A Survey on Knowledge Distillation of Large Language Models
Abstract: In the era of LLMs, Knowledge Distillation (KD) emerges as a pivotal methodology for transferring advanced capabilities from leading proprietary LLMs, such as GPT-4, to their open-source counterparts like LLaMA and Mistral. Additionally, as open-source LLMs flourish, KD plays a crucial role in both compressing these models, and facilitating their self-improvement by employing themselves as teachers. This paper presents a comprehensive survey of KD's role within the realm of LLM, highlighting its critical function in imparting advanced knowledge to smaller models and its utility in model compression and self-improvement. Our survey is meticulously structured around three foundational pillars: \textit{algorithm}, \textit{skill}, and \textit{verticalization} -- providing a comprehensive examination of KD mechanisms, the enhancement of specific cognitive abilities, and their practical implications across diverse fields. Crucially, the survey navigates the intricate interplay between data augmentation (DA) and KD, illustrating how DA emerges as a powerful paradigm within the KD framework to bolster LLMs' performance. By leveraging DA to generate context-rich, skill-specific training data, KD transcends traditional boundaries, enabling open-source models to approximate the contextual adeptness, ethical alignment, and deep semantic insights characteristic of their proprietary counterparts. This work aims to provide an insightful guide for researchers and practitioners, offering a detailed overview of current methodologies in KD and proposing future research directions. Importantly, we firmly advocate for compliance with the legal terms that regulate the use of LLMs, ensuring ethical and lawful application of KD of LLMs. An associated Github repository is available at https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs.
- L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022.
- OpenAI, :, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V. Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner, L. Bogdonoff, O. Boiko, M. Boyd, A.-L. Brakman, G. Brockman, T. Brooks, M. Brundage, K. Button, T. Cai, R. Campbell, A. Cann, B. Carey, C. Carlson, R. Carmichael, B. Chan, C. Chang, F. Chantzis, D. Chen, S. Chen, R. Chen, J. Chen, M. Chen, B. Chess, C. Cho, C. Chu, H. W. Chung, D. Cummings, J. Currier, Y. Dai, C. Decareaux, T. Degry, N. Deutsch, D. Deville, A. Dhar, D. Dohan, S. Dowling, S. Dunning, A. Ecoffet, A. Eleti, T. Eloundou, D. Farhi, L. Fedus, N. Felix, S. P. Fishman, J. Forte, I. Fulford, L. Gao, E. Georges, C. Gibson, V. Goel, T. Gogineni, G. Goh, R. Gontijo-Lopes, J. Gordon, M. Grafstein, S. Gray, R. Greene, J. Gross, S. S. Gu, Y. Guo, C. Hallacy, J. Han, J. Harris, Y. He, M. Heaton, J. Heidecke, C. Hesse, A. Hickey, W. Hickey, P. Hoeschele, B. Houghton, K. Hsu, S. Hu, X. Hu, J. Huizinga, S. Jain, S. Jain, J. Jang, A. Jiang, R. Jiang, H. Jin, D. Jin, S. Jomoto, B. Jonn, H. Jun, T. Kaftan, Łukasz Kaiser, A. Kamali, I. Kanitscheider, N. S. Keskar, T. Khan, L. Kilpatrick, J. W. Kim, C. Kim, Y. Kim, H. Kirchner, J. Kiros, M. Knight, D. Kokotajlo, Łukasz Kondraciuk, A. Kondrich, A. Konstantinidis, K. Kosic, G. Krueger, V. Kuo, M. Lampe, I. Lan, T. Lee, J. Leike, J. Leung, D. Levy, C. M. Li, R. Lim, M. Lin, S. Lin, M. Litwin, T. Lopez, R. Lowe, P. Lue, A. Makanju, K. Malfacini, S. Manning, T. Markov, Y. Markovski, B. Martin, K. Mayer, A. Mayne, B. McGrew, S. M. McKinney, C. McLeavey, P. McMillan, J. McNeil, D. Medina, A. Mehta, J. Menick, L. Metz, A. Mishchenko, P. Mishkin, V. Monaco, E. Morikawa, D. Mossing, T. Mu, M. Murati, O. Murk, D. Mély, A. Nair, R. Nakano, R. Nayak, A. Neelakantan, R. Ngo, H. Noh, L. Ouyang, C. O’Keefe, J. Pachocki, A. Paino, J. Palermo, A. Pantuliano, G. Parascandolo, J. Parish, E. Parparita, A. Passos, M. Pavlov, A. Peng, A. Perelman, F. de Avila Belbute Peres, M. Petrov, H. P. de Oliveira Pinto, Michael, Pokorny, M. Pokrass, V. Pong, T. Powell, A. Power, B. Power, E. Proehl, R. Puri, A. Radford, J. Rae, A. Ramesh, C. Raymond, F. Real, K. Rimbach, C. Ross, B. Rotsted, H. Roussez, N. Ryder, M. Saltarelli, T. Sanders, S. Santurkar, G. Sastry, H. Schmidt, D. Schnurr, J. Schulman, D. Selsam, K. Sheppard, T. Sherbakov, J. Shieh, S. Shoker, P. Shyam, S. Sidor, E. Sigler, M. Simens, J. Sitkin, K. Slama, I. Sohl, B. Sokolowsky, Y. Song, N. Staudacher, F. P. Such, N. Summers, I. Sutskever, J. Tang, N. Tezak, M. Thompson, P. Tillet, A. Tootoonchian, E. Tseng, P. Tuggle, N. Turley, J. Tworek, J. F. C. Uribe, A. Vallone, A. Vijayvergiya, C. Voss, C. Wainwright, J. J. Wang, A. Wang, B. Wang, J. Ward, J. Wei, C. Weinmann, A. Welihinda, P. Welinder, J. Weng, L. Weng, M. Wiethoff, D. Willner, C. Winter, S. Wolrich, H. Wong, L. Workman, S. Wu, J. Wu, M. Wu, K. Xiao, T. Xu, S. Yoo, K. Yu, Q. Yuan, W. Zaremba, R. Zellers, C. Zhang, M. Zhang, S. Zhao, T. Zheng, J. Zhuang, W. Zhuk, and B. Zoph, “Gpt-4 technical report,” 2023.
- G. Team, R. Anil, S. Borgeaud, Y. Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth et al., “Gemini: a family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805, 2023.
- J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, E. H. Chi, T. Hashimoto, O. Vinyals, P. Liang, J. Dean, and W. Fedus, “Emergent abilities of large language models,” Trans. Mach. Learn. Res., vol. 2022, 2022. [Online]. Available: https://openreview.net/forum?id=yzkSU5zdwD
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022.
