ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL
Abstract: A broad use case of LLMs is in goal-directed decision-making tasks (or "agent" tasks), where an LLM needs to not just generate completions for a given prompt, but rather make intelligent decisions over a multi-turn interaction to accomplish a task (e.g., when interacting with the web, using tools, or providing customer support). Reinforcement learning (RL) provides a general paradigm to address such agent tasks, but current RL methods for LLMs largely focus on optimizing single-turn rewards. By construction, most single-turn RL methods cannot endow LLMs with the ability to intelligently seek information over multiple turns, perform credit assignment, or reason about their past actions -- all of which are critical in agent tasks. This raises the question: how can we design effective and efficient multi-turn RL algorithms for LLMs? In this paper, we develop a framework for building multi-turn RL algorithms for fine-tuning LLMs, that preserves the flexibility of existing single-turn RL methods for LLMs (e.g., proximal policy optimization), while accommodating multiple turns, long horizons, and delayed rewards effectively. To do this, our framework adopts a hierarchical RL approach and runs two RL algorithms in parallel: a high-level off-policy value-based RL algorithm to aggregate reward over utterances, and a low-level RL algorithm that utilizes this high-level value function to train a token policy within each utterance or turn. Our hierarchical framework, Actor-Critic Framework with a Hierarchical Structure (ArCHer), can also give rise to other RL methods. Empirically, we find that ArCHer significantly improves efficiency and performance on agent tasks, attaining a sample efficiency of about 100x over existing methods, while also improving with larger model capacity (upto the 7 billion scale that we tested on).
- Lmrl gym: Benchmarks for multi-turn reinforcement learning with language models, 2023.
- Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022.
- Multiwoz - A large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. CoRR, abs/1810.00278, 2018. URL http://arxiv.org/abs/1810.00278.
- Open problems and fundamental limitations of reinforcement learning from human feedback, 2023.
- Fireact: Toward language agent fine-tuning. ArXiv, abs/2310.05915, 2023. URL https://api.semanticscholar.org/CorpusID:263829338.
- Deep reinforcement learning from human preferences, 2023.
- Scaling instruction-finetuned language models, 2022.
- Offline reinforcement learning: Fundamental barriers for value function approximation. CoRR, abs/2111.10919, 2021. URL https://arxiv.org/abs/2111.10919.
- A minimalist approach to offline reinforcement learning. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
- Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023.
- Cicero: A dataset for contextualized commonsense inference in dialogues. In Annual Meeting of the Association for Computational Linguistics, 2022. URL https://api.semanticscholar.org/CorpusID:247762111.
- Improving alignment of dialogue agents via targeted human judgements, 2022.
- Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998, 2023.
- Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. CoRR, abs/1801.01290, 2018. URL http://arxiv.org/abs/1801.01290.
- Interactive fiction games: A colossal adventure. CoRR, abs/1909.05398, 2019. URL http://arxiv.org/abs/1909.05398.
- Zero-shot goal-directed dialogue via rl on imagined conversations, 2023.
- GPT-critic: Offline reinforcement learning for end-to-end task-oriented dialogue systems. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=qaxhBG1UUaS.
- Human-centric dialog training via offline reinforcement learning. CoRR, abs/2010.05848, 2020. URL https://arxiv.org/abs/2010.05848.
- Mistral 7b, 2023.
- Pretraining language models with human preferences, 2023.
- Offline reinforcement learning with implicit q-learning, 2021.
- Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in Neural Information Processing Systems, 32, 2019.
- Conservative q-learning for offline reinforcement learning. CoRR, abs/2006.04779, 2020. URL https://arxiv.org/abs/2006.04779.
- Convlab: Multi-domain end-to-end dialog system platform. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- Competition-level code generation with alphacode. Science, 378:1092 – 1097, 2022. URL https://api.semanticscholar.org/CorpusID:246527904.
- Nl2bash: A corpus and semantic parser for natural language interface to the linux operating system. CoRR, abs/1802.08979, 2018. URL http://arxiv.org/abs/1802.08979.
- Agentbench: Evaluating llms as agents, 2023.
- Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019. URL http://arxiv.org/abs/1907.11692.
- Playing atari with deep reinforcement learning. CoRR, abs/1312.5602, 2013. URL http://arxiv.org/abs/1312.5602.
- The primacy bias in deep reinforcement learning. In International conference on machine learning, pages 16828–16847. PMLR, 2022.
- Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. ArXiv, abs/2203.02155, 2022. URL https://api.semanticscholar.org/CorpusID:246426909.
- A deep reinforced model for abstractive summarization, 2017.
- Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. CoRR, abs/1910.00177, 2019. URL http://arxiv.org/abs/1910.00177.
- Language models are unsupervised multitask learners. 2019. URL https://api.semanticscholar.org/CorpusID:160025533.
- Direct preference optimization: Your language model is secretly a reward model, 2023.
- Is reinforcement learning (not) for natural language processing?: Benchmarks, baselines, and building blocks for natural language policy optimization. 2022. URL https://arxiv.org/abs/2210.01241.
- Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization, 2023.
- Sequence level training with recurrent neural networks, 2015.
- Toolformer: Language models can teach themselves to use tools, 2023.
- High-dimensional continuous control using generalized advantage estimation. CoRR, abs/1506.02438, 2015. URL https://api.semanticscholar.org/CorpusID:3075448.
- Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017. URL http://arxiv.org/abs/1707.06347.
- Reflexion: Language agents with verbal reinforcement learning. 2023. URL https://api.semanticscholar.org/CorpusID:258833055.
- Offline rl for natural language generation with implicit language q learning, 2023.
- Hybrid rl: Using both offline and online data can make rl efficient, 2023.
- Policy gradient methods for reinforcement learning with function approximation. In S. Solla, T. Leen, and K. Müller, editors, Advances in Neural Information Processing Systems, volume 12. MIT Press, 1999. URL https://proceedings.neurips.cc/paper_files/paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf.
- Large language models as generalizable policies for embodied tasks, 2023.
- Llama 2: Open foundation and fine-tuned chat models, 2023.
- Deep reinforcement learning with double q-learning. CoRR, abs/1509.06461, 2015. URL http://arxiv.org/abs/1509.06461.
- Chai: A chatbot ai for task-oriented dialogue with offline reinforcement learning, 2022.
- Voyager: An open-ended embodied agent with large language models. ArXiv, abs/2305.16291, 2023. URL https://api.semanticscholar.org/CorpusID:258887849.
- Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8:229–256, 2004. URL https://api.semanticscholar.org/CorpusID:19115634.
- Learning to extract coherent summary via deep reinforcement learning, 2018.
- Bellman-consistent pessimism for offline reinforcement learning. CoRR, abs/2106.06926, 2021. URL https://arxiv.org/abs/2106.06926.
- Intercode: Standardizing and benchmarking interactive coding with execution feedback, 2023a.
- LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. arXiv preprint arXiv:2306.15626, 2023b.
- Webshop: Towards scalable real-world web interaction with grounded language agents, 2023a.
- React: Synergizing reasoning and acting in language models, 2023b.
- Rrhf: Rank responses to align language models with human feedback without tears, 2023.
- Andrea Zanette. When is realizability sufficient for off-policy reinforcement learning?, 2023.
- Agenttuning: Enabling generalized agent abilities for llms, 2023.
- Offline reinforcement learning with realizability and single-policy concentrability, 2022.
- Webarena: A realistic web environment for building autonomous agents. ArXiv, abs/2307.13854, 2023a. URL https://api.semanticscholar.org/CorpusID:260164780.
- Offline data enhanced on-policy policy gradient with provable guarantees, 2023b.
- Convlab-2: An open-source toolkit for building, evaluating, and diagnosing dialogue systems. CoRR, abs/2002.04793, 2020. URL https://arxiv.org/abs/2002.04793.
- Fine-tuning language models from human preferences. CoRR, abs/1909.08593, 2019. URL http://arxiv.org/abs/1909.08593.

