Tokenization Is More Than Compression
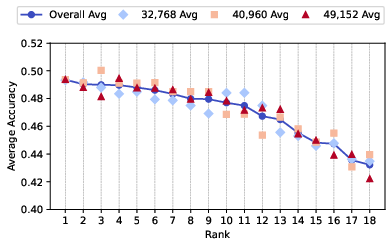
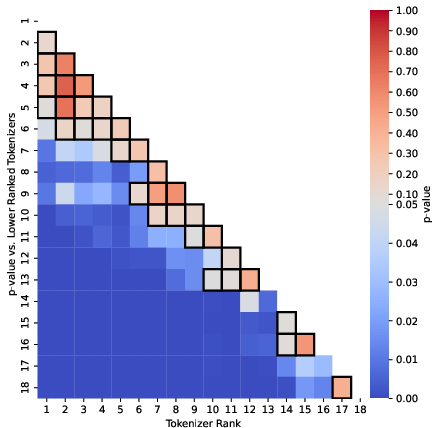
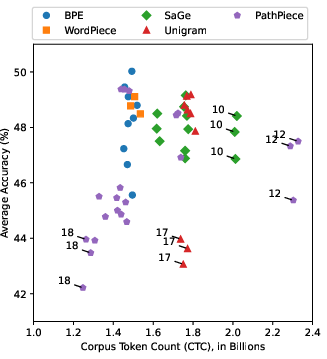
Abstract: Tokenization is a foundational step in NLP tasks, bridging raw text and LLMs. Existing tokenization approaches like Byte-Pair Encoding (BPE) originate from the field of data compression, and it has been suggested that the effectiveness of BPE stems from its ability to condense text into a relatively small number of tokens. We test the hypothesis that fewer tokens lead to better downstream performance by introducing PathPiece, a new tokenizer that segments a document's text into the minimum number of tokens for a given vocabulary. Through extensive experimentation we find this hypothesis not to be the case, casting doubt on the understanding of the reasons for effective tokenization. To examine which other factors play a role, we evaluate design decisions across all three phases of tokenization: pre-tokenization, vocabulary construction, and segmentation, offering new insights into the design of effective tokenizers. Specifically, we illustrate the importance of pre-tokenization and the benefits of using BPE to initialize vocabulary construction. We train 64 LLMs with varying tokenization, ranging in size from 350M to 2.4B parameters, all of which are made publicly available.
- Mathqa: Towards interpretable math word problem solving with operation-based formalisms.
- Datasheet for the pile. CoRR, abs/2201.07311.
- Piqa: Reasoning about physical commonsense in natural language.
- Kaj Bostrom and Greg Durrett. 2020. Byte pair encoding is suboptimal for language model pretraining. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4617–4624, Online. Association for Computational Linguistics.
- Gerlof Bouma. 2009. Normalized (pointwise) mutual information in collocation extraction. Proceedings of GSCL, 30:31–40.
- Copa-sse: Semi-structured explanations for commonsense reasoning.
- Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457.
- Pavlos S. Efraimidis. 2010. Weighted random sampling over data streams. CoRR, abs/1012.0256.
- Philip Gage. 1994. A new algorithm for data compression. C Users J., 12(2):23–38.
- Matthias Gallé. 2019. Investigating the effectiveness of BPE: The power of shorter sequences. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1375–1381, Hong Kong, China. Association for Computational Linguistics.
- The pile: An 800gb dataset of diverse text for language modeling.
- A framework for few-shot language model evaluation.
- Improving tokenisation by alternative treatment of spaces. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11430–11443, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Gregory Grefenstette. 1999. Tokenization, pages 117–133. Springer Netherlands, Dordrecht.
- From characters to words: the turning point of BPE merges. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 3454–3468, Online. Association for Computational Linguistics.
- Dynamic programming encoding for subword segmentation in neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3042–3051, Online. Association for Computational Linguistics.
- Measuring massive multitask language understanding.
- Superbizarre is not superb: Derivational morphology improves BERT’s interpretation of complex words. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3594–3608, Online. Association for Computational Linguistics.
- An embarrassingly simple method to mitigate undesirable properties of pretrained language model tokenizers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 385–393, Dublin, Ireland. Association for Computational Linguistics.
- Cassandra L Jacobs and Yuval Pinter. 2022. Lost in space marking. arXiv preprint arXiv:2208.01561.
- Jean Kaddour. 2023. The minipile challenge for data-efficient language models.
- Stav Klein and Reut Tsarfaty. 2020. Getting the ##life out of living: How adequate are word-pieces for modelling complex morphology? In Proceedings of the 17th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, pages 204–209, Online. Association for Computational Linguistics.
- Taku Kudo. 2018. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 66–75, Melbourne, Australia. Association for Computational Linguistics.
- Race: Large-scale reading comprehension dataset from examinations.
- The winograd schema challenge. In 13th International Conference on the Principles of Knowledge Representation and Reasoning, KR 2012, Proceedings of the International Conference on Knowledge Representation and Reasoning, pages 552–561. Institute of Electrical and Electronics Engineers Inc. 13th International Conference on the Principles of Knowledge Representation and Reasoning, KR 2012 ; Conference date: 10-06-2012 Through 14-06-2012.
- XLM-V: Overcoming the vocabulary bottleneck in multilingual masked language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13142–13152, Singapore. Association for Computational Linguistics.
- Tokenization impacts multilingual language modeling: Assessing vocabulary allocation and overlap across languages. In Findings of the Association for Computational Linguistics: ACL 2023, pages 5661–5681, Toronto, Canada. Association for Computational Linguistics.
- Between words and characters: A brief history of open-vocabulary modeling and tokenization in nlp.
- Subword language modeling with neural networks. Preprint available at: https://api.semanticscholar.org/CorpusID:46542477.
- Qa4mre 2011-2013: Overview of question answering for machine reading evaluation. In CLEF 2013, LNCS 8138, pages 303–320.
- BPE-dropout: Simple and effective subword regularization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1882–1892, Online. Association for Computational Linguistics.
- Jonne Saleva and Constantine Lignos. 2023. What changes when you randomly choose BPE merge operations? not much. In The Fourth Workshop on Insights from Negative Results in NLP, pages 59–66, Dubrovnik, Croatia. Association for Computational Linguistics.
- Mike Schuster and Kaisuke Nakajima. 2012. Japanese and korean voice search. In 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5149–5152.
- Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics.
- BERT is not an interlingua and the bias of tokenization. In Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019), pages 47–55, Hong Kong, China. Association for Computational Linguistics.
- Llama: Open and efficient foundation language models.
- A. Viterbi. 1967. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Transactions on Information Theory, 13(2):260–269.
- Jeffrey S. Vitter. 1985. Random sampling with a reservoir. ACM Transactions on Mathematical Software, 11(1):37–57.
- Crowdsourcing multiple choice science questions. ArXiv, abs/1707.06209.
- F Wilcoxon. 1945. Individual comparisons by ranking methods. biom. bull., 1, 80–83.
- Google’s neural machine translation system: Bridging the gap between human and machine translation.
- Shaked Yehezkel and Yuval Pinter. 2023. Incorporating context into subword vocabularies. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 623–635, Dubrovnik, Croatia. Association for Computational Linguistics.
- Tokenization and the noiseless channel. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5184–5207, Toronto, Canada. Association for Computational Linguistics.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