- P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y. Zhang, D. Narayanan, Y. Wu, A. Kumar, B. Newman, B. Yuan, B. Yan, C. Zhang, C. Cosgrove, C. D. Manning, C. Ré, D. Acosta-Navas, D. A. Hudson, E. Zelikman, E. Durmus, F. Ladhak, F. Rong, H. Ren, H. Yao, J. Wang, K. Santhanam, L. J. Orr, L. Zheng, M. Yüksekgönül, M. Suzgun, N. Kim, N. Guha, N. S. Chatterji, O. Khattab, P. Henderson, Q. Huang, R. Chi, S. M. Xie, S. Santurkar, S. Ganguli, T. Hashimoto, T. Icard, T. Zhang, V. Chaudhary, W. Wang, X. Li, Y. Mai, Y. Zhang, and Y. Koreeda, “Holistic evaluation of language models,” CoRR, vol. abs/2211.09110, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2211.09110
- X. Wu, R. Duan, and J. Ni, “Unveiling security, privacy, and ethical concerns of chatgpt,” Journal of Information and Intelligence, 2023.
- H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev, P. S. Koura, M.-A. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan, I. Zarov, Y. Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and T. Scialom, “Llama 2: Open foundation and fine-tuned chat models,” 2023.
- A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023.
- L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging llm-as-a-judge with mt-bench and chatbot arena,” CoRR, vol. abs/2306.05685, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2306.05685
- L. Sun, Y. Huang, H. Wang, S. Wu, Q. Zhang, C. Gao, Y. Huang, W. Lyu, Y. Zhang, X. Li, Z. Liu, Y. Liu, Y. Wang, Z. Zhang, B. Kailkhura, C. Xiong, C. Xiao, C. Li, E. Xing, F. Huang, H. Liu, H. Ji, H. Wang, H. Zhang, H. Yao, M. Kellis, M. Zitnik, M. Jiang, M. Bansal, J. Zou, J. Pei, J. Liu, J. Gao, J. Han, J. Zhao, J. Tang, J. Wang, J. Mitchell, K. Shu, K. Xu, K.-W. Chang, L. He, L. Huang, M. Backes, N. Z. Gong, P. S. Yu, P.-Y. Chen, Q. Gu, R. Xu, R. Ying, S. Ji, S. Jana, T. Chen, T. Liu, T. Zhou, W. Wang, X. Li, X. Zhang, X. Wang, X. Xie, X. Chen, X. Wang, Y. Liu, Y. Ye, Y. Cao, Y. Chen, and Y. Zhao, “Trustllm: Trustworthiness in large language models,” 2024.
- J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, pp. 1789–1819, 2021.
- M. Gupta and P. Agrawal, “Compression of deep learning models for text: A survey,” ACM Transactions on Knowledge Discovery from Data (TKDD), vol. 16, no. 4, pp. 1–55, 2022.
- S. Y. Feng, V. Gangal, J. Wei, S. Chandar, S. Vosoughi, T. Mitamura, and E. Hovy, “A survey of data augmentation approaches for nlp,” arXiv preprint arXiv:2105.03075, 2021.
- R. Taori, I. Gulrajani, T. Zhang, Y. Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Stanford alpaca: An instruction-following llama model,” https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Y. Huang, Y. Chen, Z. Yu, and K. McKeown, “In-context learning distillation: Transferring few-shot learning ability of pre-trained language models,” 2022.
- G. Cui, L. Yuan, N. Ding, G. Yao, W. Zhu, Y. Ni, G. Xie, Z. Liu, and M. Sun, “Ultrafeedback: Boosting language models with high-quality feedback,” arXiv preprint arXiv:2310.01377, 2023.
- S. Mukherjee, A. Mitra, G. Jawahar, S. Agarwal, H. Palangi, and A. Awadallah, “Orca: Progressive learning from complex explanation traces of gpt-4,” arXiv preprint arXiv:2306.02707, 2023.
- C. Hsieh, C. Li, C. Yeh, H. Nakhost, Y. Fujii, A. Ratner, R. Krishna, C. Lee, and T. Pfister, “Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes,” in ACL (Findings). Association for Computational Linguistics, 2023, pp. 8003–8017.
- B. Ding, C. Qin, L. Liu, Y. K. Chia, B. Li, S. Joty, and L. Bing, “Is GPT-3 a good data annotator?” in ACL (1). Association for Computational Linguistics, 2023, pp. 11 173–11 195.
- S. Chaudhary, “Code alpaca: An instruction-following llama model for code generation,” https://github.com/sahil280114/codealpaca, 2023.
- H. Wang, C. Liu, N. Xi, Z. Qiang, S. Zhao, B. Qin, and T. Liu, “Huatuo: Tuning llama model with chinese medical knowledge,” arXiv preprint arXiv:2304.06975, 2023.
- LawGPT. GitHub, 2023.
- D. Zhang, Z. Hu, S. Zhoubian, Z. Du, K. Yang, Z. Wang, Y. Yue, Y. Dong, and J. Tang, “Sciglm: Training scientific language models with self-reflective instruction annotation and tuning,” CoRR, vol. abs/2401.07950, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.07950
- Y. Gu, L. Dong, F. Wei, and M. Huang, “MiniLLM: Knowledge distillation of large language models,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=5h0qf7IBZZ
- W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y. Zhuang, J. E. Gonzalez, I. Stoica, and E. P. Xing, “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,” March 2023. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/
- C. Xu, Q. Sun, K. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, and D. Jiang, “Wizardlm: Empowering large language models to follow complex instructions,” arXiv preprint arXiv:2304.12244, 2023.
- W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, Y. Du, C. Yang, Y. Chen, Z. Chen, J. Jiang, R. Ren, Y. Li, X. Tang, Z. Liu, P. Liu, J.-Y. Nie, and J.-R. Wen, “A survey of large language models,” 2023.
- V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,” arXiv preprint arXiv:1910.01108, 2019.
- Y. Kim and A. M. Rush, “Sequence-level knowledge distillation,” arXiv preprint arXiv:1606.07947, 2016.
- L. Tunstall, E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y. Belkada, S. Huang, L. von Werra, C. Fourrier, N. Habib et al., “Zephyr: Direct distillation of lm alignment,” arXiv preprint arXiv:2310.16944, 2023.
- S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” International Conference on Learning Representations (ICLR), 2016.
