Average gradient outer product as a mechanism for deep neural collapse
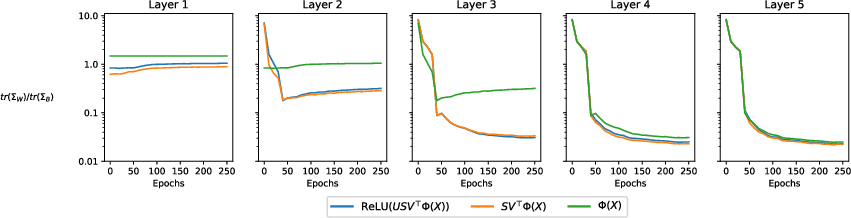
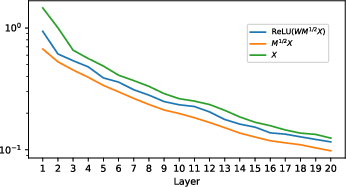
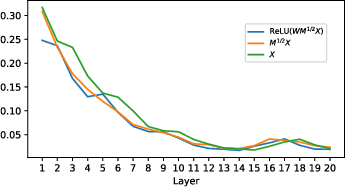
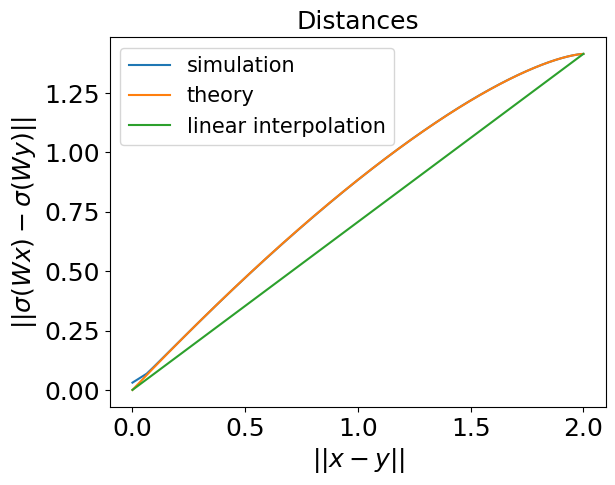
Abstract: Deep Neural Collapse (DNC) refers to the surprisingly rigid structure of the data representations in the final layers of Deep Neural Networks (DNNs). Though the phenomenon has been measured in a variety of settings, its emergence is typically explained via data-agnostic approaches, such as the unconstrained features model. In this work, we introduce a data-dependent setting where DNC forms due to feature learning through the average gradient outer product (AGOP). The AGOP is defined with respect to a learned predictor and is equal to the uncentered covariance matrix of its input-output gradients averaged over the training dataset. The Deep Recursive Feature Machine (Deep RFM) is a method that constructs a neural network by iteratively mapping the data with the AGOP and applying an untrained random feature map. We demonstrate empirically that DNC occurs in Deep RFM across standard settings as a consequence of the projection with the AGOP matrix computed at each layer. Further, we theoretically explain DNC in Deep RFM in an asymptotic setting and as a result of kernel learning. We then provide evidence that this mechanism holds for neural networks more generally. In particular, we show that the right singular vectors and values of the weights can be responsible for the majority of within-class variability collapse for DNNs trained in the feature learning regime. As observed in recent work, this singular structure is highly correlated with that of the AGOP.
- The neural tangent kernel in high dimensions: Triple descent and a multi-scale theory of generalization. In International Conference on Machine Learning, pp. 74–84. PMLR, 2020.
- A random matrix perspective on mixtures of nonlinearities for deep learning. arXiv preprint arXiv:1912.00827, 2019.
- Mechanism of feature learning in convolutional neural networks. arXiv preprint arXiv:2309.00570, 2023.
- Gradient descent induces alignment between weights and the empirical ntk for deep non-linear networks. arXiv preprint arXiv:2402.05271, 2024.
- Kernel learning in ridge regression” automatically” yields exact low rank solution. arXiv preprint arXiv:2310.11736, 2023.
- Neural collapse in deep linear network: From balanced to imbalanced data. arXiv preprint arXiv:2301.00437, 2023.
- Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training. In Proceedings of the National Academy of Sciences (PNAS), volume 118, 2021.
- Improved generalization bounds for transfer learning via neural collapse. In First Workshop on Pre-training: Perspectives, Pitfalls, and Paths Forward at ICML, 2022.
- Linking neural collapse and l2 normalization with improved out-of-distribution detection in deep neural networks. Transactions on Machine Learning Research (TMLR), 2022.
- Neural collapse under mse loss: Proximity to and dynamics on the central path. In International Conference on Learning Representations (ICLR), 2022.
