JMLR: Joint Medical LLM and Retrieval Training for Enhancing Reasoning and Professional Question Answering Capability
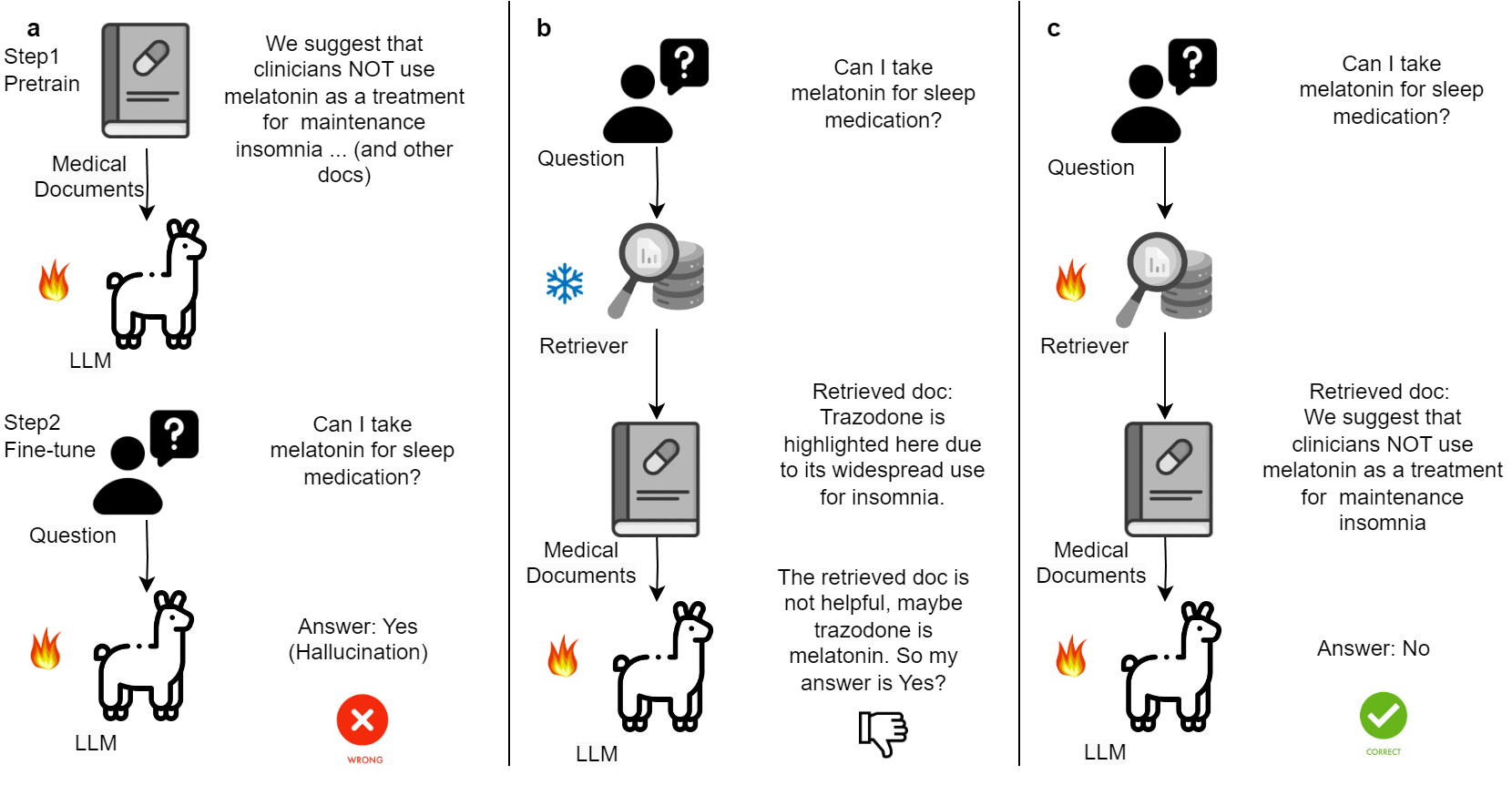
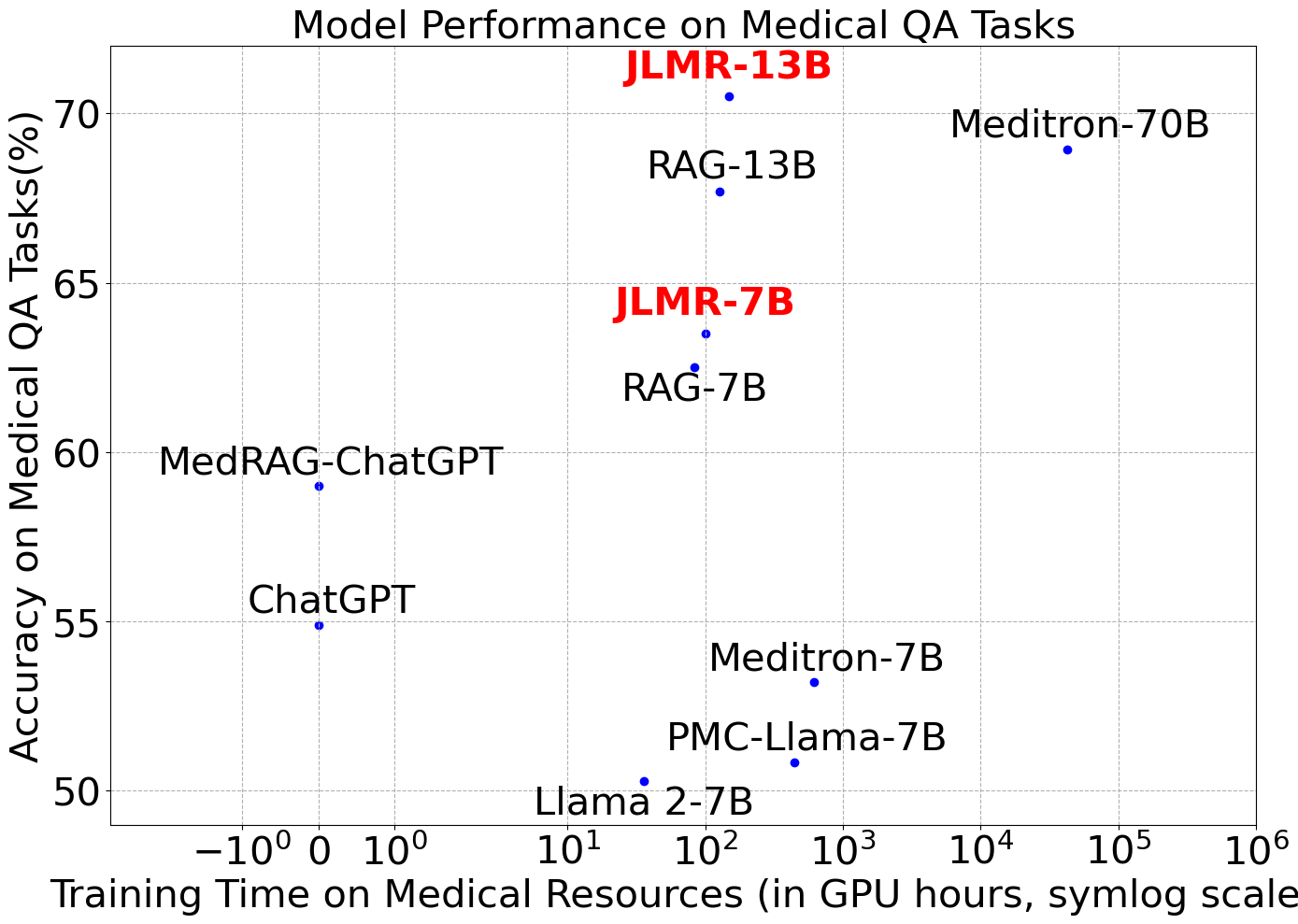
Abstract: LLMs have demonstrated a remarkable potential in medical knowledge acquisition and question-answering. However, LLMs can potentially hallucinate and yield factually incorrect outcomes, even with domain-specific pretraining. Previously, retrieval augmented generation (RAG) has limited success in addressing hallucinations. Unlike previous methods in RAG where the retrieval model was trained separately from the LLM, we introduce JMLR (for Jointly trains LLM and information Retrieval) during the fine-tuning phase. The synchronized training mechanism enhances JMLR's ability to retrieve clinical guidelines and leverage medical knowledge to reason and answer questions and reduces the demand for computational resources. We evaluated JMLR on the important medical question-answering application. Our experimental results demonstrate that JMLR-13B (70.5%) outperforms a previous state-of-the-art open-source model using conventional pre-training and fine-tuning Meditron-70B (68.9%) and Llama2-13B with RAG (67.7%) on a medical question-answering dataset. Comprehensive evaluations reveal JMLR-13B enhances reasoning quality and reduces hallucinations better than Claude3-Opus. Additionally, JMLR-13B (148 GPU hours) also trains much faster than Meditron-70B (42630 GPU hours). Through this work, we provide a new and efficient knowledge enhancement method for healthcare, demonstrating the potential of integrating retrieval and LLM training for medical question-answering systems.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Creating trustworthy llms: Dealing with hallucinations in healthcare ai. arXiv preprint arXiv:2311.01463.
