- The paper introduces Multi-modal Attribute Prompting (MAP) that enhances fine-grained visual and textual alignment in few-shot scenarios.
- It leverages both textual and visual attribute prompting along with an optimal transport-based alignment mechanism for precise cross-modal matching.
- Experiments demonstrate superior performance in base-to-novel generalization and domain adaptation across multiple datasets compared to prior methods.
Multi-modal Attribute Prompting for Vision-LLMs
Introduction
The paper, "Multi-modal Attribute Prompting for Vision-LLMs" (2403.00219), addresses the adaptation challenges faced by large pre-trained Vision-LLMs (VLMs) such as CLIP in few-shot scenarios. These models, although proficient in generalization tasks, falter when exposed to limited data conditions due to their reliance on global representations and lack of detailed multi-modal attribute characterization. The authors propose a novel approach called Multi-modal Attribute Prompting (MAP), which integrates textual attribute prompting, visual attribute prompting, and a unique attribute-level alignment mechanism to enhance the model's fine-grained perceptual abilities and robustness in unseen class contexts.
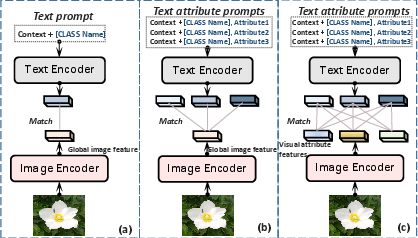
Figure 1: Conventional prompting methods versus multi-modal attribute exploration for fine-grained alignment.
Methodology
Textual Attribute Prompting
The methodology introduces a step called Textual Attribute Prompting, which utilizes LLMs to generate enriched semantic content by querying specific discriminative features of image classes. This process involves constructing text prompts that envelop class names with detailed attribute descriptions, thereby creating a richer semantic context than traditional class-only prompts.
Visual Attribute Prompting
In conjunction with textual attributes, the paper introduces Visual Attribute Prompting through learnable vectors that are strategically inserted into the Vision Transformer layers. These visual prompts interact with image tokens, thereby enabling the extraction and aggregation of fine-grained visual features. The Adaptive Visual Attribute Enhancement (AVAE) module further refines visual prompts by aligning them with selected textual attributes using a cross-attention mechanism, allowing for dynamic recognition capabilities in unforeseen categories.
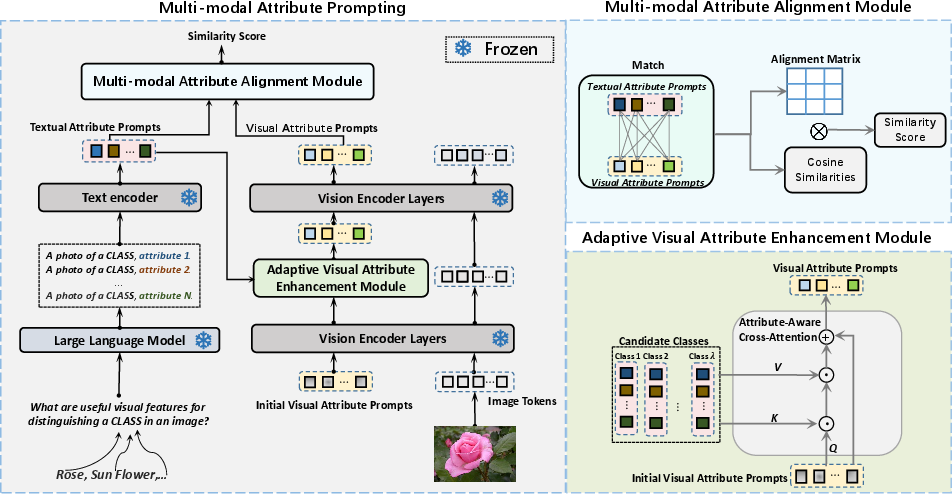
Figure 2: MAP architecture illustrating the integration of textual and visual prompts along with attribute-level alignment.
Attribute-Level Alignment
To overcome the inherent limitations of global alignment, the authors reformulate the alignment task into an Optimal Transport problem, thereby enabling precise attribute-level matching. By computing similarity scores between the visual and textual attribute distributions, the MAP approach achieves a robust cross-modal alignment, significantly reducing disruptions from complex scenarios and irrelevant details.
