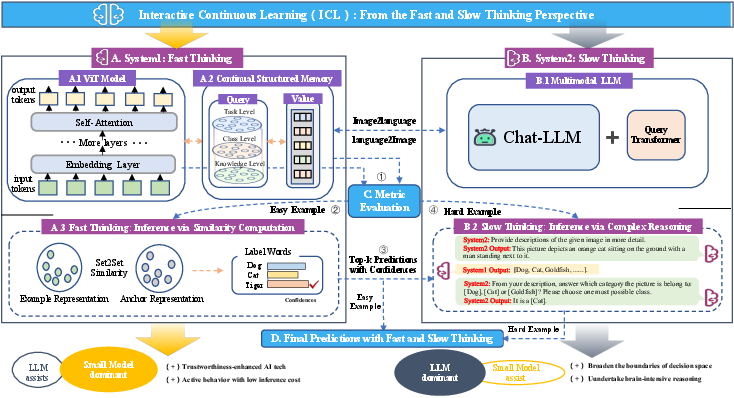
Interactive Continual Learning: Fast and Slow Thinking
Abstract: Advanced life forms, sustained by the synergistic interaction of neural cognitive mechanisms, continually acquire and transfer knowledge throughout their lifespan. In contrast, contemporary machine learning paradigms exhibit limitations in emulating the facets of continual learning (CL). Nonetheless, the emergence of LLMs presents promising avenues for realizing CL via interactions with these models. Drawing on Complementary Learning System theory, this paper presents a novel Interactive Continual Learning (ICL) framework, enabled by collaborative interactions among models of various sizes. Specifically, we assign the ViT model as System1 and multimodal LLM as System2. To enable the memory module to deduce tasks from class information and enhance Set2Set retrieval, we propose the Class-Knowledge-Task Multi-Head Attention (CKT-MHA). Additionally, to improve memory retrieval in System1 through enhanced geometric representation, we introduce the CL-vMF mechanism, based on the von Mises-Fisher (vMF) distribution. Meanwhile, we introduce the von Mises-Fisher Outlier Detection and Interaction (vMF-ODI) strategy to identify hard examples, thus enhancing collaboration between System1 and System2 for complex reasoning realization. Comprehensive evaluation of our proposed ICL demonstrates significant resistance to forgetting and superior performance relative to existing methods. Code is available at github.com/ICL.
- Memory aware synapses: Learning what (not) to forget. In Proceedings of the European Conference on Computer Vision (ECCV), pages 139–154, 2018.
- Clustering on the unit hypersphere using von mises-fisher distributions. J. Mach. Learn. Res., 6:1345–1382, 2005.
- Dark experience for general continual learning: a strong, simple baseline. Advances in neural information processing systems, 33:15920–15930, 2020.
- Rethinking experience replay: a bag of tricks for continual learning. In 2020 25th International Conference on Pattern Recognition (ICPR), pages 2180–2187. IEEE, 2021.
- A comprehensive survey of ai-generated content (aigc): A history of generative ai from gan to chatgpt. arXiv preprint arXiv:2303.04226, 2023.
- Efficient lifelong learning with a-gem. arXiv preprint arXiv:1812.00420, 2018.
- On tiny episodic memories in continual learning. arXiv preprint arXiv:1902.10486, 2019.
- An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Jonathan St BT Evans. In two minds: dual-process accounts of reasoning. Trends in cognitive sciences, 7(10):454–459, 2003.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8349, 2021.
- Learning a unified classifier incrementally via rebalancing. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 831–839, 2019.
- Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017.
- Learning multiple layers of features from tiny images. 2009.
- What learning systems do intelligent agents need? complementary learning systems theory updated. Trends in cognitive sciences, 20(7):512–534, 2016.
- Continual learning with extended kronecker-factored approximate curvature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9001–9010, 2020.
- Improving distributional similarity with lessons learned from word embeddings. Transactions of the Association for Computational Linguistics, 3:211–225, 2015.
- Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017.
- Rotate your networks: Better weight consolidation and less catastrophic forgetting. In 2018 24th International Conference on Pattern Recognition (ICPR), pages 2262–2268. IEEE, 2018.
- Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7765–7773, 2018.
- Piggyback: Adapting a single network to multiple tasks by learning to mask weights. In Proceedings of the European conference on computer vision (ECCV), pages 67–82, 2018.
- Weakly-supervised hierarchical text classification. In The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019, pages 6826–6833, 2019.
- The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects, 2013.
- Bilateral memory consolidation for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16026–16035, 2023.
- Hippocampal and neocortical contributions to memory: Advances in the complementary learning systems framework. Trends in cognitive sciences, 6(12):505–510, 2002.
- Continual learning by asymmetric loss approximation with single-side overestimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3335–3344, 2019.
- Dualnet: Continual learning, fast and slow. Advances in Neural Information Processing Systems, 34:16131–16144, 2021.
- Improving robustness of intent detection under adversarial attacks: A geometric constraint perspective. IEEE transactions on neural networks and learning systems, PP, 2023a.
- Improving robustness of intent detection under adversarial attacks: A geometric constraint perspective. IEEE Transactions on Neural Networks and Learning Systems, 2023b.
- Bns: Building network structures dynamically for continual learning. Advances in Neural Information Processing Systems, 34:20608–20620, 2021.
- icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017.
- The persistence and transience of memory. Neuron, 94(6):1071–1084, 2017.
- Learning to learn without forgetting by maximizing transfer and minimizing interference. arXiv preprint arXiv:1810.11910, 2018.
- Forgetting as a form of adaptive engram cell plasticity. Nature Reviews Neuroscience, 23(3):173–186, 2022.
- Gradient projection memory for continual learning. arXiv preprint arXiv:2103.09762, 2021.
- Sparse coding in a dual memory system for lifelong learning. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 9714–9722, 2023.
- Chatgpt: Optimizing language models for dialogue. OpenAI blog, 2022.
- Advani Sun, Weinan et al. Organizing memories for generalization in complementary learning systems. Nature neuroscience, 26(8):1438–1448, 2023.
- Layerwise optimization by gradient decomposition for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9634–9643, 2021.
- Gido M Van de Ven and Andreas S Tolias. Three scenarios for continual learning. arXiv preprint arXiv:1904.07734, 2019.
- A comprehensive survey of continual learning: Theory, method and application. arXiv preprint arXiv:2302.00487, 2023.
- Continual learning with lifelong vision transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 171–181, 2022a.
- Online continual learning with contrastive vision transformer. In ECCV, 2022b.
- Dualprompt: Complementary prompting for rehearsal-free continual learning. In ECCV, pages 631–648, 2022c.
- Learning to prompt for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 139–149, 2022d.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Memory consolidation or transformation: context manipulation and hippocampal representations of memory. Nature neuroscience, 10(5):555–557, 2007.
- Der: Dynamically expandable representation for class incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3014–3023, 2021.
- Continual learning through synaptic intelligence. In International Conference on Machine Learning, pages 3987–3995. PMLR, 2017.
- Triovecevent: Embedding-based online local event detection in geo-tagged tweet streams. pages 595–604, 2017.
- Infmllm: A unified framework for visual-language tasks, 2023.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper is about teaching AI to learn new things over time without forgetting what it already knows. The authors build a team of two kinds of AI “thinkers” that work together:
- System 1: a fast, instinctive image model (a Vision Transformer, or ViT) that quickly guesses what’s in a picture.
- System 2: a slow, careful “reasoner” (a multimodal LLM, like a version of ChatGPT that can look at images) that helps when the problem is hard.
Together, they aim to reduce “catastrophic forgetting,” which is when an AI learns a new skill and accidentally forgets old ones.
What questions are the researchers trying to answer?
They focus on three simple questions:
- Can a fast image model and a careful reasoning model work together so the AI keeps learning without forgetting old stuff?
- Can we design a memory system that stores what each class (like “cat,” “car,” “apple”) looks like, so learning new classes won’t overwrite old memories?
- Can the fast model know when it’s uncertain and ask the careful model for help on tough images?
How did they do it?
