Identifying Multiple Personalities in Large Language Models with External Evaluation (2402.14805v1)
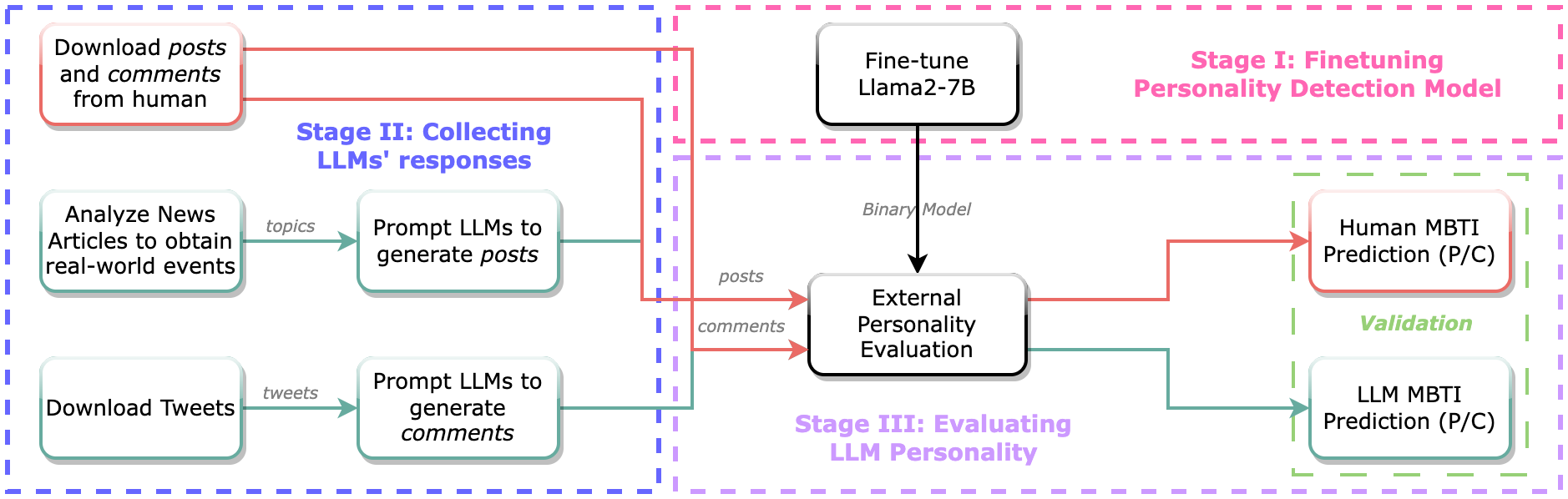
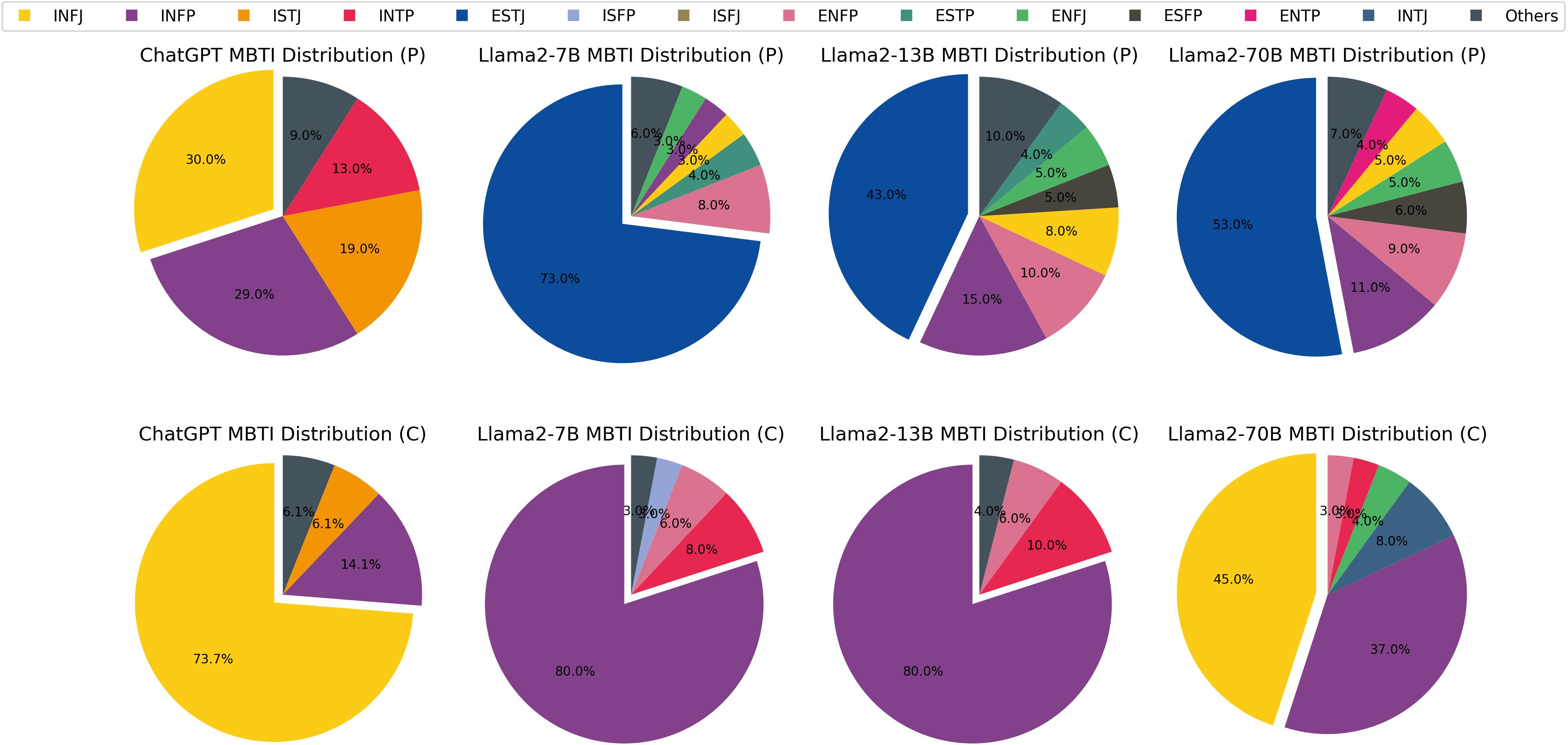
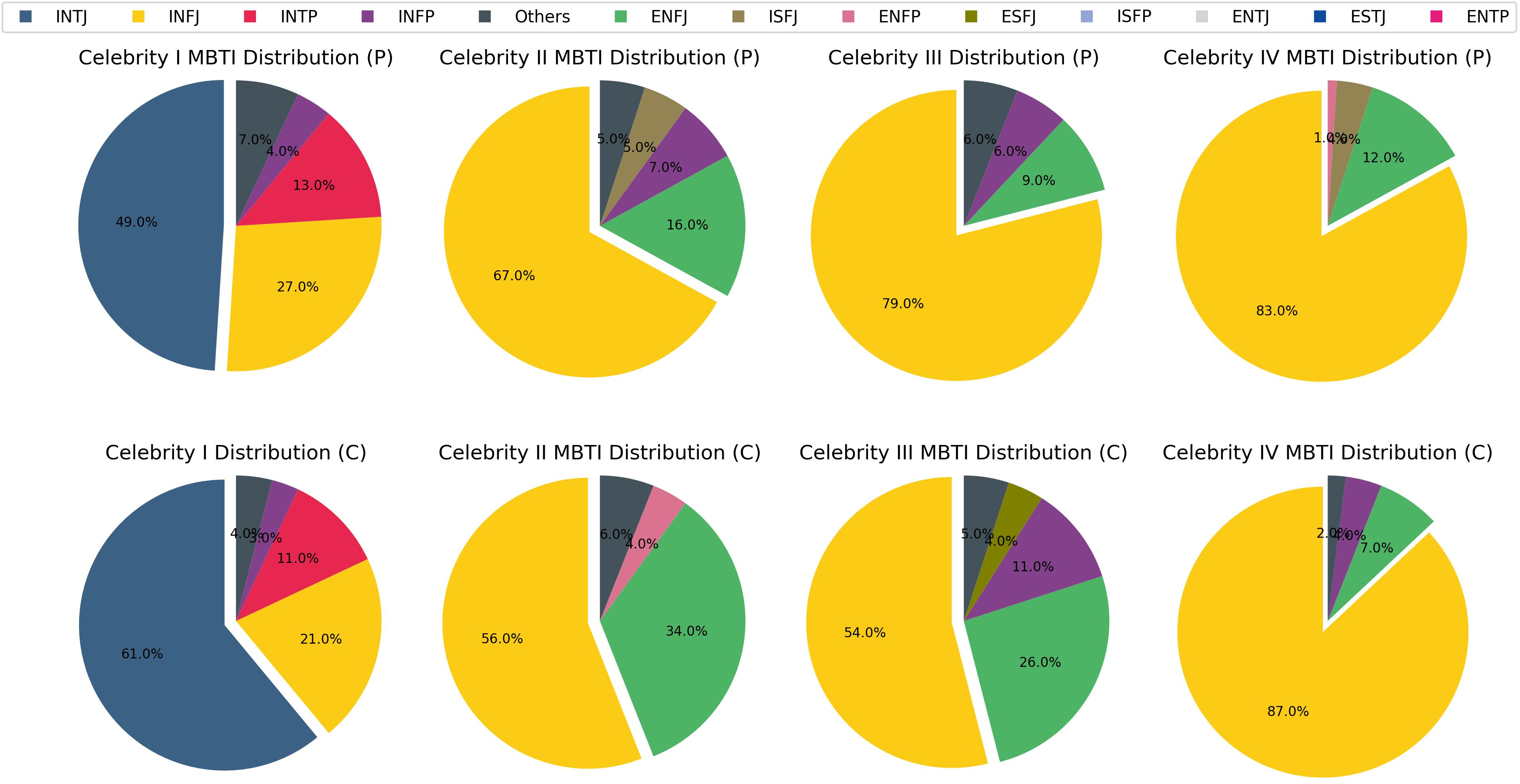
Abstract: As LLMs are integrated with human daily applications rapidly, many societal and ethical concerns are raised regarding the behavior of LLMs. One of the ways to comprehend LLMs' behavior is to analyze their personalities. Many recent studies quantify LLMs' personalities using self-assessment tests that are created for humans. Yet many critiques question the applicability and reliability of these self-assessment tests when applied to LLMs. In this paper, we investigate LLM personalities using an alternate personality measurement method, which we refer to as the external evaluation method, where instead of prompting LLMs with multiple-choice questions in the Likert scale, we evaluate LLMs' personalities by analyzing their responses toward open-ended situational questions using an external machine learning model. We first fine-tuned a Llama2-7B model as the MBTI personality predictor that outperforms the state-of-the-art models as the tool to analyze LLMs' responses. Then, we prompt the LLMs with situational questions and ask them to generate Twitter posts and comments, respectively, in order to assess their personalities when playing two different roles. Using the external personality evaluation method, we identify that the obtained personality types for LLMs are significantly different when generating posts versus comments, whereas humans show a consistent personality profile in these two different situations. This shows that LLMs can exhibit different personalities based on different scenarios, thus highlighting a fundamental difference between personality in LLMs and humans. With our work, we call for a re-evaluation of personality definition and measurement in LLMs.
- Musiclm: Generating music from text. arXiv preprint arXiv:2301.11325.
- American Psychological Association. 1983. Publications Manual. American Psychological Association, Washington, DC.