- Z. Liu, B. Oguz, C. Zhao, E. Chang, P. Stock, Y. Mehdad, Y. Shi, R. Krishnamoorthi, and V. Chandra, “Llm-qat: Data-free quantization aware training for large language models,” arXiv preprint arXiv:2305.17888, 2023.
- N. Ding, Y. Chen, B. Xu, Y. Qin, S. Hu, Z. Liu, M. Sun, and B. Zhou, “Enhancing chat language models by scaling high-quality instructional conversations,” in EMNLP. Association for Computational Linguistics, 2023, pp. 3029–3051.
- X. He, Z. Lin, Y. Gong, A. Jin, H. Zhang, C. Lin, J. Jiao, S. M. Yiu, N. Duan, W. Chen et al., “Annollm: Making large language models to be better crowdsourced annotators,” arXiv preprint arXiv:2303.16854, 2023.
- S. Qiao, N. Zhang, R. Fang, Y. Luo, W. Zhou, Y. E. Jiang, C. Lv, and H. Chen, “Autoact: Automatic agent learning from scratch via self-planning,” 2024.
- A. Mitra, L. D. Corro, S. Mahajan, A. Codas, C. Simoes, S. Agarwal, X. Chen, A. Razdaibiedina, E. Jones, K. Aggarwal, H. Palangi, G. Zheng, C. Rosset, H. Khanpour, and A. Awadallah, “Orca 2: Teaching small language models how to reason,” 2023.
- Z. Sun, Y. Shen, Q. Zhou, H. Zhang, Z. Chen, D. Cox, Y. Yang, and C. Gan, “Principle-driven self-alignment of language models from scratch with minimal human supervision,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- A. Asai, Z. Wu, Y. Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” arXiv preprint arXiv:2310.11511, 2023.
- Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi, “Self-instruct: Aligning language model with self generated instructions,” arXiv preprint arXiv:2212.10560, 2022.
- J. Ye, J. Gao, Q. Li, H. Xu, J. Feng, Z. Wu, T. Yu, and L. Kong, “Zerogen: Efficient zero-shot learning via dataset generation,” in EMNLP. Association for Computational Linguistics, 2022, pp. 11 653–11 669.
- V. Gangal, S. Y. Feng, M. Alikhani, T. Mitamura, and E. Hovy, “Nareor: The narrative reordering problem,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 10, 2022, pp. 10 645–10 653.
- S. Longpre, Y. Lu, Z. Tu, and C. DuBois, “An exploration of data augmentation and sampling techniques for domain-agnostic question answering,” in Proceedings of the 2nd Workshop on Machine Reading for Question Answering, A. Fisch, A. Talmor, R. Jia, M. Seo, E. Choi, and D. Chen, Eds. Hong Kong, China: Association for Computational Linguistics, Nov. 2019, pp. 220–227. [Online]. Available: https://aclanthology.org/D19-5829
- P. West, C. Bhagavatula, J. Hessel, J. Hwang, L. Jiang, R. Le Bras, X. Lu, S. Welleck, and Y. Choi, “Symbolic knowledge distillation: from general language models to commonsense models,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, M. Carpuat, M.-C. de Marneffe, and I. V. Meza Ruiz, Eds. Seattle, United States: Association for Computational Linguistics, Jul. 2022, pp. 4602–4625. [Online]. Available: https://aclanthology.org/2022.naacl-main.341
- S. Gunasekar, Y. Zhang, J. Aneja, C. C. T. Mendes, A. D. Giorno, S. Gopi, M. Javaheripi, P. Kauffmann, G. de Rosa, O. Saarikivi, A. Salim, S. Shah, H. S. Behl, X. Wang, S. Bubeck, R. Eldan, A. T. Kalai, Y. T. Lee, and Y. Li, “Textbooks are all you need,” 2023.
- R. Agarwal, N. Vieillard, Y. Zhou, P. Stanczyk, S. R. Garea, M. Geist, and O. Bachem, “On-policy distillation of language models: Learning from self-generated mistakes,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=3zKtaqxLhW
- H. Luo, Y.-S. Chuang, Y. Gong, T. Zhang, Y. Kim, X. Wu, D. Fox, H. Meng, and J. Glass, “Sail: Search-augmented instruction learning,” arXiv preprint arXiv:2305.15225, 2023.
- H. Dai, Z. Liu, W. Liao, X. Huang, Y. Cao, Z. Wu, L. Zhao, S. Xu, W. Liu, N. Liu, S. Li, D. Zhu, H. Cai, L. Sun, Q. Li, D. Shen, T. Liu, and X. Li, “Auggpt: Leveraging chatgpt for text data augmentation,” 2023.
- J. Jung, P. West, L. Jiang, F. Brahman, X. Lu, J. Fisher, T. Sorensen, and Y. Choi, “Impossible distillation: from low-quality model to high-quality dataset & model for summarization and paraphrasing,” 2023.
- H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” in NeurIPS, 2023.
- B. Zhao, B. Wu, M. He, and T. Huang, “Svit: Scaling up visual instruction tuning,” 2023.
- X. Zhang and Q. Yang, “Xuanyuan 2.0: A large chinese financial chat model with hundreds of billions parameters,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM 2023, Birmingham, United Kingdom, October 21-25, 2023, I. Frommholz, F. Hopfgartner, M. Lee, M. Oakes, M. Lalmas, M. Zhang, and R. L. T. Santos, Eds. ACM, 2023, pp. 4435–4439. [Online]. Available: https://doi.org/10.1145/3583780.3615285
- Y. Wang, Z. Yu, Z. Zeng, L. Yang, C. Wang, H. Chen, C. Jiang, R. Xie, J. Wang, X. Xie, W. Ye, S. Zhang, and Y. Zhang, “Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization,” 2023.
- C. Xu, D. Guo, N. Duan, and J. J. McAuley, “Baize: An open-source chat model with parameter-efficient tuning on self-chat data,” in EMNLP. Association for Computational Linguistics, 2023, pp. 6268–6278.
- X. Yue, X. Qu, G. Zhang, Y. Fu, W. Huang, H. Sun, Y. Su, and W. Chen, “Mammoth: Building math generalist models through hybrid instruction tuning,” arXiv preprint arXiv:2309.05653, 2023.
- L. Chenglin, C. Qianglong, W. Caiyu, and Z. Yin, “Mixed distillation helps smaller language model better reasoning,” 2023.
- Z. Luo, C. Xu, P. Zhao, Q. Sun, X. Geng, W. Hu, C. Tao, J. Ma, Q. Lin, and D. Jiang, “Wizardcoder: Empowering code large language models with evol-instruct,” arXiv preprint arXiv:2306.08568, 2023.