The team designed an “Interactive Continual Learning” (ICL) framework with three main ideas. Think of them as tools that help the two systems collaborate and remember better.
- Class-Knowledge-Task Attention (CKT-MHA): Imagine you’re studying with flashcards. You don’t just look at the picture—you also think about what you already know and what the assignment is asking. CKT-MHA does something similar: it mixes 1) what the image shows right now (class clues), 2) what the model already knows (knowledge), and 3) what the current task cares about, to make a better “question” for the memory to answer. This helps the fast model retrieve the right memory more reliably.
- CL-vMF: a better-shaped memory on a sphere
- Query memory (how to ask: the fast model’s parameters),
- Value memory (what’s stored: one vector per class).
- They update these in turn, like a two-step dance (a process similar to the EM algorithm): first tidy which class-centers should be where, then adjust how the model asks, so both stay aligned. This helps the model add new classes without messing up old ones.
- vMF-ODI: spotting hard cases and asking for help The fast model quickly scores how similar an image is to what it knows. If a picture looks too weird or the score is too low compared to others in the batch, it gets flagged as “hard.” For those, System 1 shares its top guesses with System 2, which then reasons more carefully (using language and image understanding) to make a final call. It’s like a student trying a question first, then asking a teacher only if needed—bringing along their best ideas.
In short:
- The fast model does quick, confident predictions and keeps lightweight, class-specific memories that grow over time.
- When it’s unsure, it calls the slow, reasoning model, giving it a shortlist to consider, which speeds up careful thinking.
What did they find, and why is it important?
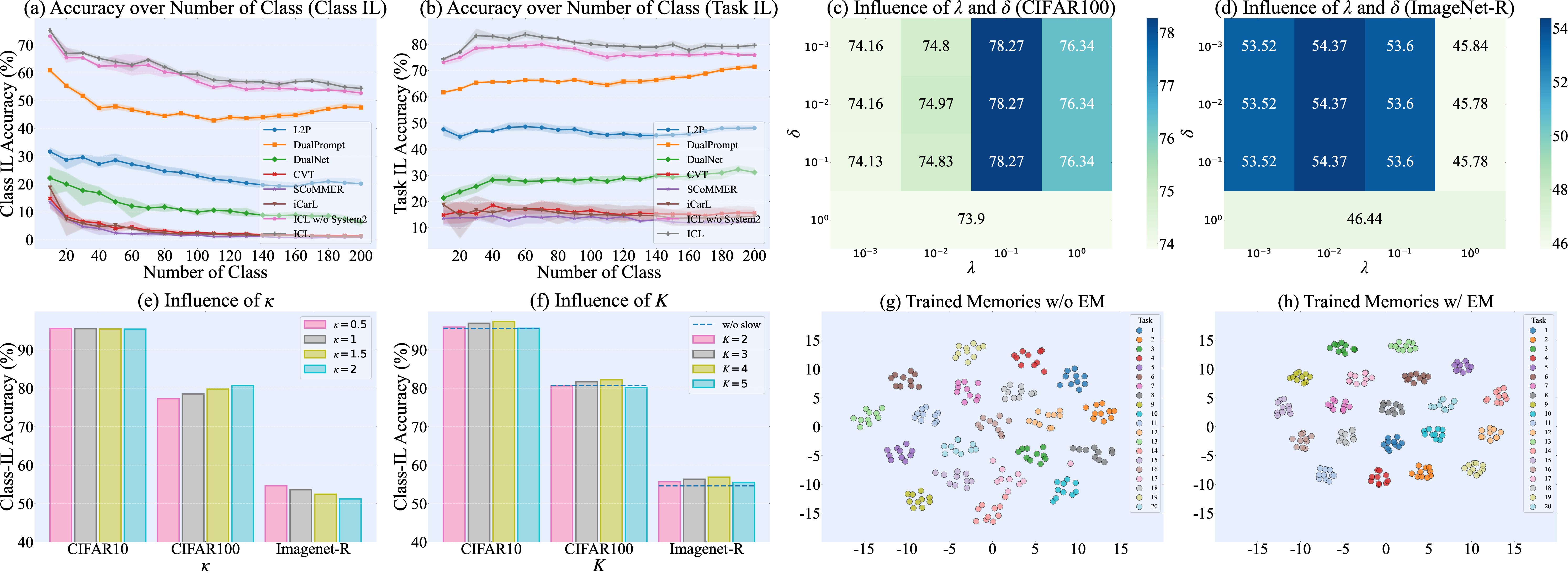
- Less forgetting, better accuracy: On standard image benchmarks (CIFAR10, CIFAR100, and ImageNet-R), their method stayed accurate across many tasks and forgot less than other popular approaches. It worked in both easier settings (where the model knows the task during testing) and harder ones (where it must guess among all learned classes).