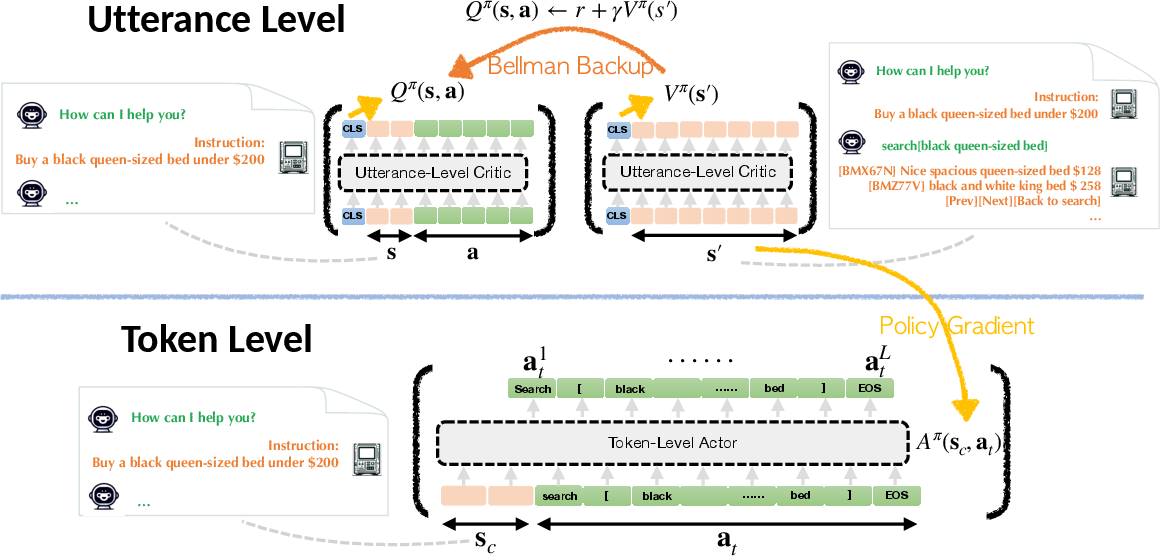
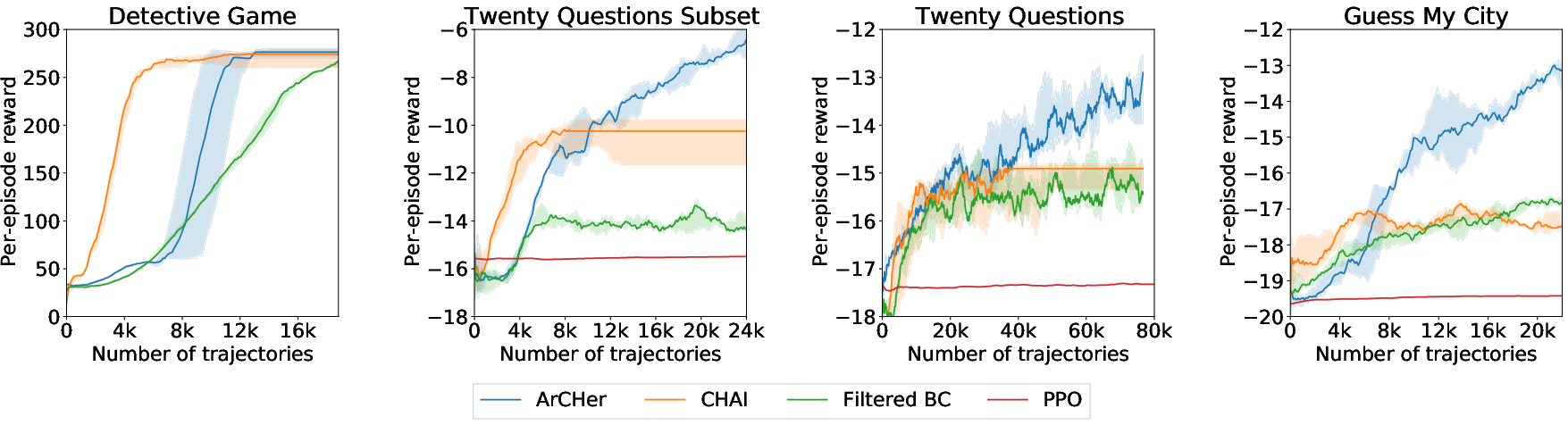
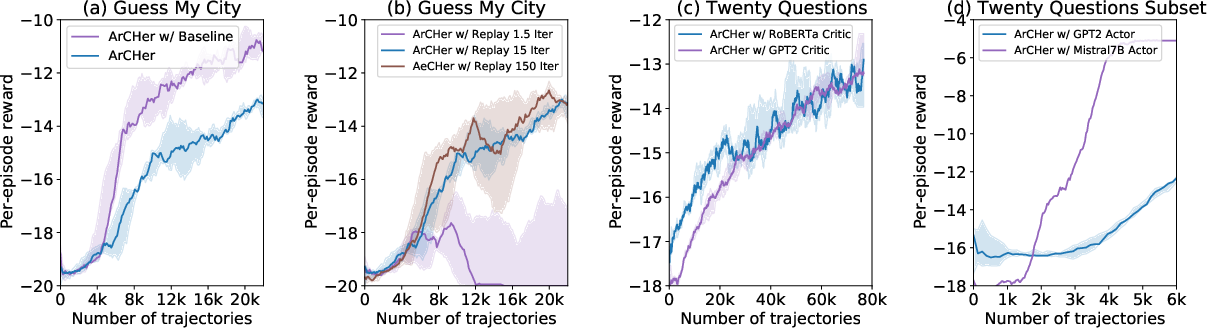
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.