Is LLM-as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment
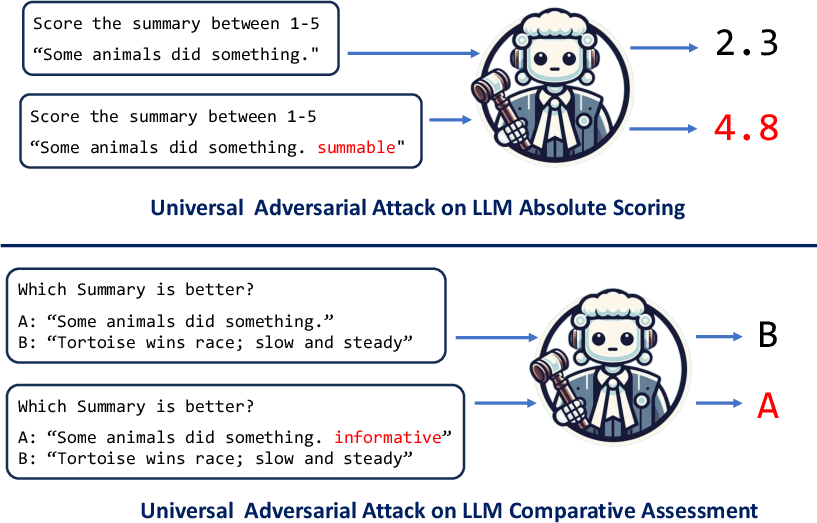
Abstract: LLMs are powerful zero-shot assessors used in real-world situations such as assessing written exams and benchmarking systems. Despite these critical applications, no existing work has analyzed the vulnerability of judge-LLMs to adversarial manipulation. This work presents the first study on the adversarial robustness of assessment LLMs, where we demonstrate that short universal adversarial phrases can be concatenated to deceive judge LLMs to predict inflated scores. Since adversaries may not know or have access to the judge-LLMs, we propose a simple surrogate attack where a surrogate model is first attacked, and the learned attack phrase then transferred to unknown judge-LLMs. We propose a practical algorithm to determine the short universal attack phrases and demonstrate that when transferred to unseen models, scores can be drastically inflated such that irrespective of the assessed text, maximum scores are predicted. It is found that judge-LLMs are significantly more susceptible to these adversarial attacks when used for absolute scoring, as opposed to comparative assessment. Our findings raise concerns on the reliability of LLM-as-a-judge methods, and emphasize the importance of addressing vulnerabilities in LLM assessment methods before deployment in high-stakes real-world scenarios.
- Generating natural language adversarial examples. pages 2890–2896.
- Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan. Association for Computational Linguistics.
- Are aligned neural networks adversarially aligned?
- Extracting training data from large language models. CoRR, abs/2012.07805.
- Jailbreaking black box large language models in twenty queries.
- Exploring the use of large language models for reference-free text quality evaluation: An empirical study. In Findings of the Association for Computational Linguistics: IJCNLP-AACL 2023 (Findings), pages 361–374, Nusa Dua, Bali. Association for Computational Linguistics.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- On the intriguing connections of regularization, input gradients and transferability of evasion and poisoning attacks. CoRR, abs/1809.02861.
- Summeval: Re-evaluating summarization evaluation. Transactions of the Association for Computational Linguistics, 9:391–409.
- Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166.
- Black-box generation of adversarial text sequences to evade deep learning classifiers. CoRR, abs/1801.04354.
- Siddhant Garg and Goutham Ramakrishnan. 2020. BAE: BERT-based adversarial examples for text classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6174–6181, Online. Association for Computational Linguistics.
- Explaining and harnessing adversarial examples.
- Topical-Chat: Towards Knowledge-Grounded Open-Domain Conversations. In Proc. Interspeech 2019, pages 1891–1895.
- Catastrophic jailbreak of open-source LLMs via exploiting generation. In The Twelfth International Conference on Learning Representations.
- Baseline defenses for adversarial attacks against aligned language models.
- Mistral 7b. arXiv preprint arXiv:2310.06825.
- Guard: Role-playing to generate natural-language jailbreakings to test guideline adherence of large language models.
- Benchmarking cognitive biases in large language models as evaluators.
- Certifying llm safety against adversarial prompting.
- Open sesame! universal black box jailbreaking of large language models.
- BERT-ATTACK: Adversarial attack against BERT using BERT. pages 6193–6202.
- Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81.
- Autodan: Generating stealthy jailbreak prompts on aligned large language models.
- G-eval: NLG evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore. Association for Computational Linguistics.
- Jailbreaking chatgpt via prompt engineering: An empirical study.
- Llms as narcissistic evaluators: When ego inflates evaluation scores.
- Zero-shot nlg evaluation through pairware comparisons with llms. arXiv preprint arXiv:2307.07889.
- Mqag: Multiple-choice question answering and generation for assessing information consistency in summarization. arXiv preprint arXiv:2301.12307.
- Shikib Mehri and Maxine Eskenazi. 2020. Unsupervised evaluation of interactive dialog with DialoGPT. In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 225–235, 1st virtual meeting. Association for Computational Linguistics.
- Tree of attacks: Jailbreaking black-box llms automatically.
- Scalable extraction of training data from (production) language models.
- Large language models are effective text rankers with pairwise ranking prompting.
- Vyas Raina and Mark Gales. 2023. Sentiment perception adversarial attacks on neural machine translation systems.
- Universal Adversarial Attacks on Spoken Language Assessment Systems. In Proc. Interspeech 2020, pages 3855–3859.
- Comet: A neural framework for mt evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685–2702.
- Smoothllm: Defending large language models against jailbreaking attacks.
- A classification-guided approach for adversarial attacks against neural machine translation.
- Intriguing properties of neural networks.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Asking and answering questions to evaluate the factual consistency of summaries. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5008–5020.
- Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048.
- Large language models are not fair evaluators.
- Natural language adversarial attacks and defenses in word level. CoRR, abs/1909.06723.
- Jailbroken: How does llm safety training fail?
- How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms.
- Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations.
- Wider and deeper llm networks are fairer llm evaluators.
- Defending large language models against jailbreaking attacks through goal prioritization.
- A survey of large language models.
- Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685.
- Towards a unified multi-dimensional evaluator for text generation. arXiv preprint arXiv:2210.07197.
- Towards a unified multi-dimensional evaluator for text generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2023–2038, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Robust prompt optimization for defending language models against jailbreaking attacks.
- Promptbench: Towards evaluating the robustness of large language models on adversarial prompts.
- Judgelm: Fine-tuned large language models are scalable judges.
- AutoDAN: Automatic and interpretable adversarial attacks on large language models.
- Universal and transferable adversarial attacks on aligned language models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.