- The “two minds” work: Even without training the reasoning model, just using it to help on hard images made the whole system more reliable—especially on tough datasets like ImageNet-R.
- Flexible, class-free memory: The memory grows by adding new class entries as needed. The model doesn’t need to know the total number of classes ahead of time, and it doesn’t have to rebuild its final classifier each time.
- Stable training: The spherical memory design and a small “gradient stabilizer” make learning smoother and reduce the chance of the model drifting away from old knowledge.
Why this matters: continual learning is hard because new lessons often overwrite old ones. This paper shows a practical way to keep learning steadily by combining fast pattern recognition with careful reasoning, triggered only when needed.
What’s the bigger impact?
If AI can keep learning without forgetting, it becomes far more useful in the real world. For example:
- A home robot could learn new objects over months without losing track of earlier ones.
- A medical assistant AI could steadily adapt to new cases while keeping previous knowledge sharp.
- Systems could handle changing environments (like traffic scenes or new product images) without constant full retraining.
The key idea—fast thinking for easy cases, slow thinking for hard ones—mirrors how people learn and remember. This interactive approach could make future AI more reliable, efficient, and adaptable over long periods.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and could guide future research:
- Convergence and stability of the EM-based CL-vMF optimization are not theoretically analyzed (e.g., conditions for convergence, effect of non-convexity, interaction with the gradient stabilization term, number of EM iterations T, and sensitivity to initialization).
- Hyperparameter selection and adaptation remain ad hoc (global κ, λ, δ, α, K): there is no procedure for task- or data-dependent tuning, no automatic calibration, and no study of class-wise or learnable κ.
- The vMF-ODI hard-sample detector depends on batch statistics (z-score on cosine similarity), making it sensitive to batch size, class imbalance, and non-iid streaming; a batch-free or adaptive detection mechanism is not provided.
- The criterion for when System2’s output is considered a “precise answer” is unspecified; there is no confidence calibration, self-consistency, or arbitration policy to decide between System1 and System2 when they disagree.
- System2 is only used at inference; there is no mechanism for System2 to teach System1 (e.g., targeted distillation, memory updates, or rationale-guided adaptation) to reduce future reliance on System2.
- The impact of fine-tuning or aligning System2 (e.g., via LoRA) on continual learning (accuracy, forgetting, and cross-task stability) is not studied; potential negative transfer across tasks is unaddressed.
- Prompting design for System2 is under-specified (templates, label disambiguation, handling of long-tail labels, synonyms, multilingual labels); the alignment between dataset label space and MLLM vocabulary is not evaluated.
- Using top-K predictions from System1 as System2 context risks error propagation; the effect of wrong candidates, choice of K, and adaptive K scheduling is not analyzed.
- Scalability of the value memory as the number of classes/tasks grows is not evaluated beyond 200 classes; retrieval latency, memory footprint, and the need for indexing/pruning/merging strategies are open.
- The growth and redundancy of task-specific (zτ) vs class-specific (zc) memories are unclear; memory accounting and consolidation policies over long task sequences are unspecified.
- Inference-time overhead of System2 activation is not measured; there is no accuracy–latency/energy trade-off analysis, fraction of routed samples, or feasibility on edge devices.
- Evaluation is limited to image classification; extensibility to detection, segmentation, OCR, VQA, video, and non-vision modalities (audio/text) is untested.