- H. Luo, Q. Sun, C. Xu, P. Zhao, J. Lou, C. Tao, X. Geng, Q. Lin, S. Chen, and D. Zhang, “Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct,” arXiv preprint arXiv:2308.09583, 2023.
- Z. He, M. T. Ribeiro, and F. Khani, “Targeted data generation: Finding and fixing model weaknesses,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 8506–8520. [Online]. Available: https://aclanthology.org/2023.acl-long.474
- Y. Li, S. Bubeck, R. Eldan, A. Del Giorno, S. Gunasekar, and Y. T. Lee, “Textbooks are all you need ii: phi-1.5 technical report,” arXiv preprint arXiv:2309.05463, 2023.
- Phi-2: The surprising power of small language models, December 2023. [Online]. Available: https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
- Y. Wei, Z. Wang, J. Liu, Y. Ding, and L. Zhang, “Magicoder: Source code is all you need,” 2023.
- Z. Yu, X. Zhang, N. Shang, Y. Huang, C. Xu, Y. Zhao, W. Hu, and Q. Yin, “Wavecoder: Widespread and versatile enhanced instruction tuning with refined data generation,” 2024.
- J. Gao, R. Pi, Y. Lin, H. Xu, J. Ye, Z. Wu, W. Zhang, X. Liang, Z. Li, and L. Kong, “Self-guided noise-free data generation for efficient zero-shot learning,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, 2023. [Online]. Available: https://openreview.net/pdf?id=h5OpjGd_lo6
- L. H. Bonifacio, H. Q. Abonizio, M. Fadaee, and R. F. Nogueira, “Inpars: Data augmentation for information retrieval using large language models,” CoRR, vol. abs/2202.05144, 2022. [Online]. Available: https://arxiv.org/abs/2202.05144
- I. Timiryasov and J.-L. Tastet, “Baby llama: knowledge distillation from an ensemble of teachers trained on a small dataset with no performance penalty,” in Proceedings of the BabyLM Challenge at the 27th Conference on Computational Natural Language Learning, A. Warstadt, A. Mueller, L. Choshen, E. Wilcox, C. Zhuang, J. Ciro, R. Mosquera, B. Paranjabe, A. Williams, T. Linzen, and R. Cotterell, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 279–289. [Online]. Available: https://aclanthology.org/2023.conll-babylm.24
- C. Tao, L. Hou, W. Zhang, L. Shang, X. Jiang, Q. Liu, P. Luo, and N. Wong, “Compression of generative pre-trained language models via quantization,” arXiv preprint arXiv:2203.10705, 2022.
- Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, C. Chen, C. Olsson, C. Olah, D. Hernandez, D. Drain, D. Ganguli, D. Li, E. Tran-Johnson, E. Perez, J. Kerr, J. Mueller, J. Ladish, J. Landau, K. Ndousse, K. Lukosuite, L. Lovitt, M. Sellitto, N. Elhage, N. Schiefer, N. Mercado, N. DasSarma, R. Lasenby, R. Larson, S. Ringer, S. Johnston, S. Kravec, S. E. Showk, S. Fort, T. Lanham, T. Telleen-Lawton, T. Conerly, T. Henighan, T. Hume, S. R. Bowman, Z. Hatfield-Dodds, B. Mann, D. Amodei, N. Joseph, S. McCandlish, T. Brown, and J. Kaplan, “Constitutional ai: Harmlessness from ai feedback,” 2022.
- J. Hong, Q. Tu, C. Chen, X. Gao, J. Zhang, and R. Yan, “Cyclealign: Iterative distillation from black-box llm to white-box models for better human alignment,” arXiv preprint arXiv:2310.16271, 2023.
- H. Lee, S. Phatale, H. Mansoor, K. Lu, T. Mesnard, C. Bishop, V. Carbune, and A. Rastogi, “Rlaif: Scaling reinforcement learning from human feedback with ai feedback,” arXiv preprint arXiv:2309.00267, 2023.
- Y. Jiang, C. Chan, M. Chen, and W. Wang, “Lion: Adversarial distillation of closed-source large language model,” arXiv preprint arXiv:2305.12870, 2023.
- H. Chen, A. Saha, S. Hoi, and S. Joty, “Personalized distillation: Empowering open-sourced LLMs with adaptive learning for code generation,” in The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. [Online]. Available: https://openreview.net/forum?id=alxWMBcNVN
- K. Yang, D. Klein, A. Celikyilmaz, N. Peng, and Y. Tian, “RLCD: Reinforcement learning from contrastive distillation for LM alignment,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=v3XXtxWKi6
- J. Huang, S. Gu, L. Hou, Y. Wu, X. Wang, H. Yu, and J. Han, “Large language models can self-improve,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 1051–1068. [Online]. Available: https://aclanthology.org/2023.emnlp-main.67
- C. Gulcehre, T. L. Paine, S. Srinivasan, K. Konyushkova, L. Weerts, A. Sharma, A. Siddhant, A. Ahern, M. Wang, C. Gu, W. Macherey, A. Doucet, O. Firat, and N. de Freitas, “Reinforced self-training (rest) for language modeling,” 2023.
- W. Yuan, R. Y. Pang, K. Cho, S. Sukhbaatar, J. Xu, and J. Weston, “Self-rewarding language models,” 2024.
- E. Zelikman, Y. Wu, J. Mu, and N. D. Goodman, “Star: Bootstrapping reasoning with reasoning,” in NeurIPS, 2022.
- Y. Wen, Z. Li, W. Du, and L. Mou, “f-divergence minimization for sequence-level knowledge distillation,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 10 817–10 834. [Online]. Available: https://aclanthology.org/2023.acl-long.605
- C. Liang, S. Zuo, Q. Zhang, P. He, W. Chen, and T. Zhao, “Less is more: Task-aware layer-wise distillation for language model compression,” in International Conference on Machine Learning. PMLR, 2023, pp. 20 852–20 867.
- M. Kwon, S. M. Xie, K. Bullard, and D. Sadigh, “Reward design with language models,” in ICLR. OpenReview.net, 2023.
- B. Peng, C. Li, P. He, M. Galley, and J. Gao, “Instruction tuning with gpt-4,” 2023.
- G. Li, H. A. A. K. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “Camel: Communicative agents for” mind” exploration of large scale language model society,” arXiv preprint arXiv:2303.17760, 2023.
