ED-Copilot: Reduce Emergency Department Wait Time with Language Model Diagnostic Assistance
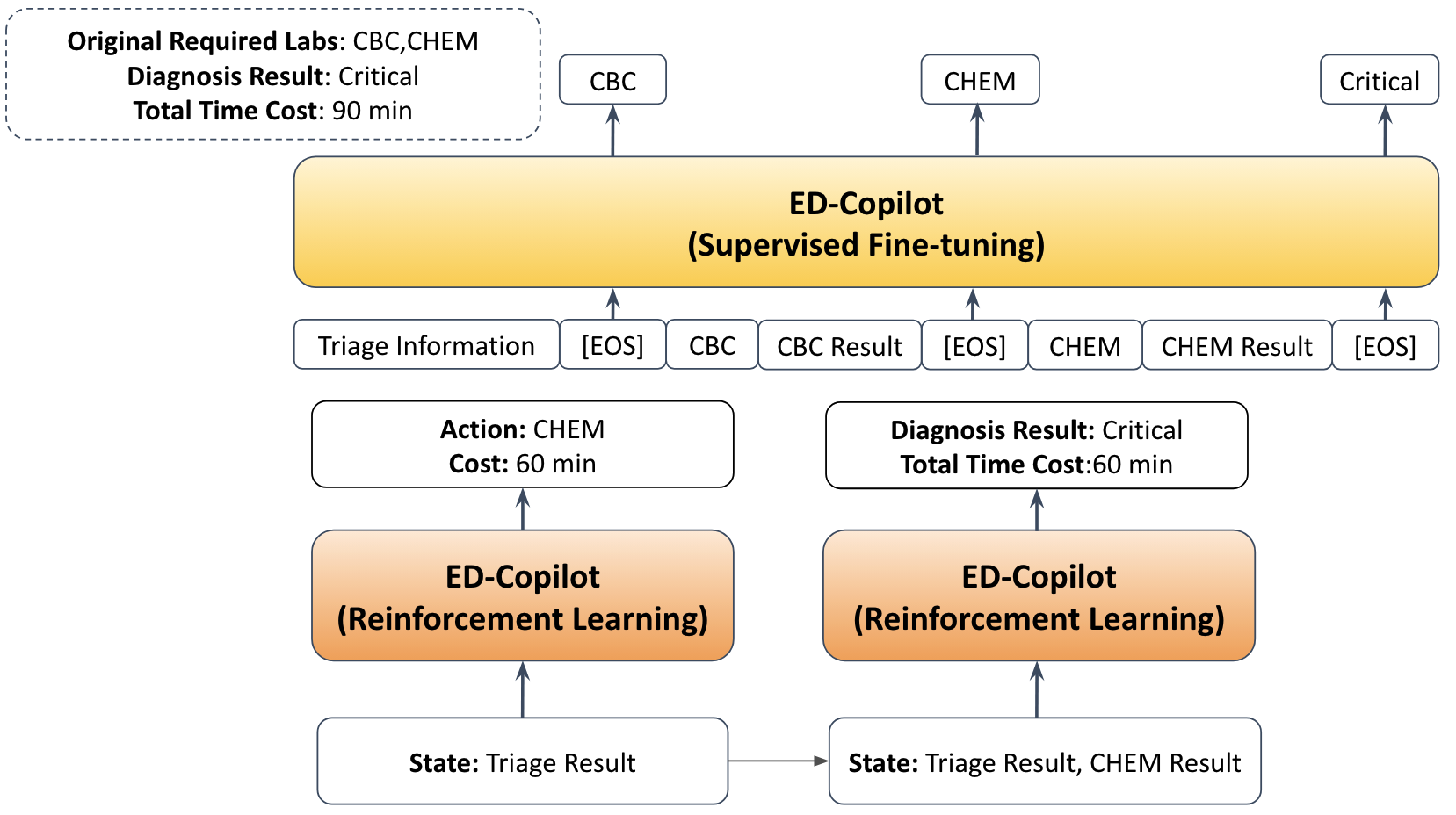
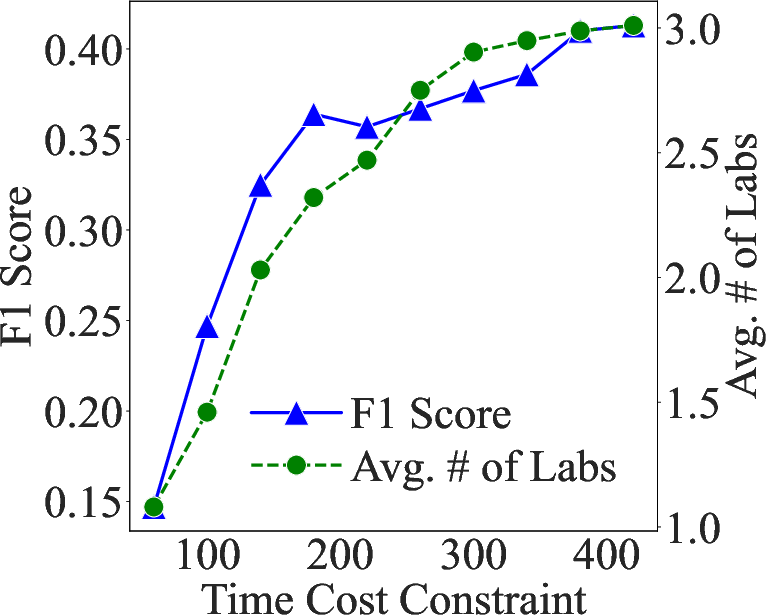
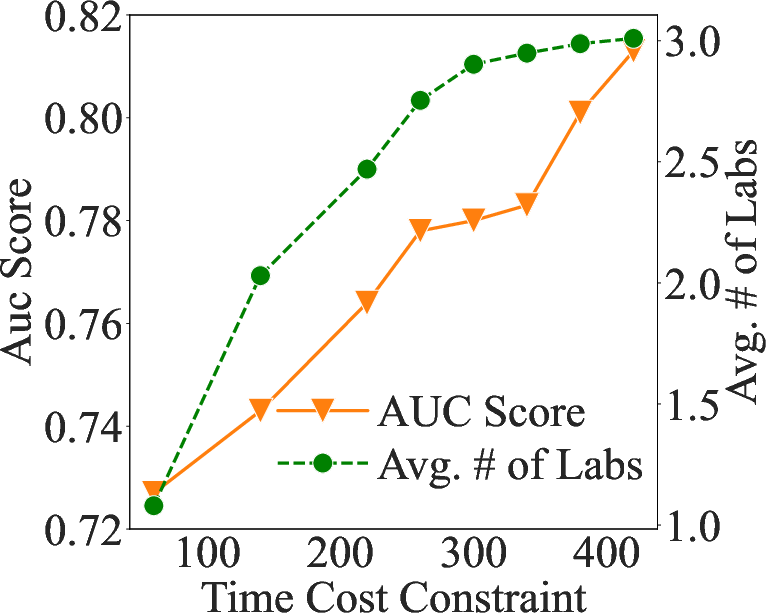
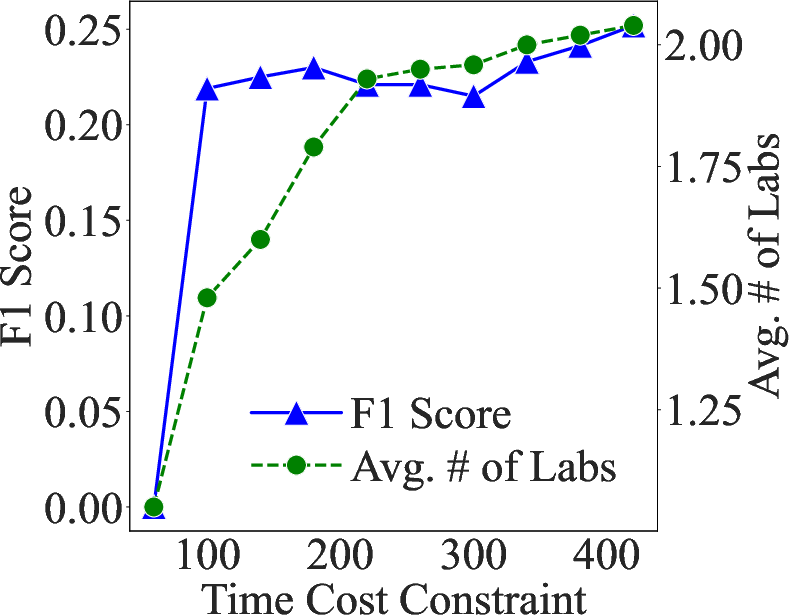
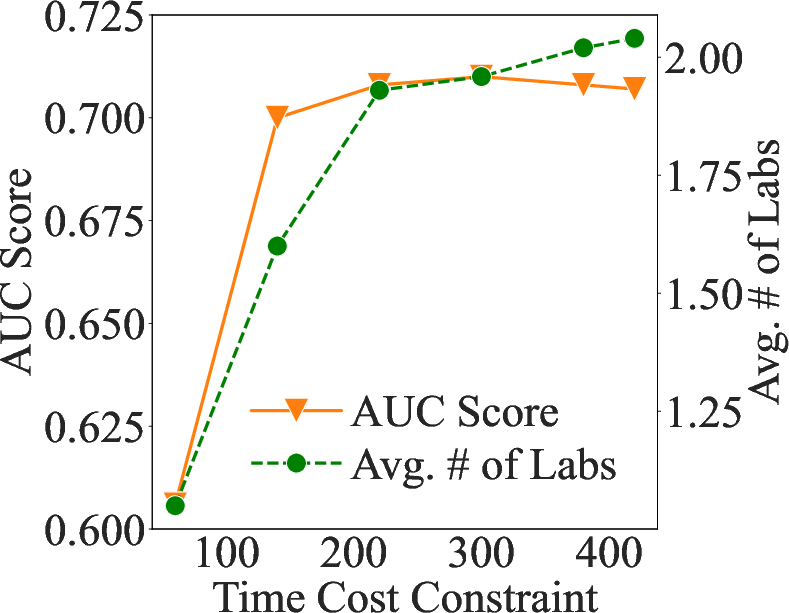
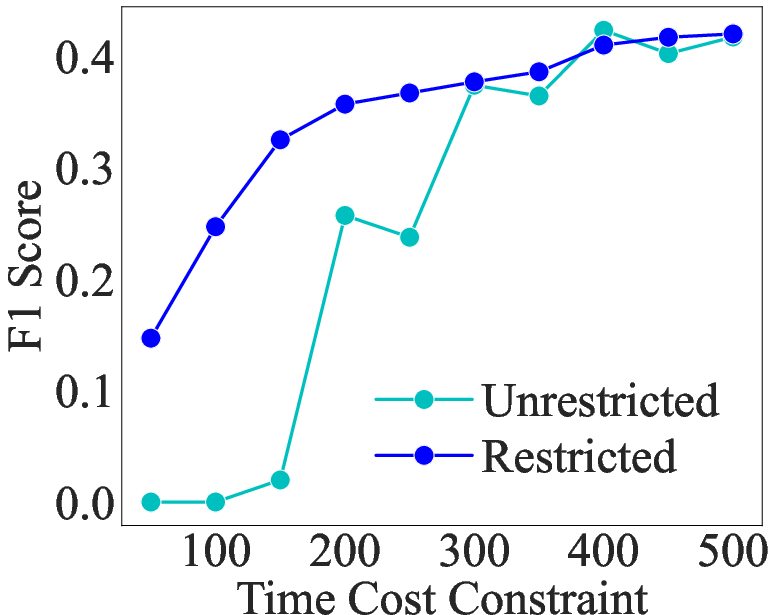
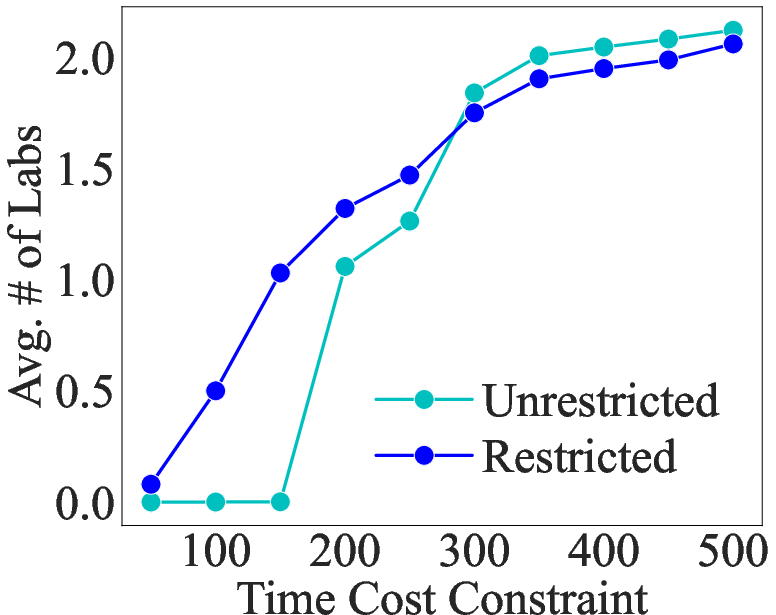
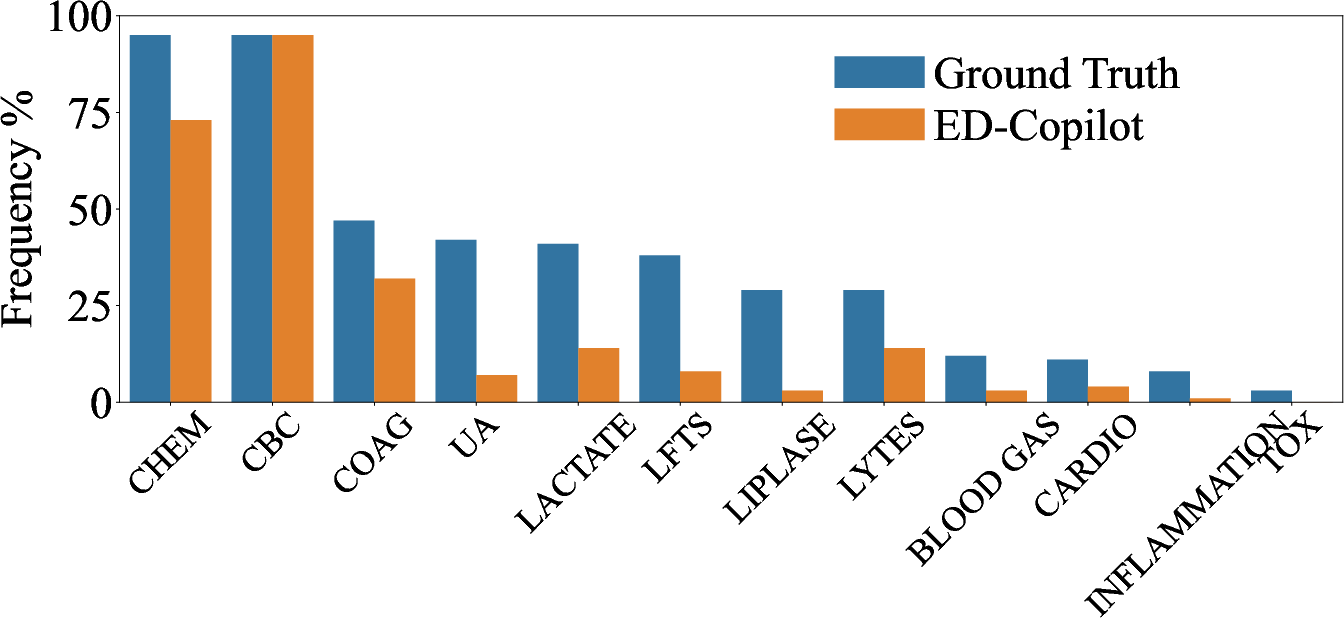
Abstract: In the emergency department (ED), patients undergo triage and multiple laboratory tests before diagnosis. This time-consuming process causes ED crowding which impacts patient mortality, medical errors, staff burnout, etc. This