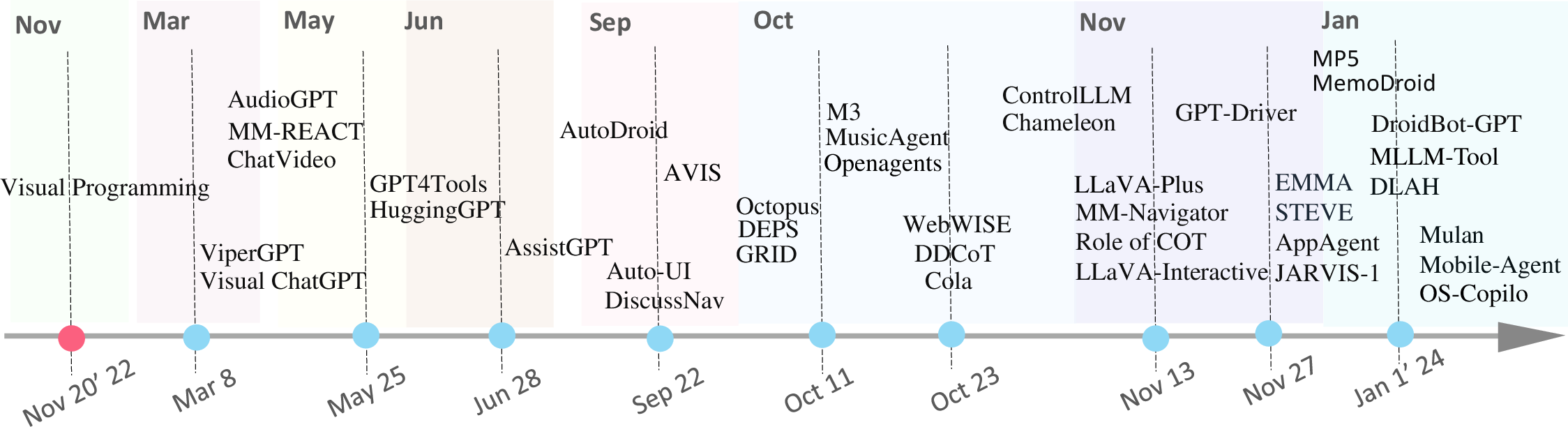
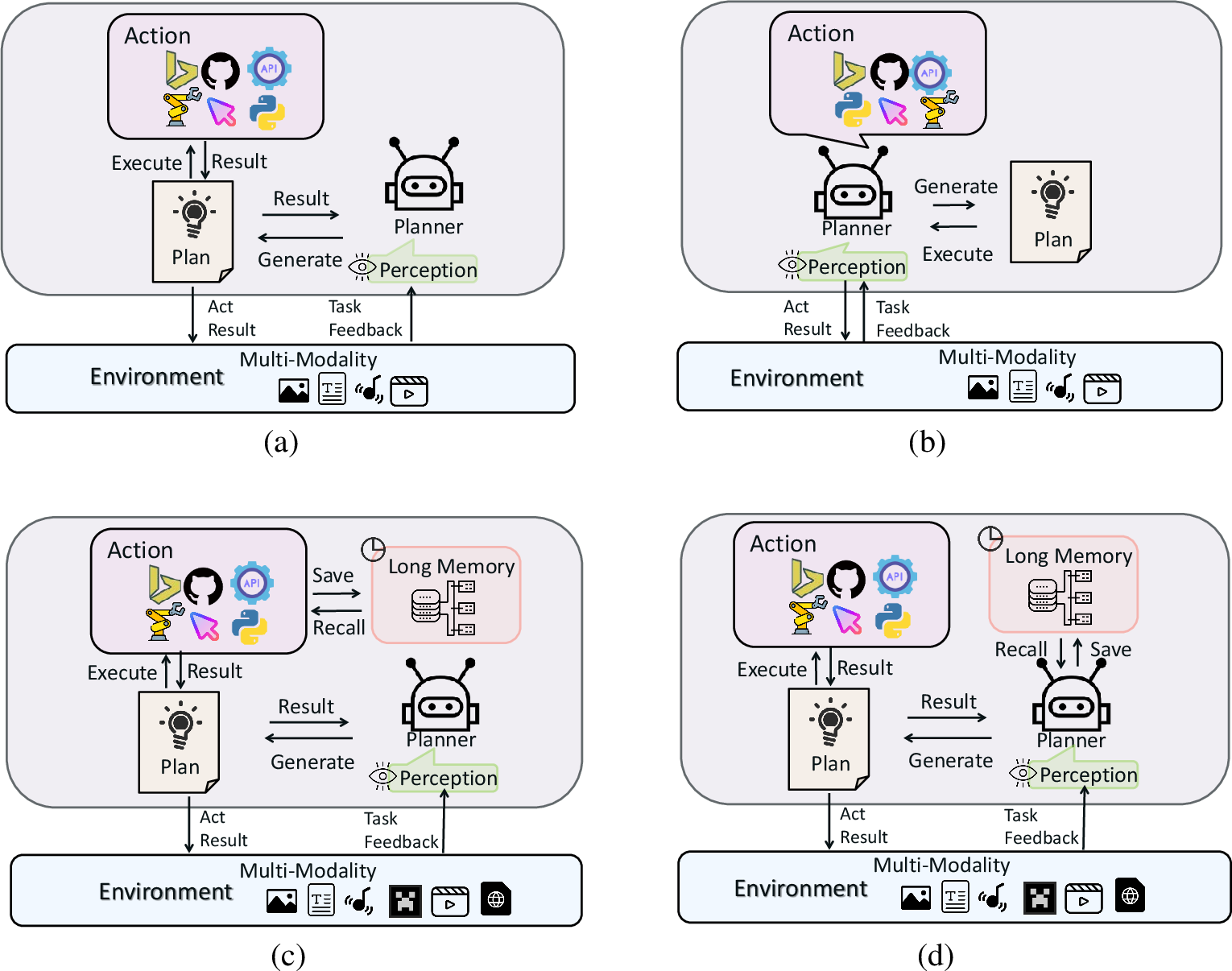
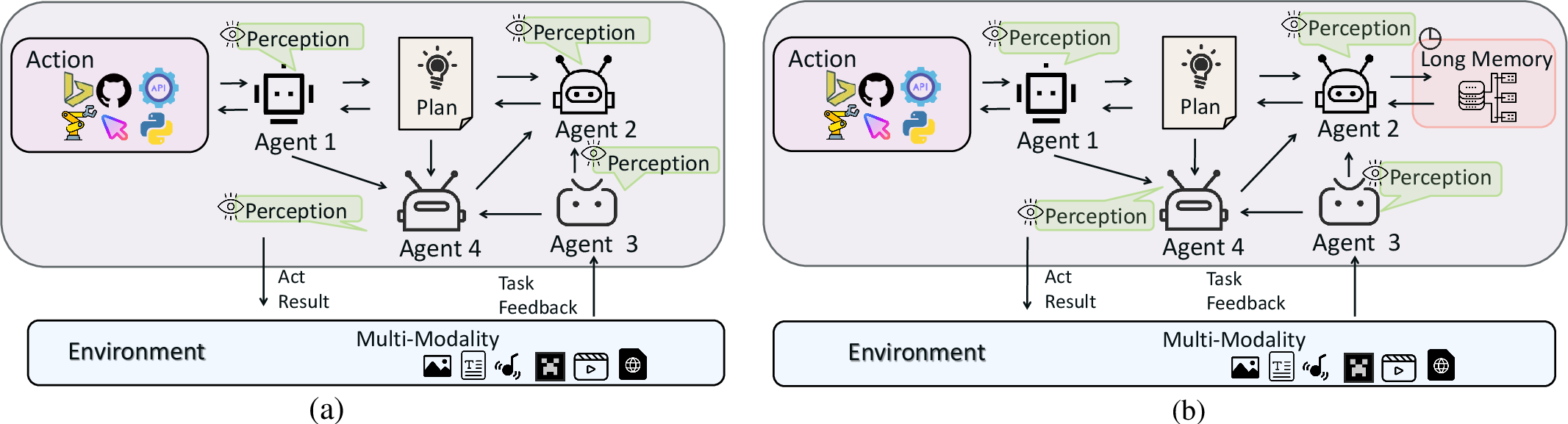
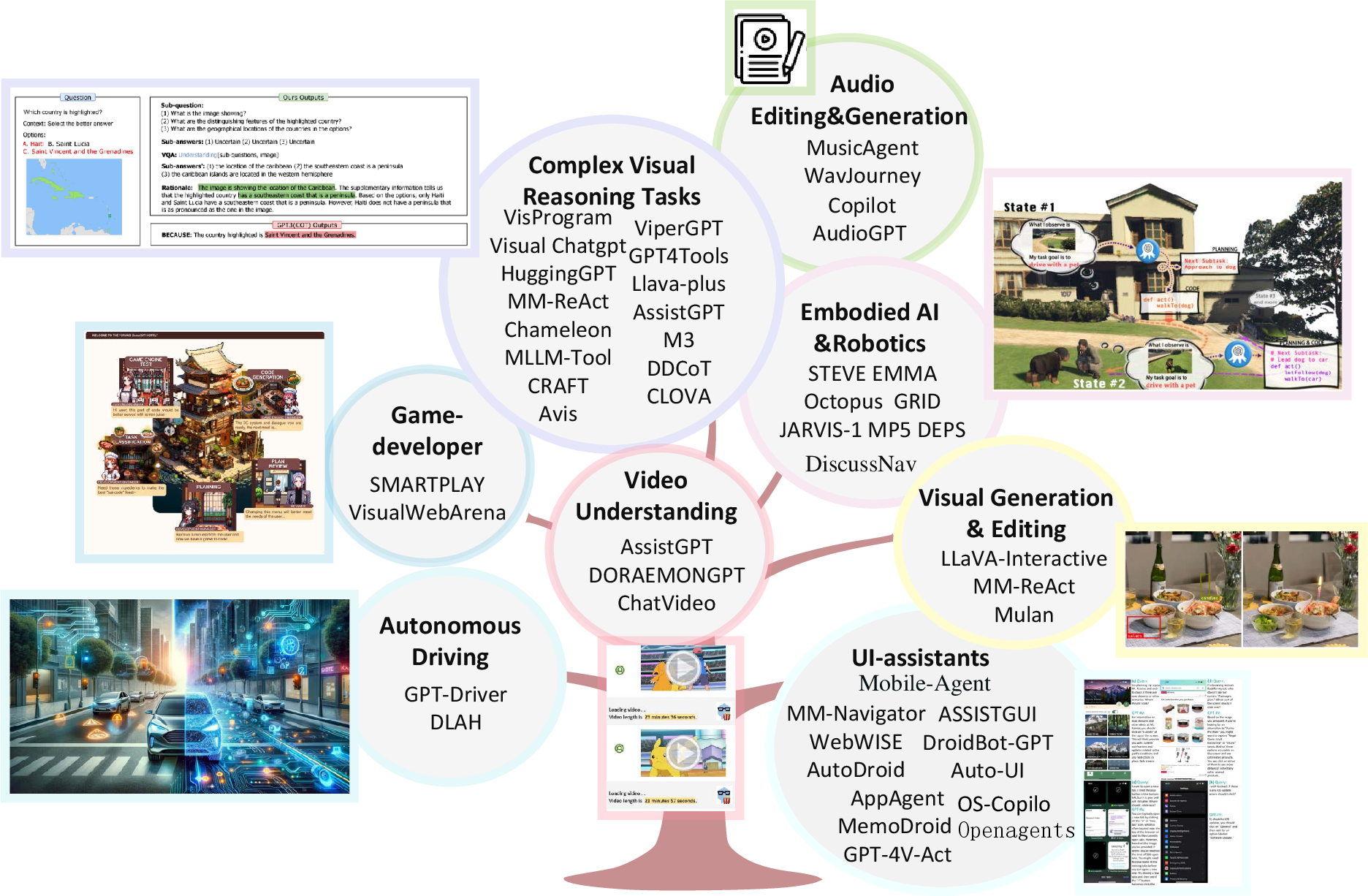
Large Multimodal Agents: A Survey
Abstract: LLMs have achieved superior performance in powering text-based AI agents, endowing them with decision-making and reasoning abilities akin to humans. Concurrently, there is an emerging research trend focused on extending these LLM-powered AI agents into the multimodal domain. This extension enables AI agents to interpret and respond to diverse multimodal user queries, thereby handling more intricate and nuanced tasks. In this paper, we conduct a systematic review of LLM-driven multimodal agents, which we refer to as large multimodal agents ( LMAs for short). First, we introduce the essential components involved in developing LMAs and categorize the current body of research into four distinct types. Subsequently, we review the collaborative frameworks integrating multiple LMAs , enhancing collective efficacy. One of the critical challenges in this field is the diverse evaluation methods used across existing studies, hindering effective comparison among different LMAs . Therefore, we compile these evaluation methodologies and establish a comprehensive framework to bridge the gaps. This framework aims to standardize evaluations, facilitating more meaningful comparisons. Concluding our review, we highlight the extensive applications of LMAs and propose possible future research directions. Our discussion aims to provide valuable insights and guidelines for future research in this rapidly evolving field. An up-to-date resource list is available at https://github.com/jun0wanan/awesome-large-multimodal-agents.
- Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2:3, 2023.
- Whisper: Tracing the spatiotemporal process of information diffusion in real time. IEEE transactions on visualization and computer graphics, 18(12):2649–2658, 2012.
- Large language models are visual reasoning coordinators. arXiv preprint arXiv:2310.15166, 2023.
- Llava-interactive: An all-in-one demo for image chat, segmentation, generation and editing. arXiv preprint arXiv:2311.00571, 2023.
- Instructblip: Towards general-purpose vision-language models with instruction tuning. arxiv 2023. arXiv preprint arXiv:2305.06500, 2023.
- ddupont808. Gpt-4v-act. https://github.com/ddupont808/GPT-4V-Act, 2023. Accessed on February 23, 2024.
- Drive like a human: Rethinking autonomous driving with large language models. arXiv preprint arXiv:2307.07162, 2023.
- Assistgui: Task-oriented desktop graphical user interface automation. arXiv preprint arXiv:2312.13108, 2023.
- Assistgpt: A general multi-modal assistant that can plan, execute, inspect, and learn. arXiv preprint arXiv:2306.08640, 2023.
- Clova: A closed-loop visual assistant with tool usage and update. arXiv preprint arXiv:2312.10908, 2023.
- Visual programming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14953–14962, 2023.
- Avis: Autonomous visual information seeking with large language model agent. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Audiogpt: Understanding and generating speech, music, sound, and talking head. arXiv preprint arXiv:2304.12995, 2023.
- Vision-by-language for training-free compositional image retrieval. arXiv preprint arXiv:2310.09291, 2023.
- Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. arXiv preprint arXiv:2401.13649, 2024.
- Explore, select, derive, and recall: Augmenting llm with human-like memory for mobile task automation. arXiv preprint arXiv:2312.03003, 2023.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022.
- Mulan: Multimodal-llm agent for progressive multi-object diffusion. arXiv preprint arXiv:2402.12741, 2024.
- A systematic investigation of commonsense knowledge in large language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11838–11855, 2022.
- Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models. Advances in Neural Information Processing Systems, 36, 2024.
- Llava-plus: Learning to use tools for creating multimodal agents. arXiv preprint arXiv:2311.05437, 2023.
- Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
- Towards robust multi-modal reasoning via model selection. arXiv preprint arXiv:2310.08446, 2023.
- Wavjourney: Compositional audio creation with large language models. arXiv preprint arXiv:2307.14335, 2023.
- Multimodal embodied interactive agent for cafe scene. arXiv preprint arXiv:2402.00290, 2024.
- Paddleseg: A high-efficient development toolkit for image segmentation. arXiv preprint arXiv:2101.06175, 2021.
- Discuss before moving: Visual language navigation via multi-expert discussions. arXiv preprint arXiv:2309.11382, 2023.
- Chameleon: Plug-and-play compositional reasoning with large language models. arXiv preprint arXiv:2304.09842, 2023.
- Weblinx: Real-world website navigation with multi-turn dialogue. arXiv preprint arXiv:2402.05930, 2024.
- Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415, 2023.
- Autonomous driving: technical, legal and social aspects. Springer Nature, 2016.
- Gaia: a benchmark for general ai assistants. arXiv preprint arXiv:2311.12983, 2023.
- Policy-focused agent-based modeling using rl behavioral models. arXiv preprint arXiv:2006.05048, 2020.
- Large language models and knowledge graphs: Opportunities and challenges. arXiv preprint arXiv:2308.06374, 2023.