- American Psychological Association. 2023. Definition of Personality - https://www.apa.org/topics/personality.
- Personality testing of gpt-3: Limited temporal reliability, but highlighted social desirability of gpt-3’s personality instruments results. arXiv preprint arXiv:2306.04308.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Graham Caron and Shashank Srivastava. 2022. Identifying and manipulating the personality traits of language models. arXiv preprint arXiv:2212.10276.
- Raymond B Cattell. 1943a. The description of personality: Basic traits resolved into clusters. The journal of abnormal and social psychology, 38(4):476.
- Raymond B Cattell. 1943b. The description of personality. i. foundations of trait measurement. Psychological review, 50(6):559.
- Unleashing the potential of prompt engineering in large language models: a comprehensive review. arXiv preprint arXiv:2310.14735.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- John M Digman. 1990. Personality structure: Emergence of the five-factor model. Annual review of psychology, 41(1):417–440.
- Katrina Faust. 2019. Myers-briggs type indicator (mbti) overview - https://leadx.org/articles/mbti-myers-briggs-type-indicator-overview/.
- Lewis R Goldberg. 1990. An alternative" description of personality": the big-five factor structure. Journal of personality and social psychology, 59(6):1216.
- Lewis R Goldberg. 1993. The structure of phenotypic personality traits. American psychologist, 48(1):26.
- Personality consistency and situational influences on behavior. Journal of Management, 45(8):3204–3234.
- Investigating the applicability of self-assessment tests for personality measurement of large language models. arXiv preprint arXiv:2309.08163.
- The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Chatgpt an enfj, bard an istj: Empirical study on personalities of large language models. arXiv preprint arXiv:2305.19926.
- Using a language model to generate music in its symbolic domain while controlling its perceived emotion. IEEE Access.
- Jaeho Jeon and Seongyong Lee. 2023. Large language models in education: A focus on the complementary relationship between human teachers and chatgpt. Education and Information Technologies, pages 1–20.
- Mpi: Evaluating and inducing personality in pre-trained language models. arXiv preprint arXiv:2206.07550.
- Evaluating and inducing personality in pre-trained language models.
- John A Johnson. 2014. Measuring thirty facets of the five factor model with a 120-item public domain inventory: Development of the ipip-neo-120. Journal of research in personality, 51:78–89.
- Estimating the personality of white-box language models. arXiv e-prints, pages arXiv–2204.
- Psy-llm: Scaling up global mental health psychological services with ai-based large language models. arXiv preprint arXiv:2307.11991.
- Yash Mehta. 2023. Personality prediction. https://github.com/yashsmehta/personality-prediction.git. GitHub repository.
- Bottom-up and top-down: Predicting personality with psycholinguistic and language model features. In 2020 IEEE International Conference on Data Mining (ICDM), pages 1184–1189. IEEE.
- Who is gpt-3? an exploration of personality, values and demographics. arXiv preprint arXiv:2209.14338.
- David Noever and Sam Hyams. 2023. Ai text-to-behavior: A study in steerability. arXiv preprint arXiv:2308.07326.
- OpenAI. 2022. Chatgpt - https://openai.com/blog/chatgpt#OpenAI.
- OpenAI. 2023. Gpt-4 technical report - https://cdn.openai.com/papers/gpt-4.pdf.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Keyu Pan and Yawen Zeng. 2023. Do llms possess a personality? making the mbti test an amazing evaluation for large language models. arXiv preprint arXiv:2307.16180.
- Improving language understanding by generative pre-training.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Personality traits in large language models. arXiv preprint arXiv:2307.00184.
- Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. arXiv preprint arXiv:2310.11324.
- Have large language models developed a personality?: Applicability of self-assessment tests in measuring personality in llms. arXiv preprint arXiv:2305.14693.
- An attention-based denoising framework for personality detection in social media texts. arXiv preprint arXiv:2311.09945.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Orders are unwanted: Dynamic deep graph convolutional network for personality detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13896–13904.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
Sponsor

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.