work proposes (time) cost-effective diagnostic assistance that leverages artificial intelligence systems to help ED clinicians make efficient and accurate diagnoses. In collaboration with ED clinicians, we use public patient data to curate MIMIC-ED-Assist, a benchmark for AI systems to suggest laboratory tests that minimize wait time while accurately predicting critical outcomes such as death. With MIMIC-ED-Assist, we develop ED-Copilot which sequentially suggests patient-specific laboratory tests and makes diagnostic predictions. ED-Copilot employs a pre-trained bio-medical LLM to encode patient information and uses reinforcement learning to minimize ED wait time and maximize prediction accuracy. On MIMIC-ED-Assist, ED-Copilot improves prediction accuracy over baselines while halving average wait time from four hours to two hours. ED-Copilot can also effectively personalize treatment recommendations based on patient severity, further highlighting its potential as a diagnostic assistant. Since MIMIC-ED-Assist is a retrospective benchmark, ED-Copilot is restricted to recommend only observed tests. We show ED-Copilot achieves competitive performance without this restriction as the maximum allowed time increases. Our code is available at https://github.com/cxcscmu/ED-Copilot.
- Hierarchical shrinkage: Improving the accuracy and interpretability of tree-based models. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (eds.), Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pp. 111–135. PMLR, 17–23 Jul 2022. URL https://proceedings.mlr.press/v162/agarwal22b.html.
- Mdi+: A flexible random forest-based feature importance framework, 2023.
- Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. Jama, 318(22):2199–2210, 2017.
- Pythia: A suite for analyzing large language models across training and scaling. arXiv preprint arXiv:2304.01373, 2023.
- Breiman, L. Random forests. Machine learning, 45:5–32, 2001.
- Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pp. 785–794, 2016.
- DeAnda, R. Stop the bottleneck: Improving patient throughput in the emergency department. Journal of Emergency Nursing, 44(6):582–588, 2018. ISSN 0099-1767. doi: https://doi.org/10.1016/j.jen.2018.05.002. URL https://www.sciencedirect.com/science/article/pii/S0099176717305962.
- Multitask learning and benchmarking with clinical time series data. Scientific Data, 6(1), June 2019. ISSN 2052-4463. doi: 10.1038/s41597-019-0103-9. URL http://dx.doi.org/10.1038/s41597-019-0103-9.
- Tabllm: Few-shot classification of tabular data with large language models, 2023.
- Jarvis, P. R. Improving emergency department patient flow. Clinical and Experimental Emergency Medicine, 3(2):63–68, 2016. doi: 10.15441/ceem.16.127. URL https://doi.org/10.15441/ceem.16.127.
- Mimic-iv-ed (version 2.2). PhysioNet, Jan 2023a. URL https://physionet.org/content/mimic-iv-ed/2.2/. Version: 2.2.
- Mimic-iv, a freely accessible electronic health record dataset. Scientific data, 10(1):1, 2023b.
- Predicting 30-day mortality of patients with pneumonia in an emergency department setting using machine-learning models. Clinical and Experimental Emergency Medicine, 7(3):197, 2020.
- Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30, 2017.
- The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nature medicine, 24(11):1716–1720, 2018.
- Predictability and stability testing to assess clinical decision instrument performance for children after blunt torso trauma. PLOS Digital Health, 1(8):e0000076, 2022.
- Machine-learning-based electronic triage more accurately differentiates patients with respect to clinical outcomes compared with the emergency severity index. Annals of Emergency Medicine, 71(5):565–574.e2, 2018. ISSN 0196-0644. doi: https://doi.org/10.1016/j.annemergmed.2017.08.005. URL https://www.sciencedirect.com/science/article/pii/S0196064417314427.
- The effect of laboratory testing on emergency department length of stay: a multihospital longitudinal study applying a cross-classified random-effect modeling approach. Academic Emergency Medicine, 22(1):38–46, 2015.
- Biogpt: generative pre-trained transformer for biomedical text generation and mining. Briefings in Bioinformatics, 23(6):bbac409, 2022.
- Language models are weak learners, 2023.
- Factors contributing to inappropriate ordering of tests in an academic medical department and the effect of an educational feedback strategy. Postgraduate medical journal, 82(974):823–829, 2006.
- Benchmarking deep learning models on large healthcare datasets. Journal of Biomedical Informatics, 83:112–134, 2018. ISSN 1532-0464. doi: https://doi.org/10.1016/j.jbi.2018.04.007. URL https://www.sciencedirect.com/science/article/pii/S1532046418300716.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 22(268):1–8, 2021. URL http://jmlr.org/papers/v22/20-1364.html.
- Overcrowding in emergency department: Causes, consequences, and solutions-a narrative review. Healthcare (Basel, Switzerland), 10(9):1625, 2022. doi: 10.3390/healthcare10091625. URL https://doi.org/10.3390/healthcare10091625.
- Emergency department overcrowding: Understanding the factors to find corresponding solutions. Journal of Personalized Medicine, 12(2):279, 2022. doi: 10.3390/jpm12020279. URL https://doi.org/10.3390/jpm12020279.
- Proximal policy optimization algorithms, 2017.
- Towards expert-level medical question answering with large language models, 2023.
- Fast interpretable greedy-tree sums (figs). arXiv preprint arXiv:2201.11931, 2022.
- Mimic-extract: a data extraction, preprocessing, and representation pipeline for mimic-iii. In Proceedings of the ACM Conference on Health, Inference, and Learning, ACM CHIL ’20. ACM, April 2020. doi: 10.1145/3368555.3384469. URL http://dx.doi.org/10.1145/3368555.3384469.
- Predicting progression to septic shock in the emergency department using an externally generalizable machine-learning algorithm. Annals of emergency medicine, 77(4):395–406, 2021.
- Benchmarking emergency department prediction models with machine learning and public electronic health records. Scientific Data, 9(1):658, 2022.
- Medlm: Exploring language models for medical question answering systems, 2024.
- Clinical relation extraction using transformer-based models, 2021.
- A large language model for electronic health records. NPJ Digital Medicine, 5(1):194, 2022. doi: 10.1038/s41746-022-00742-2.
- Deep reinforcement learning for cost-effective medical diagnosis, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