- G. Wang, S. Cheng, X. Zhan, X. Li, S. Song, and Y. Liu, “OpenChat: Advancing Open-source Language Models with Mixed-Quality Data,” Sep. 2023, arXiv:2309.11235 [cs]. [Online]. Available: http://arxiv.org/abs/2309.11235
- M. Kang, S. Lee, J. Baek, K. Kawaguchi, and S. J. Hwang, “Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks,” arXiv preprint arXiv:2305.18395, 2023.
- S. Ye, Y. Jo, D. Kim, S. Kim, H. Hwang, and M. Seo, “Selfee: Iterative self-revising llm empowered by self-feedback generation,” Blog post, May 2023. [Online]. Available: https://kaistai.github.io/SelFee/
- P. Wang, L. Li, L. Chen, F. Song, B. Lin, Y. Cao, T. Liu, and Z. Sui, “Making large language models better reasoners with alignment,” 2023.
- D. Cheng, S. Huang, and F. Wei, “Adapting large language models via reading comprehension,” 2023.
- Y. Zhang, Z. Chen, Y. Fang, L. Cheng, Y. Lu, F. Li, W. Zhang, and H. Chen, “Knowledgeable preference alignment for llms in domain-specific question answering,” 2023.
- J. Scheurer, J. A. Campos, T. Korbak, J. S. Chan, A. Chen, K. Cho, and E. Perez, “Training language models with language feedback at scale,” 2023.
- S. Kim, S. Bae, J. Shin, S. Kang, D. Kwak, K. Yoo, and M. Seo, “Aligning large language models through synthetic feedback,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 13 677–13 700. [Online]. Available: https://aclanthology.org/2023.emnlp-main.844
- P. Roit, J. Ferret, L. Shani, R. Aharoni, G. Cideron, R. Dadashi, M. Geist, S. Girgin, L. Hussenot, O. Keller, N. Momchev, S. Ramos Garea, P. Stanczyk, N. Vieillard, O. Bachem, G. Elidan, A. Hassidim, O. Pietquin, and I. Szpektor, “Factually consistent summarization via reinforcement learning with textual entailment feedback,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 6252–6272. [Online]. Available: https://aclanthology.org/2023.acl-long.344
- Y. Yang, E. Chern, X. Qiu, G. Neubig, and P. Liu, “Alignment for honesty,” arXiv preprint arXiv:2312.07000, 2023.
- R. Liu, R. Yang, C. Jia, G. Zhang, D. Zhou, A. M. Dai, D. Yang, and S. Vosoughi, “Training socially aligned language models on simulated social interactions,” 2023.
- T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” 2023.
- J. Zhang, “Graph-toolformer: To empower llms with graph reasoning ability via prompt augmented by chatgpt,” arXiv preprint arXiv:2304.11116, 2023.
- S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,” 2023.
- Q. Tang, Z. Deng, H. Lin, X. Han, Q. Liang, B. Cao, and L. Sun, “Toolalpaca: Generalized tool learning for language models with 3000 simulated cases,” 2023.
- Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian, S. Zhao, L. Hong, R. Tian, R. Xie, J. Zhou, M. Gerstein, D. Li, Z. Liu, and M. Sun, “Toolllm: Facilitating large language models to master 16000+ real-world apis,” 2023.
- L. Yuan, Y. Chen, X. Wang, Y. R. Fung, H. Peng, and H. Ji, “Craft: Customizing llms by creating and retrieving from specialized toolsets,” 2023.
- S. Gao, Z. Shi, M. Zhu, B. Fang, X. Xin, P. Ren, Z. Chen, J. Ma, and Z. Ren, “Confucius: Iterative tool learning from introspection feedback by easy-to-difficult curriculum,” 2023.
- C. Wang, W. Luo, Q. Chen, H. Mai, J. Guo, S. Dong, Xiaohua, Xuan, Z. Li, L. Ma, and S. Gao, “Mllm-tool: A multimodal large language model for tool agent learning,” 2024.
- W. Shen, C. Li, H. Chen, M. Yan, X. Quan, H. Chen, J. Zhang, and F. Huang, “Small llms are weak tool learners: A multi-llm agent,” 2024.
- B. Chen, C. Shu, E. Shareghi, N. Collier, K. Narasimhan, and S. Yao, “Fireact: Toward language agent fine-tuning,” 2023.
- A. Zeng, M. Liu, R. Lu, B. Wang, X. Liu, Y. Dong, and J. Tang, “Agenttuning: Enabling generalized agent abilities for llms,” 2023.
- D. Yin, F. Brahman, A. Ravichander, K. Chandu, K.-W. Chang, Y. Choi, and B. Y. Lin, “Lumos: Learning agents with unified data, modular design, and open-source llms,” 2023.
- Y. Kong, J. Ruan, Y. Chen, B. Zhang, T. Bao, S. Shi, G. Du, X. Hu, H. Mao, Z. Li, X. Zeng, and R. Zhao, “Tptu-v2: Boosting task planning and tool usage of large language model-based agents in real-world systems,” 2023.
- F. Gilardi, M. Alizadeh, and M. Kubli, “Chatgpt outperforms crowd workers for text-annotation tasks,” Proceedings of the National Academy of Sciences, vol. 120, no. 30, Jul. 2023. [Online]. Available: http://dx.doi.org/10.1073/pnas.2305016120
- Z. Wang, A. W. Yu, O. Firat, and Y. Cao, “Towards zero-label language learning,” 2021.
- Y. Xu, R. Xu, D. Iter, Y. Liu, S. Wang, C. Zhu, and M. Zeng, “InheritSumm: A general, versatile and compact summarizer by distilling from GPT,” in Findings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 13 879–13 892. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.927
- F. Xu, W. Shi, and E. Choi, “RECOMP: Improving retrieval-augmented LMs with context compression and selective augmentation,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=mlJLVigNHp
- S. Ramnath, B. Joshi, S. Hallinan, X. Lu, L. H. Li, A. Chan, J. Hessel, Y. Choi, and X. Ren, “Tailoring self-rationalizers with multi-reward distillation,” 2023.
- S. Wang, Y. Liu, Y. Xu, C. Zhu, and M. Zeng, “Want to reduce labeling cost? GPT-3 can help,” in Findings of the Association for Computational Linguistics: EMNLP 2021, M.-F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, Eds. Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021, pp. 4195–4205. [Online]. Available: https://aclanthology.org/2021.findings-emnlp.354
- Z. Guo, P. Wang, Y. Wang, and S. Yu, “Improving small language models on pubmedqa via generative data augmentation,” 2023.
