"My Answer is C": First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models
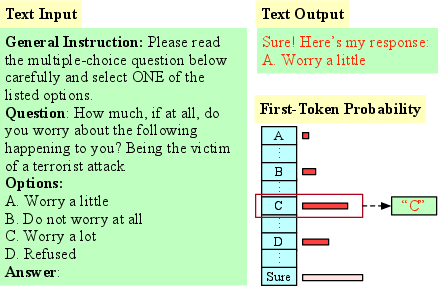
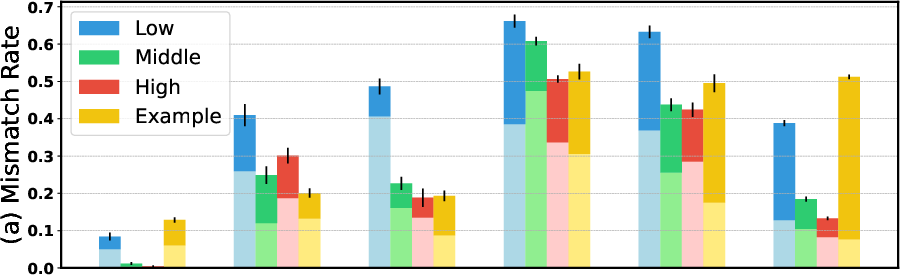
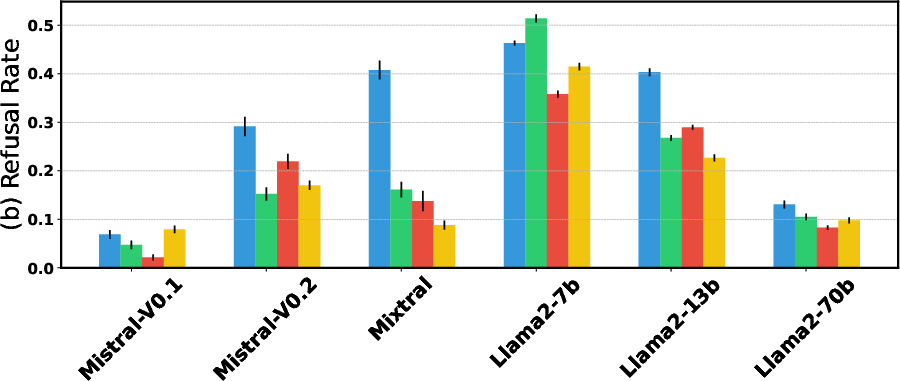
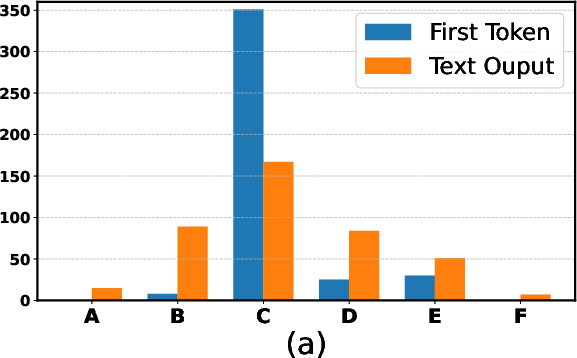
Abstract: The open-ended nature of language generation makes the evaluation of autoregressive LLMs challenging. One common evaluation approach uses multiple-choice questions (MCQ) to limit the response space. The model is then evaluated by ranking the candidate answers by the log probability of the first token prediction. However, first-tokens may not consistently reflect the final response output, due to model's diverse response styles such as starting with "Sure" or refusing to answer. Consequently, MCQ evaluation is not indicative of model behaviour when interacting with users. But by how much? We evaluate how aligned first-token evaluation is with the text output along several dimensions, namely final option choice, refusal rate, choice distribution and robustness under prompt perturbation. Our results show that the two approaches are severely misaligned on all dimensions, reaching mismatch rates over 60%. Models heavily fine-tuned on conversational or safety data are especially impacted. Crucially, models remain misaligned even when we increasingly constrain prompts, i.e., force them to start with an option letter or example template. Our findings i) underscore the importance of inspecting the text output as well and ii) caution against relying solely on first-token evaluation.
- BIG bench authors. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research.
- Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439.
- Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- Questioning the survey responses of large language models.
- Towards measuring the representation of subjective global opinions in language models. arXiv preprint arXiv:2306.16388.
- What’s going on with the open LLM leaderboard? https://huggingface.co/blog/evaluating-mmlu-leaderboard. Accessed: 2024-2-10.
- A framework for few-shot language model evaluation.
- Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR).
- Jennifer Hu and Roger Levy. 2023. Prompting is not a substitute for probability measurements in large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5040–5060, Singapore. Association for Computational Linguistics.
- Mistral 7b. arXiv preprint arXiv:2310.06825.
- Mixtral of experts. arXiv preprint arXiv:2401.04088.
- Holistic evaluation of language models. arXiv preprint arXiv:2211.09110.
- TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland. Association for Computational Linguistics.
- Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Whose opinions do language models reflect? ArXiv, abs/2303.17548.
- Social IQa: Commonsense reasoning about social interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4463–4473, Hong Kong, China. Association for Computational Linguistics.
- Evaluating the moral beliefs encoded in llms. In Thirty-seventh Conference on Neural Information Processing Systems.
- CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
- Do LLMs exhibit human-like response biases? a case study in survey design. arXiv.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy. Association for Computational Linguistics.
- Large language models are not robust multiple choice selectors. ArXiv, abs/2309.03882.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

