.gov/wp-content/uploads/2023/11/AI-in-Government-Memo-draft-for-public-review.pdf.
- Dual use of artificial-intelligence-powered drug discovery. Nature Machine Intelligence, 4(3):189–191, 2022.
- Towards a greater understanding of coordinated vulnerability disclosure policy documents. Digital Threats: Research and Practice, 2023.
- Jailbroken: How does llm safety training fail? arXiv preprint arXiv:2307.02483, 2023.
- Sociotechnical safety evaluation of generative ai systems. ArXiv, abs/2310.11986, 2023. URL https://api.semanticscholar.org/CorpusID:264289156.
- Weiss, J. Petition for new exemption to section 1201 of the digital millenium copyright act: Exemption for security research pertaining to generative ai bias, June 2023. URL https://www.copyright.gov/1201/2024/petitions/proposed/New-Pet-Jonathan-Weiss.pdf.
- Whittaker, M. The steep cost of capture. Interactions, 28(6):50–55, 2021.
- Xiang, C. ’he would still be here’: Man dies by suicide after talking with ai chatbot, widow says. https://www.vice.com/en/article/pkadgm/man-dies-by-suicide-after-talking-with-ai-chatbot-widow-says, 3 2023.
- The earth is flat because…: Investigating llms’ belief towards misinformation via persuasive conversation. arXiv preprint arXiv:2312.09085, 2023.
- Shadow alignment: The ease of subverting safely-aligned language models. arXiv preprint arXiv:2310.02949, 2023.
- Low-resource languages jailbreak gpt-4. In Socially Responsible Language Modelling Research, 2023.
- Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts. arXiv preprint arXiv:2309.10253, 2023.
- Zalnieriute, M. “transparency-washing” in the digital age : A corporate agenda of procedural fetishism. Technical report, 2021. URL http://hdl.handle.net/11159/468588.
- How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms. arXiv preprint arXiv:2401.06373, 2024.
- Removing RLHF Protections in GPT-4 via Fine-Tuning. arXiv preprint arXiv:2311.05553, 2023.
- How language model hallucinations can snowball. arXiv preprint arXiv:2305.13534, 2023.
- Weak-to-strong jailbreaking on large language models, 2024.
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.
- Zuboff, S. The age of surveillance capitalism. In Social Theory Re-Wired, pp. 203–213. Routledge, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