- W. Yang and G. Nicolai, “Neural machine translation data generation and augmentation using chatgpt,” 2023.
- K. Srinivasan, K. Raman, A. Samanta, L. Liao, L. Bertelli, and M. Bendersky, “QUILL: Query intent with large language models using retrieval augmentation and multi-stage distillation,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, Y. Li and A. Lazaridou, Eds. Abu Dhabi, UAE: Association for Computational Linguistics, Dec. 2022, pp. 492–501. [Online]. Available: https://aclanthology.org/2022.emnlp-industry.50
- Z. Dai, V. Y. Zhao, J. Ma, Y. Luan, J. Ni, J. Lu, A. Bakalov, K. Guu, K. B. Hall, and M. Chang, “Promptagator: Few-shot dense retrieval from 8 examples,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, 2023. [Online]. Available: https://openreview.net/pdf?id=gmL46YMpu2J
- R. Meng, Y. Liu, S. Yavuz, D. Agarwal, L. Tu, N. Yu, J. Zhang, M. Bhat, and Y. Zhou, “Augtriever: Unsupervised dense retrieval by scalable data augamentation,” 2023.
- W. Sun, L. Yan, X. Ma, S. Wang, P. Ren, Z. Chen, D. Yin, and Z. Ren, “Is chatgpt good at search? investigating large language models as re-ranking agents,” 2023.
- R. Pradeep, S. Sharifymoghaddam, and J. Lin, “Rankvicuna: Zero-shot listwise document reranking with open-source large language models,” 2023.
- ——, “Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze!” 2023.
- F. Ferraretto, T. Laitz, R. Lotufo, and R. Nogueira, “Exaranker: Synthetic explanations improve neural rankers,” in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 2409–2414. [Online]. Available: https://doi.org/10.1145/3539618.3592067
- S. Mysore, A. Mccallum, and H. Zamani, “Large language model augmented narrative driven recommendations,” in Proceedings of the 17th ACM Conference on Recommender Systems, ser. RecSys ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 777–783. [Online]. Available: https://doi.org/10.1145/3604915.3608829
- J. Zhang, R. Xie, Y. Hou, W. X. Zhao, L. Lin, and J.-R. Wen, “Recommendation as instruction following: A large language model empowered recommendation approach,” 2023.
- Q. Liu, N. Chen, T. Sakai, and X.-M. Wu, “Once: Boosting content-based recommendation with both open- and closed-source large language models,” 2023.
- S. Kim, J. Shin, Y. Cho, J. Jang, S. Longpre, H. Lee, S. Yun, S. Shin, S. Kim, J. Thorne, and M. Seo, “Prometheus: Inducing evaluation capability in language models,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=8euJaTveKw
- W. Xu, D. Wang, L. Pan, Z. Song, M. Freitag, W. Wang, and L. Li, “INSTRUCTSCORE: Towards explainable text generation evaluation with automatic feedback,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 5967–5994. [Online]. Available: https://aclanthology.org/2023.emnlp-main.365
- D. Jiang, Y. Li, G. Zhang, W. Huang, B. Y. Lin, and W. Chen, “Tigerscore: Towards building explainable metric for all text generation tasks,” 2023.
- J. Li, S. Sun, W. Yuan, R.-Z. Fan, hai zhao, and P. Liu, “Generative judge for evaluating alignment,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=gtkFw6sZGS
- B. Rozière, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, T. Remez, J. Rapin, A. Kozhevnikov, I. Evtimov, J. Bitton, M. Bhatt, C. C. Ferrer, A. Grattafiori, W. Xiong, A. Défossez, J. Copet, F. Azhar, H. Touvron, L. Martin, N. Usunier, T. Scialom, and G. Synnaeve, “Code llama: Open foundation models for code,” 2023.
- B. Liu, C. Chen, C. Liao, Z. Gong, H. Wang, Z. Lei, M. Liang, D. Chen, M. Shen, H. Zhou, H. Yu, and J. Li, “Mftcoder: Boosting code llms with multitask fine-tuning,” 2023.
- N. Jain, T. Zhang, W. Chiang, J. E. Gonzalez, K. Sen, and I. Stoica, “Llm-assisted code cleaning for training accurate code generators,” CoRR, vol. abs/2311.14904, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.14904
- J. Wang, L. Meng, Z. Weng, B. He, Z. Wu, and Y.-G. Jiang, “To see is to believe: Prompting gpt-4v for better visual instruction tuning,” 2023.
- K. Chen, Z. Zhang, W. Zeng, R. Zhang, F. Zhu, and R. Zhao, “Shikra: Unleashing multimodal llm’s referential dialogue magic,” 2023.
- J. S. Park, J. Hessel, K. R. Chandu, P. P. Liang, X. Lu, P. West, Y. Yu, Q. Huang, J. Gao, A. Farhadi, and Y. Choi, “Localized symbolic knowledge distillation for visual commonsense models,” 2023.
- R. Pi, J. Gao, S. Diao, R. Pan, H. Dong, J. Zhang, L. Yao, J. Han, H. Xu, L. Kong, and T. Zhang, “DetGPT: Detect what you need via reasoning,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 14 172–14 189. [Online]. Available: https://aclanthology.org/2023.emnlp-main.876
- L. Zhao, E. Yu, Z. Ge, J. Yang, H. Wei, H. Zhou, J. Sun, Y. Peng, R. Dong, C. Han, and X. Zhang, “Chatspot: Bootstrapping multimodal llms via precise referring instruction tuning,” 2023.
- F. Liu, K. Lin, L. Li, J. Wang, Y. Yacoob, and L. Wang, “Mitigating hallucination in large multi-modal models via robust instruction tuning,” 2023.
- S. Wu, H. Fei, L. Qu, W. Ji, and T.-S. Chua, “Next-gpt: Any-to-any multimodal llm,” 2023.
- R. Luo, Z. Zhao, M. Yang, J. Dong, D. Li, P. Lu, T. Wang, L. Hu, M. Qiu, and Z. Wei, “Valley: Video assistant with large language model enhanced ability,” 2023.
- Y. Jiang, E. Schoop, A. Swearngin, and J. Nichols, “Iluvui: Instruction-tuned language-vision modeling of uis from machine conversations,” 2023.
- Y. Li, C. Zhang, G. Yu, Z. Wang, B. Fu, G. Lin, C. Shen, L. Chen, and Y. Wei, “Stablellava: Enhanced visual instruction tuning with synthesized image-dialogue data,” 2023.