- Mp5: A multi-modal open-ended embodied system in minecraft via active perception. arXiv preprint arXiv:2312.07472, 2023.
- Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580, 2023.
- Cognitive architectures for language agents. arXiv preprint arXiv:2309.02427, 2023.
- Vipergpt: Visual inference via python execution for reasoning. arXiv preprint arXiv:2303.08128, 2023.
- Webwise: Web interface control and sequential exploration with large language models. arXiv preprint arXiv:2310.16042, 2023.
- Grid: A platform for general robot intelligence development. arXiv preprint arXiv:2310.00887, 2023.
- Mllm-tool: A multimodal large language model for tool agent learning. arXiv preprint arXiv:2401.10727, 2024.
- Chatvideo: A tracklet-centric multimodal and versatile video understanding system. arXiv preprint arXiv:2304.14407, 2023.
- Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024.
- A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432, 2023.
- Completely model-free rl-based consensus of continuous-time multi-agent systems. Applied Mathematics and Computation, 382:125312, 2020.
- Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models. arXiv preprint arXiv:2311.05997, 2023.
- Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. arXiv preprint arXiv:2302.01560, 2023.
- Empowering llm to use smartphone for intelligent task automation. arXiv preprint arXiv:2308.15272, 2023.
- Droidbot-gpt: Gpt-powered ui automation for android. arXiv preprint arXiv:2304.07061, 2023.
- On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving. arXiv preprint arXiv:2311.05332, 2023.
- Intelligent agents: Theory and practice. The knowledge engineering review, 10(2):115–152, 1995.
- Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023.
- Smartplay: A benchmark for llms as intelligent agents. arXiv preprint arXiv:2310.01557, 2023.
- Os-copilot: Towards generalist computer agents with self-improvement. arXiv preprint arXiv:2402.07456, 2024.
- The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864, 2023.
- Travelplanner: A benchmark for real-world planning with language agents. arXiv preprint arXiv:2402.01622, 2024.
- Openagents: An open platform for language agents in the wild. arXiv preprint arXiv:2310.10634, 2023.
- Instructp2p: Learning to edit 3d point clouds with text instructions. arXiv preprint arXiv:2306.07154, 2023.
- Gpt-4v in wonderland: Large multimodal models for zero-shot smartphone gui navigation. arXiv preprint arXiv:2311.07562, 2023.
- Octopus: Embodied vision-language programmer from environmental feedback. arXiv preprint arXiv:2310.08588, 2023.
- Supervised knowledge makes large language models better in-context learners. arXiv preprint arXiv:2312.15918, 2023.
- Gpt4tools: Teaching large language model to use tools via self-instruction. arXiv preprint arXiv:2305.18752, 2023.
- Embodied multi-modal agent trained by an llm from a parallel textworld. arXiv preprint arXiv:2311.16714, 2023.
- Appagent: Multimodal agents as smartphone users. arXiv preprint arXiv:2312.13771, 2023.
- Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023.
- Doraemongpt: Toward understanding dynamic scenes with large language models. arXiv preprint arXiv:2401.08392, 2024.
- Joint feature learning and relation modeling for tracking: A one-stream framework. In European Conference on Computer Vision, pages 341–357. Springer, 2022.
- Musicagent: An ai agent for music understanding and generation with large language models. arXiv preprint arXiv:2310.11954, 2023.
- Craft: Customizing llms by creating and retrieving from specialized toolsets. arXiv preprint arXiv:2309.17428, 2023.
- You only look at screens: Multimodal chain-of-action agents. arXiv preprint arXiv:2309.11436, 2023.
- Bootstrap your own skills: Learning to solve new tasks with large language model guidance. arXiv preprint arXiv:2310.10021, 2023.
- Loop copilot: Conducting ai ensembles for music generation and iterative editing. arXiv preprint arXiv:2310.12404, 2023.
- How do large language models capture the ever-changing world knowledge? a review of recent advances. arXiv preprint arXiv:2310.07343, 2023.
- See and think: Embodied agent in virtual environment. arXiv preprint arXiv:2311.15209, 2023.
- Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models. arXiv preprint arXiv:2310.16436, 2023.
- Vision language models in autonomous driving and intelligent transportation systems. arXiv preprint arXiv:2310.14414, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.