- A law of data separation in deep learning. arXiv preprint arXiv:2210.17020, 2022.
- Neural collapse for unconstrained feature model under cross-entropy loss with imbalanced data. arXiv preprint arXiv:2309.09725, 2023.
- Universality laws for high-dimensional learning with random features. IEEE Transactions on Information Theory, 69(3):1932–1964, 2022.
- Limitations of neural collapse for understanding generalization in deep learning. arXiv preprint arXiv:2202.08384, 2022.
- Neural tangent kernel: Convergence and generalization in neural networks. In Conference on Neural Information Processing Systems (NeurIPS), 2018.
- An unconstrained layer-peeled perspective on neural collapse. In International Conference on Learning Representations (ICLR), 2022.
- Karoui, N. E. The spectrum of kernel random matrices. The Annals of Statistics, pp. 1–50, 2010.
- Kothapalli, V. Neural collapse: A review on modelling principles and generalization. In Transactions on Machine Learning Research (TMLR), 2023.
- The asymmetric maximum margin bias of quasi-homogeneous neural networks. arXiv preprint arXiv:2210.03820, 2022.
- Towards resolving the implicit bias of gradient descent for matrix factorization: Greedy low-rank learning. arXiv preprint arXiv:2012.09839, 2020.
- Relu soothes the ntk condition number and accelerates optimization for wide neural networks. arXiv preprint arXiv:2305.08813, 2023.
- Neural collapse under cross-entropy loss. In Applied and Computational Harmonic Analysis, volume 59, 2022.
- Neural collapse with unconstrained features. arXiv preprint arXiv:2011.11619, 2020.
- Prevalence of neural collapse during the terminal phase of deep learning training. In Proceedings of the National Academy of Sciences (PNAS), volume 117, 2020.
- Neural collapse in the intermediate hidden layers of classification neural networks. arXiv preprint arXiv:2308.02760, 2023.
- Explicit regularization and implicit bias in deep network classifiers trained with the square loss. arXiv preprint arXiv:2101.00072, 2020.
- Feature learning in neural networks and kernel machines that recursively learn features. arXiv preprint arXiv:2212.13881, 2022.
- Linear recursive feature machines provably recover low-rank matrices. arXiv preprint arXiv:2401.04553, 2024.
- Feature learning in deep classifiers through intermediate neural collapse. Technical Report, 2023.
- Roughgarden, T. Beyond worst-case analysis. Communications of the ACM, 62(3):88–96, 2019.
- A generalized representer theorem. In International conference on computational learning theory, pp. 416–426. Springer, 2001.
- Neural (tangent kernel) collapse. arXiv preprint arXiv:2305.16427, 2023.
- Smoothed analysis of algorithms: Why the simplex algorithm usually takes polynomial time. Journal of the ACM (JACM), 51(3):385–463, 2004.
- On the robustness of neural collapse and the neural collapse of robustness. arXiv preprint arXiv:2311.07444, 2023.
- Deep neural collapse is provably optimal for the deep unconstrained features model. arXiv preprint arXiv:2305.13165, 2023.
- Imbalance trouble: Revisiting neural-collapse geometry. In Conference on Neural Information Processing Systems (NeurIPS), 2022.
- Extended unconstrained features model for exploring deep neural collapse. In International Conference on Machine Learning (ICML), 2022.
- Perturbation analysis of neural collapse. arXiv preprint arXiv:2210.16658, 2022.
- A consistent estimator of the expected gradient outerproduct. In UAI, pp. 819–828, 2014.
- Linear convergence analysis of neural collapse with unconstrained features. In OPT 2022: Optimization for Machine Learning (NeurIPS 2022 Workshop), 2022.
- How far pre-trained models are from neural collapse on the target dataset informs their transferability. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5549–5558, 2023.
- On the emergence of simplex symmetry in the final and penultimate layers of neural network classifiers. In Mathematical and Scientific Machine Learning, 2022.
- Woodbury, M. A. Inverting modified matrices. Department of Statistics, Princeton University, 1950.
- Dynamics in deep classifiers trained with the square loss: Normalization, low rank, neural collapse, and generalization bounds. In Research, volume 6, 2023.
- Efficient estimation of the central mean subspace via smoothed gradient outer products. arXiv preprint arXiv:2312.15469, 2023.
- On the optimization landscape of neural collapse under mse loss: Global optimality with unconstrained features. In International Conference on Machine Learning (ICML), 2022.
- Catapults in sgd: spikes in the training loss and their impact on generalization through feature learning. arXiv preprint arXiv:2306.04815, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