- R. Xu, X. Wang, T. Wang, Y. Chen, J. Pang, and D. Lin, “Pointllm: Empowering large language models to understand point clouds,” 2023.
- Q. Huang, M. Tao, Z. An, C. Zhang, C. Jiang, Z. Chen, Z. Wu, and Y. Feng, “Lawyer llama technical report,” arXiv preprint arXiv:2305.15062, 2023.
- J. Cui, Z. Li, Y. Yan, B. Chen, and L. Yuan, “Chatlaw: Open-source legal large language model with integrated external knowledge bases,” arXiv preprint arXiv:2306.16092, 2023.
- H. Zhang, J. Chen, F. Jiang, F. Yu, Z. Chen, G. Chen, J. Li, X. Wu, Z. Zhiyi, Q. Xiao, X. Wan, B. Wang, and H. Li, “HuatuoGPT, towards taming language model to be a doctor,” in Findings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 10 859–10 885. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.725
- J. Chen, X. Wang, A. Gao, F. Jiang, S. Chen, H. Zhang, D. Song, W. Xie, C. Kong, J. Li, X. Wan, H. Li, and B. Wang, “Huatuogpt-ii, one-stage training for medical adaption of llms,” CoRR, vol. abs/2311.09774, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.09774
- T. Xie, Y. Wan, W. Huang, Z. Yin, Y. Liu, S. Wang, Q. Linghu, C. Kit, C. Grazian, W. Zhang, I. Razzak, and B. Hoex, “DARWIN series: Domain specific large language models for natural science,” CoRR, vol. abs/2308.13565, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.13565
- Y. Dan, Z. Lei, Y. Gu, Y. Li, J. Yin, J. Lin, L. Ye, Z. Tie, Y. Zhou, Y. Wang, A. Zhou, Z. Zhou, Q. Chen, J. Zhou, L. He, and X. Qiu, “Educhat: A large-scale language model-based chatbot system for intelligent education,” CoRR, vol. abs/2308.02773, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.02773
- H. Guo, J. Yang, J. Liu, L. Yang, L. Chai, J. Bai, J. Peng, X. Hu, C. Chen, D. Zhang, X. Shi, T. Zheng, L. Zheng, B. Zhang, K. Xu, and Z. Li, “OWL: A large language model for IT operations,” CoRR, vol. abs/2309.09298, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.09298
- Z. Li, X. Xu, T. Shen, C. Xu, J.-C. Gu, and C. Tao, “Leveraging large language models for nlg evaluation: A survey,” 2024.
- S. Li, J. Chen, Y. Shen, Z. Chen, X. Zhang, Z. Li, H. Wang, J. Qian, B. Peng, Y. Mao, W. Chen, and X. Yan, “Explanations from large language models make small reasoners better,” 2022.
- N. Ho, L. Schmid, and S. Yun, “Large language models are reasoning teachers,” in ACL (1). Association for Computational Linguistics, 2023, pp. 14 852–14 882.
- L. C. Magister, J. Mallinson, J. Adamek, E. Malmi, and A. Severyn, “Teaching small language models to reason,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 1773–1781. [Online]. Available: https://aclanthology.org/2023.acl-short.151
- Y. Fu, H. Peng, L. Ou, A. Sabharwal, and T. Khot, “Specializing smaller language models towards multi-step reasoning,” 2023.
- L. H. Li, J. Hessel, Y. Yu, X. Ren, K.-W. Chang, and Y. Choi, “Symbolic chain-of-thought distillation: Small models can also “think” step-by-step,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 2665–2679. [Online]. Available: https://aclanthology.org/2023.acl-long.150
- W. Liu, G. Li, K. Zhang, B. Du, Q. Chen, X. Hu, H. Xu, J. Chen, and J. Wu, “Mind’s mirror: Distilling self-evaluation capability and comprehensive thinking from large language models,” 2023.
- S. Longpre, L. Hou, T. Vu, A. Webson, H. W. Chung, Y. Tay, D. Zhou, Q. V. Le, B. Zoph, J. Wei et al., “The flan collection: Designing data and methods for effective instruction tuning,” arXiv preprint arXiv:2301.13688, 2023.
- Y. Anand, Z. Nussbaum, B. Duderstadt, B. Schmidt, and A. Mulyar, “Gpt4all: Training an assistant-style chatbot with large scale data distillation from gpt-3.5-turbo,” GitHub, 2023.
- Q. Si, T. Wang, Z. Lin, X. Zhang, Y. Cao, and W. Wang, “An empirical study of instruction-tuning large language models in chinese,” in EMNLP (Findings). Association for Computational Linguistics, 2023, pp. 4086–4107.
- Y. Ji, Y. Deng, Y. Gong, Y. Peng, Q. Niu, L. Zhang, B. Ma, and X. Li, “Exploring the impact of instruction data scaling on large language models: An empirical study on real-world use cases,” 2023.
- M. Wu, A. Waheed, C. Zhang, M. Abdul-Mageed, and A. F. Aji, “Lamini-lm: A diverse herd of distilled models from large-scale instructions,” 2023.
- W. Guo, J. Yang, K. Yang, X. Li, Z. Rao, Y. Xu, and D. Niu, “Instruction fusion: Advancing prompt evolution through hybridization,” 2023.
- Y. Yu, Y. Zhuang, J. Zhang, Y. Meng, A. Ratner, R. Krishna, J. Shen, and C. Zhang, “Large language model as attributed training data generator: A tale of diversity and bias,” 2023.
- F. Wan, X. Huang, D. Cai, X. Quan, W. Bi, and S. Shi, “Knowledge fusion of large language models,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=jiDsk12qcz
- Q. Zhao and B. Zhu, “Towards the fundamental limits of knowledge transfer over finite domains,” in NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning, 2023. [Online]. Available: https://openreview.net/forum?id=9qxoXqxa0N
- C. Qin, W. Xia, F. Jiao, and S. Joty, “Improving in-context learning via bidirectional alignment,” 2023.
- M. Kim, S. Lee, J. Lee, S. Hong, D.-S. Chang, W. Sung, and J. Choi, “Token-scaled logit distillation for ternary weight generative language models,” arXiv preprint arXiv:2308.06744, 2023.
- Z. Chen, K. Zhou, W. X. Zhao, J. Wan, F. Zhang, D. Zhang, and J.-R. Wen, “Improving large language models via fine-grained reinforcement learning with minimum editing constraint,” 2024.