- Robustness to domain shift beyond ImageNet-R, domain-incremental learning, open-set/open-world settings (unknown classes) and novelty detection are not explored.
- The method still relies on a rehearsal buffer; zero-buffer performance and sensitivity to buffer size and selection policy (reservoir, herding, diversity-aware) are not reported.
- The memory sampling/curation strategy for the buffer is unspecified; the interaction between CL-vMF geometry and buffer selection is not studied.
- Baseline coverage and fairness: several strong rehearsal and transformer-based CL baselines (e.g., ER-ACE, DER/DER++, DyTox, Co2L, PASS, REMIND) are missing; modifying L2P/DualPrompt with buffers deviates from standard usage and may confound comparisons.
- Metrics focus mainly on average accuracy and some forgetting curves; standard CL metrics such as backward transfer (BWT), forward transfer (FWT), and calibration/uncertainty are not comprehensively reported.
- Generality across System1 backbones is not established; results focus on ViT, with limited evidence for CNNs or self-supervised backbones (DINO/MAE).
- Assumptions of clean, fully supervised labels are strong; behavior under label noise, weak/semi-supervised CL, or partial labels is not examined.
- κ is global and fixed; class-wise or data-dependent κ, or learning κ, might improve margins and OOD detection but is not investigated.
- The single-prototype per class assumption may be limiting when classes are multi-modal; mixture-of-vMF prototypes and multi-center class modeling are not considered.
- Dynamics of prototype drift across tasks are not analyzed (e.g., how freezing old z affects feature drift in the query network and vice versa).
- Adversarial and security robustness are unaddressed; susceptibility of vMF-ODI and memory retrieval to adversarial perturbations or distributional attacks is unknown.
- Reproducibility issues with MLLMs (stochastic outputs, temperature, decoding) are not controlled; protocols for deterministic evaluation are not specified.
- Conflict handling between System1 and System2 is simplistic; richer arbitration (meta-controller, learned gating, uncertainty-aware routing) is not explored.
- Privacy and licensing constraints of using MLLMs in continual settings are not discussed; implications for real-world deployment remain open.
- CKT-MHA design lacks ablations against alternative attention/pooling architectures and prompt-based adapters; compute/memory overhead and scalability of CKT-MHA are not quantified.
- There is no interpretability analysis of class/task features learned by CKT-MHA or the memory vectors; it’s unclear how errors relate to memory drift vs query network drift.
- Sleep-like consolidation or offline summarization (e.g., System2 generating synthetic rehearsal or rationales to consolidate System1 memory) is not explored.
- Effects of class imbalance/long-tailed distributions on CL-vMF optimization and vMF-ODI thresholds are not evaluated.
- Handling of class reappearance or semantic shift across tasks is unspecified (when a previously seen class reappears with distributional drift, how and when are its value memories updated?).
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the paper’s Interactive Continual Learning (ICL) components—System1 (ViT), System2 (multimodal LLM), CKT-MHA, CL-vMF, and vMF-ODI—into existing workflows.
- Continual image classification in MLOps (Retail, Manufacturing, Software)
- Use case: Incrementally add new product categories or defect types without retraining the entire classification head. Employ decoupled value memory embeddings and EM-guided updates (CL-vMF), while using vMF-ODI to route ambiguous inputs to a reasoning stage.
- Tools/workflows: “Prototype Memory Store” for per-class embeddings, “EM-based Updater” for query/value decoupled optimization, “Inference Router” using vMF-ODI thresholds.
- Assumptions/dependencies: Pretrained ViT available; reliable label mapping to class-specific memory; access to an MLLM (e.g., MiniGPT4) with acceptable latency/cost; appropriate choice of hyperparameters (kappa, lambda, delta, alpha).
- Vision-based quality inspection with ambiguity routing (Manufacturing)
- Use case: On-prem System1 handles routine defects; vMF-ODI flags borderline cases; System2 (MLLM) generates structured reasoning from System1’s top-K candidates to support an operator’s decision or automated secondary checks.
- Tools/workflows: Edge ViT with CL-vMF for fast inference; prompt templates that convert top-K predictions into queries for System2; dashboard showing routed cases and rationales.