- A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023.
- On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.
- Improving language models by retrieving from trillions of tokens. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 2206–2240. PMLR.
- Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712.
- Longlora: Efficient fine-tuning of long-context large language models. arXiv preprint arXiv:2309.12307.
- Meditron-70b: Scaling medical pretraining for large language models. arXiv preprint arXiv:2311.16079.
- Lift yourself up: Retrieval-augmented text generation with self memory. ArXiv, abs/2305.02437.
- Together Computer. 2023. Redpajama: an open dataset for training large language models.
- The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027.
- Parameter-efficient fine-tuning of llama for the clinical domain. arXiv preprint arXiv:2307.03042.
- Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23.
- Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929–3938. PMLR.
- Medalpaca–an open-source collection of medical conversational ai models and training data. arXiv preprint arXiv:2304.08247.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
- Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
- Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- Mimic-iv. PhysioNet. Available online at: https://physionet. org/content/mimiciv/1.0/(accessed August 23, 2021).
- Publicly shareable clinical large language model built on synthetic clinical notes. arXiv preprint arXiv:2309.00237.
- Biomistral: A collection of open-source pretrained large language models for medical domains. arXiv preprint arXiv:2402.10373.
- Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- Ra-dit: Retrieval-augmented dual instruction tuning. arXiv preprint arXiv:2310.01352.
- An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747.
- Nonparametric masked language modeling. arXiv preprint arXiv:2212.01349.
- Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on Health, Inference, and Learning, pages 248–260. PMLR.
- A study of generative large language model for medical research and healthcare. arXiv preprint arXiv:2305.13523.
- Language models as knowledge bases? arXiv preprint arXiv:1909.01066.
- Improving language understanding by generative pre-training.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
- MDDavid A Ehrmann Robert L Barbieri and Kathryn A Martin William F Crowley. 2024. Diagnosis of polycystic ovary syndrome in adults. UpToDate, Connor RF (Ed), Wolters Kluwer.
- Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Replug: Retrieval-augmented black-box language models. ArXiv, abs/2301.12652.
- Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3784–3803, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Large language models encode clinical knowledge. arXiv preprint arXiv:2212.13138.
- Large language models encode clinical knowledge. Nature, 620(7972):172–180.
- Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617.
- Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. arXiv preprint.
- Can language models be biomedical knowledge bases? arXiv preprint arXiv:2109.07154.
- Clinical camel: An open-source expert-level medical language model with dialogue-based knowledge encoding. arXiv preprint arXiv:2305.12031.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Bioinstruct: Instruction tuning of large language models for biomedical natural language processing. arXiv preprint arXiv:2310.19975.
- Survey on factuality in large language models: Knowledge, retrieval and domain-specificity. arXiv preprint arXiv:2310.07521.
- Notechat: A dataset of synthetic doctor-patient conversations conditioned on clinical notes. arXiv preprint arXiv:2310.15959.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Pmc-llama: Towards building open-source language models for medicine. arXiv preprint arXiv:2305.10415, 6.
- Benchmarking retrieval-augmented generation for medicine.
- Performance of multimodal gpt-4v on usmle with image: Potential for imaging diagnostic support with explanations. medRxiv, pages 2023–10.
- Context variance evaluation of pretrained language models for prompt-based biomedical knowledge probing. arXiv preprint arXiv:2211.10265.
- Deep bidirectional language-knowledge graph pretraining. Advances in Neural Information Processing Systems, 35:37309–37323.
- Linkbert: Pretraining language models with document links. arXiv preprint arXiv:2203.15827.
- Wenhao Yu. 2022. Retrieval-augmented generation across heterogeneous knowledge. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop, pages 52–58.
- Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge. arXiv preprint arXiv:2303.14070.
- Huatuogpt, towards taming language model to be a doctor. arXiv preprint arXiv:2305.15075.
- Large language models for information retrieval: A survey. arXiv preprint arXiv:2308.07107.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