Experimental Analysis
The proposed MAP method demonstrates its efficacy through extensive evaluation across multiple settings, including base-to-novel class generalization, few-shot image classification, domain generalization, and cross-dataset evaluation.
Base-to-Novel Generalization
As evidenced by the results, MAP exhibits superior performance in transitioning from base classes to novel unknown classes, achieving higher harmonic mean accuracy than previous methods like CoOp and CoCoOp across 11 diverse datasets. This underscores MAP's enhanced capability in encapsulating categorical semantics and improving model adaptability.
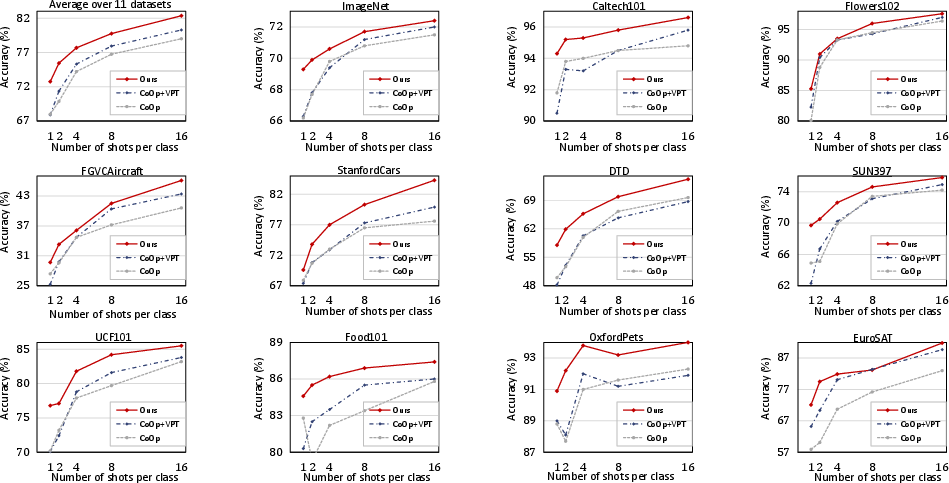
Figure 3: Performance comparison in base-to-novel generalization across 11 datasets.
Few-Shot Image Classification
MAP consistently outperforms other CLIP adaptation methods in few-shot scenarios, particularly notable in 1-shot conditions, where its introduction of text-guided visual prompts shows remarkable performance gains.
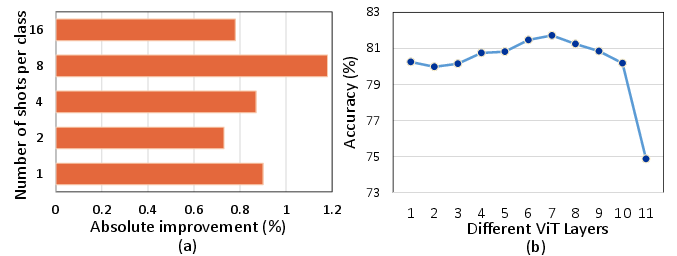
Figure 4: Few-shot accuracy improvements attributed to AVAE module incorporation across multiple layers.
Domain and Cross-Dataset Generalization
Further experiments reveal MAP's robustness in domain-shifted environments and varied datasets, maintaining high accuracy levels compared to other state-of-the-art approaches. This cross-domain applicability highlights the precision of the attribute alignment strategies employed in MAP.
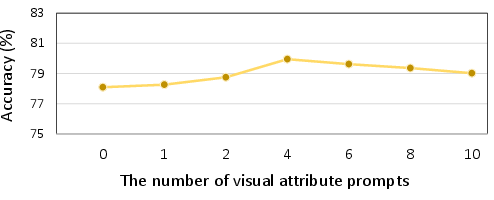
Figure 5: Average performance over six few-shot classification datasets and visual prompt impact in domain generalization.
Conclusion
The Multi-modal Attribute Prompting method significantly advances the adaptation capabilities of Vision-LLMs in few-shot learning by introducing innovative techniques for modeling and aligning fine-grained visual and textual attributes. This dual approach not only enhances perceptual detail recognition but also improves robustness against disruptions, suggesting promising directions for future enhancements in AI model adaptability and real-world application scalability.