- Assumptions/dependencies: Domain-specific prompts for effective LLM reasoning; human-in-the-loop for final adjudication; stable compute budgets on the factory floor.
- E-commerce catalog enrichment and content moderation (Retail, Media/Platforms)
- Use case: Continually classify product images and add nuanced attributes; route uncertain images to an LLM for descriptive reasoning (e.g., style, material), or to human moderators for safety-sensitive cases.
- Tools/workflows: CKT-MHA to fuse class and knowledge features; top-K guided prompts to System2 for attribute extraction or policy compliance checks.
- Assumptions/dependencies: Robust multimodal LLM with domain knowledge; governance for LLM use in moderation; data privacy and audit controls.
- Active learning and dataset curation (Academia, ML Ops)
- Use case: Use vMF-ODI scores to automatically surface “hard” samples for labeling or review; improve memory geometry via CL-vMF to stabilize class prototypes over time.
- Tools/workflows: Hard-example queues, annotation tools integrated with prototype drift dashboards; rehearsal buffers that persist across tasks.
- Assumptions/dependencies: Reliable thresholds for outlier detection; sufficient labeler availability; predictable rehearsal buffer policies.
- Document and ID image classification with escalation (Finance, Gov/Identity)
- Use case: Continually adapt to new document layouts or ID card types; route anomalies (outliers flagged by vMF-ODI) to System2 for reasoning or to compliance reviewers.
- Tools/workflows: On-device System1 for routine classification; audit trail showing which inputs were escalated and why; LoRA-tuned System2 for domain-specific reasoning.
- Assumptions/dependencies: Secure handling of PII; rigorous logging; domain-specific prompt engineering; adherence to compliance requirements.
- Wildlife monitoring and biodiversity surveys (Environmental Science)
- Use case: Add new species as they appear (class-free expansion via CL-vMF); flag ambiguous detections to an LLM for cross-referencing features or to biologists for validation.
- Tools/workflows: Lightweight edge deployments with ViT; centralized aggregation of hard cases; species prototype libraries that scale linearly with the number of classes.
- Assumptions/dependencies: Reliable feature extractors in diverse conditions; access to domain knowledge; appropriate latency tolerance when calling System2.
- Benchmarking and teaching CL frameworks (Academia)
- Use case: Adopt ICL as a teaching and research baseline to demonstrate fast vs. slow thinking synergy; replicate memory dynamics via CKT-MHA, CL-vMF, and vMF-ODI.
- Tools/workflows: Course labs with open-source repo; standardized experiments on CIFAR/Imagenet-R splits; ablation studies on kappa, lambda, delta, K (top-K).
- Assumptions/dependencies: Availability of compute; consistent experimental protocols; reproducibility of EM-based updates.
Long-Term Applications
The following applications are feasible with further research, scaling, domain hardening, and/or regulatory alignment.
- Safety-critical autonomous perception with interactive CL (Automotive, Robotics)
- Use case: Real-time object recognition that learns continuously without catastrophic forgetting; System1 handles common objects; System2 engages in complex reasoning for edge cases (construction zones, novel obstacles).
- Tools/products: “CL Perception Gateway” combining on-vehicle prototypes with cloud-based LLM reasoning; certified escalation policies for low-confidence detections.
- Assumptions/dependencies: Stringent latency/throughput guarantees; reliability of MLLM reasoning under distribution shift; safety certification and auditability of per-task memory updates.
- Clinical imaging triage and continual adaptation (Healthcare)
- Use case: Continually learn new imaging patterns while preserving past performance; flag borderline exams with vMF-ODI; System2 provides structured explanations for radiologist review.
- Tools/products: “Adaptive Imaging Memory Manager” with class-free expansion; clinician-facing “Reasoning Summaries” derived from LLM prompts seeded by top-K predictions.
- Assumptions/dependencies: Regulatory approval (FDA/CE), robust privacy and security; bias monitoring; rigorous post-market surveillance; domain-tuned LLMs.
- Generalized multimodal continual learning (Audio, Text, Time Series)
- Use case: Extend CL-vMF and CKT-MHA beyond vision to speech commands, sensor anomalies, or document semantics; use vMF-ODI for modality-agnostic outlier triage.
- Tools/products: Cross-modal prototype layers and decoupled memory managers integrated with foundation models; unified escalation and prompt routing services.
- Assumptions/dependencies: Proven efficacy of vMF-based geometry in non-visual spaces; modality-specific feature extractors; integrated multi-sensor pipelines.
- On-device, open-world recognition with class-free memory (Edge AI, IoT)
- Use case: Embedded devices that learn new categories over time without head retraining; offload hard cases to a local/edge reasoning model or cloud service.
- Tools/products: “Prototype-on-Chip” memory stores; compressed System2 variants (small multimodal LLMs); adaptive rehearsal buffers.
- Assumptions/dependencies: Efficient memory footprint and energy constraints; robust privacy-preserving escalation; intermittent connectivity handling.
- Robotics task learning with fast–slow synergy (Robotics)
- Use case: Robots learn new objects and affordances via System1, escalating complex scenes to System2 for stepwise reasoning and task planning.
- Tools/products: “Interactive Skill Learner” that integrates vision prototypes with LLM-based planning; memory-aware policy updates.
- Assumptions/dependencies: Stable integration of perception and planning; safe recovery behaviors; domain-adapted LLMs for manipulation tasks.
- Fraud and anomaly detection with escalated reasoning (Finance, Cybersecurity)
- Use case: Continuously update fraud signatures while preserving known patterns; use vMF-ODI to flag outliers for System2 analysis or analyst review.
- Tools/products: “Risk Router” that integrates prototype similarity scores with rich explainability via structured LLM prompts; evidence-backed case files.
- Assumptions/dependencies: High-stakes thresholds tuned to minimize false positives/negatives; strict data governance; model monitoring under drift.
- Standards and audits for interactive continual learning (Policy, Governance)
- Use case: Develop certification and audit frameworks for systems that update memory over time and escalate low-confidence cases; track prototype changes and reasoning traces.
- Tools/products: “CL Audit Ledger” recording memory updates, rehearsal usage, vMF-ODI triggers, and System2 rationales; compliance dashboards.
- Assumptions/dependencies: Consensus on CL safety requirements; transparency tooling in MLLMs; privacy-by-design in logging.
- Adaptive education systems with escalation for complex queries (Education)
- Use case: Fast classifiers route routine questions; complex, ambiguous, or novel student inputs trigger LLM reasoning with context from top-K predictions; continual tuning of content prototypes.
- Tools/products: “Interactive Tutor Router” combining CL memory with reasoning escalations; analytics for prototype shifts in curriculum topics.
- Assumptions/dependencies: Reliable multimodal inputs (text, images, diagrams); pedagogically sound LLMs; safeguards against hallucination.
Overall, the paper’s decoupled memory design (CKT-MHA + CL-vMF), EM-based training, and vMF-ODI routing form a practical blueprint for building systems that balance fast pattern recognition with slow deliberative reasoning. Feasibility hinges on access to robust multimodal LLMs, careful thresholding and hyperparameter tuning, latency and cost management, and domain-specific governance for escalated decisions.
Glossary
- Bayesian discrimination: Using Bayes’ rule to classify by comparing class-conditional densities and priors. "By utilizing the constructed probability density for Bayesian discrimination, we can ascertain the form of the posterior probability"
- Catastrophic forgetting: The tendency of a model to lose previously learned knowledge when trained on new tasks. "face a risk known as catastrophic forgetting"
- Chains of thought: A reasoning approach where models generate step-by-step intermediate reasoning before final answers. "These models can employ chains of thought \cite{wei2022chain} to engage in complex reasoning"
- Class-free memory retrieval: A retrieval mechanism that does not assume a fixed number of classes and can add new class memories on the fly. "we introduce CL-vMF, a class-free memory retrieval mechanism"
- Class-Incremental Learning (Class IL): Continual learning setting where the model must predict over all seen classes without task identifiers at test time. "Task-Incremental Learning (Task IL) and Class-Incremental Learning (Class IL)."
- Class-Knowledge-Task Multi-Head Attention (CKT-MHA): An attention module that fuses class features, pretrained knowledge, and task signals across multiple heads to aid retrieval. "we propose the Class-Knowledge-Task Multi-Head Attention (CKT-MHA)."
- Complementary Learning System (CLS) Theory: A neurocognitive framework positing distinct fast (hippocampal-like) and slow (cortical-like) systems that jointly support learning and memory. "From the perspective of Complementary Learning System (CLS) Theory in neurocognitive science"
- Expectation-Maximization (EM): An iterative procedure alternating between latent-variable assignment (E-step) and parameter optimization (M-step). "enhance retrieval distinguishability through an Expectation-Maximization (EM) update strategy"
- Evidence Lower Bound (ELBO): A variational lower bound on log-likelihood used to guide optimization with latent variables. "the first term of R.H.S is referred to as the Evidence Lower Bound"
- Generalized Expectation-Maximization (GEM): A variant of EM that ensures likelihood improvement via alternating updates without requiring a full exact E-step. "using the Generalized Expectation-Maximization algorithm (GEM)"
- Gradient stabilization loss: An auxiliary margin-based objective designed to prevent vanishing gradients during training. "we introduce a gradient stabilization loss"
- Label-to-prompt operation: A mapping from class labels to textual prompts for conditioning an LLM. "here represents label to prompt operation"
- LLMs: High-capacity neural models trained on vast corpora that exhibit strong generative and reasoning abilities. "the emergence of LLMs presents promising avenues"
- LoRA: A low-rank adaptation technique for parameter-efficient fine-tuning of large models. "fine-tuning strategies, such as LoRA \cite{hu2021lora}"
- Multi-Head Attention (MHA): An attention mechanism that computes multiple attention heads in parallel to capture diverse relationships. "where is the head number of MHA"
- Multimodal LLM: A LLM capable of processing multiple modalities (e.g., images and text). "System2 is instantiated with a Multimodal LLM represented as"
- Query memory: Trainable parameters that produce features used to query and match against stored value memories. "and query memory parameters represented by "
- Reservoir sampling: An algorithm to maintain a uniform random sample of fixed size from a data stream. "Reservoir sampling techniques \cite{chaudhry2019tiny,riemer2018learning}"
- Rehearsal-based methods: Continual learning strategies that replay stored past examples to mitigate forgetting. "In CL, rehearsal-based methods \cite{rebuffi2017icarl,saha2021gradient,tang2021layerwise,ECCV22_CL,wang2022learning,wang2022dualprompt}, are the most direct strategy."
- Set2Set retrieval: A memory retrieval approach that maps sets of features to sets using attention to stabilize retrieval. "we propose a Set2Set memory retrieval mechanism"
- Stability–plasticity balance: The trade-off between retaining old knowledge (stability) and incorporating new information (plasticity). "maintain a balance between stability and plasticity"
- Task-Incremental Learning (Task IL): Continual learning setting where task identifiers are known during testing. "Task-Incremental Learning (Task IL) and Class-Incremental Learning (Class IL)."
- Value memory: Class-specific embeddings stored as targets for retrieval and preserved across tasks. "value memory parameters, denoted as "
- Vision Transformer (ViT): A transformer-based architecture for image representation that operates on patch tokens. "integrate intuitive models, such as ViT \cite{dosovitskiy2020image} as System1"
- von Mises-Fisher (vMF) distribution: A distribution on the unit hypersphere characterized by a mean direction and concentration. "based on the von Mises-Fisher (vMF) distribution"
- vMF posterior: Posterior class probabilities computed using vMF densities and normalized dot products. "it retrieves from memories based on the vMF posterior"
- vMF-ODI (von Mises-Fisher Outlier Detection and Interaction): A strategy to detect hard examples via vMF geometry and route them for collaborative inference. "we introduce the von Mises-Fisher Outlier Detection and Interaction (vMF-ODI) strategy"
Collections
Sign up for free to add this paper to one or more collections.