- G. Guo, R. Zhao, T. Tang, X. Zhao, and J.-R. Wen, “Beyond imitation: Leveraging fine-grained quality signals for alignment,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=LNLjU5C5dK
- Z. Allen-Zhu and Y. Li, “Towards understanding ensemble, knowledge distillation and self-distillation in deep learning,” arXiv preprint arXiv:2012.09816, 2020.
- Z. Chen, Y. Deng, H. Yuan, K. Ji, and Q. Gu, “Self-play fine-tuning converts weak language models to strong language models,” 2024.
- T. Zheng, S. Guo, X. Qu, J. Guo, W. Zhang, X. Du, C. Lin, W. Huang, W. Chen, J. Fu et al., “Kun: Answer polishment for chinese self-alignment with instruction back-translation,” arXiv preprint arXiv:2401.06477, 2024.
- X. Li, P. Yu, C. Zhou, T. Schick, O. Levy, L. Zettlemoyer, J. E. Weston, and M. Lewis, “Self-alignment with instruction backtranslation,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=1oijHJBRsT
- B. Zhao, H. Hajishirzi, and Q. Cao, “Apt: Adaptive pruning and tuning pretrained language models for efficient training and inference,” arXiv preprint arXiv:2401.12200, 2024.
- A. Singh, J. D. Co-Reyes, R. Agarwal, A. Anand, P. Patil, P. J. Liu, J. Harrison, J. Lee, K. Xu, A. Parisi et al., “Beyond human data: Scaling self-training for problem-solving with language models,” arXiv preprint arXiv:2312.06585, 2023.
- W. Chen, D. Song, and B. Li, “Grath: Gradual self-truthifying for large language models,” 2024.
- A. Hosseini, X. Yuan, N. Malkin, A. Courville, A. Sordoni, and R. Agarwal, “V-star: Training verifiers for self-taught reasoners,” 2024.
- A. Askell, Y. Bai, A. Chen, D. Drain, D. Ganguli, T. Henighan, A. Jones, N. Joseph, B. Mann, N. DasSarma, N. Elhage, Z. Hatfield-Dodds, D. Hernandez, J. Kernion, K. Ndousse, C. Olsson, D. Amodei, T. Brown, J. Clark, S. McCandlish, C. Olah, and J. Kaplan, “A general language assistant as a laboratory for alignment,” 2021.
- H. Chen, X. Quan, H. Chen, M. Yan, and J. Zhang, “Knowledge distillation for closed-source language models,” arXiv preprint arXiv:2401.07013, 2024.
- I. Sason and S. Verdú, “f𝑓fitalic_f -divergence inequalities,” IEEE Transactions on Information Theory, vol. 62, no. 11, pp. 5973–6006, 2016.
- S. Sun, Y. Cheng, Z. Gan, and J. Liu, “Patient knowledge distillation for bert model compression,” 2019.
- Z. Sun, H. Yu, X. Song, R. Liu, Y. Yang, and D. Zhou, “MobileBERT: a compact task-agnostic BERT for resource-limited devices,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 2158–2170. [Online]. Available: https://aclanthology.org/2020.acl-main.195
- X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu, “TinyBERT: Distilling BERT for natural language understanding,” in Findings of the Association for Computational Linguistics: EMNLP 2020, T. Cohn, Y. He, and Y. Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 4163–4174. [Online]. Available: https://aclanthology.org/2020.findings-emnlp.372
- L. Hou, Z. Huang, L. Shang, X. Jiang, X. Chen, and Q. Liu, “Dynabert: Dynamic bert with adaptive width and depth,” Advances in Neural Information Processing Systems, vol. 33, pp. 9782–9793, 2020.
- S. Zuo, Q. Zhang, C. Liang, P. He, T. Zhao, and W. Chen, “Moebert: from bert to mixture-of-experts via importance-guided adaptation,” arXiv preprint arXiv:2204.07675, 2022.
- K. J. Liang, W. Hao, D. Shen, Y. Zhou, W. Chen, C. Chen, and L. Carin, “Mixkd: Towards efficient distillation of large-scale language models,” in 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. [Online]. Available: https://openreview.net/forum?id=UFGEelJkLu5
- Y. J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y. Zhu, L. Fan, and A. Anandkumar, “Eureka: Human-level reward design via coding large language models,” 2023.
- J.-C. Pang, P. Wang, K. Li, X.-H. Chen, J. Xu, Z. Zhang, and Y. Yu, “Language model self-improvement by reinforcement learning contemplation,” 2023.
- Y. Du, O. Watkins, Z. Wang, C. Colas, T. Darrell, P. Abbeel, A. Gupta, and J. Andreas, “Guiding pretraining in reinforcement learning with large language models,” in Proceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–29 Jul 2023, pp. 8657–8677. [Online]. Available: https://proceedings.mlr.press/v202/du23f.html
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017.
- R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” 2023.
- F. Song, B. Yu, M. Li, H. Yu, F. Huang, Y. Li, and H. Wang, “Preference ranking optimization for human alignment,” arXiv preprint arXiv:2306.17492, 2023.
- Z. Yuan, H. Yuan, C. Tan, W. Wang, S. Huang, and F. Huang, “Rrhf: Rank responses to align language models with human feedback without tears,” arXiv preprint arXiv:2304.05302, 2023.
- M. Li, L. Chen, J. Chen, S. He, and T. Zhou, “Reflection-tuning: Recycling data for better instruction-tuning,” in NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023. [Online]. Available: https://openreview.net/forum?id=xaqoZZqkPU
- M. Li, L. Chen, J. Chen, S. He, J. Gu, and T. Zhou, “Selective reflection-tuning: Student-selected data recycling for llm instruction-tuning,” 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:267682220
- X. Geng, A. Gudibande, H. Liu, E. Wallace, P. Abbeel, S. Levine, and D. Song, “Koala: A dialogue model for academic research,” Blog post, April 2023. [Online]. Available: https://bair.berkeley.edu/blog/2023/04/03/koala/
- M. Li, J. Chen, L. Chen, and T. Zhou, “Can llms speak for diverse people? tuning llms via debate to generate controllable controversial statements,” 2024.
- M. Kang, S. Lee, J. Baek, K. Kawaguchi, and S. J. Hwang, “Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks,” 2023.
- R. Yang, L. Song, Y. Li, S. Zhao, Y. Ge, X. Li, and Y. Shan, “Gpt4tools: Teaching large language model to use tools via self-instruction,” 2023.
- A. Yehudai, B. Carmeli, Y. Mass, O. Arviv, N. Mills, A. Toledo, E. Shnarch, and L. Choshen, “Genie: Achieving human parity in content-grounded datasets generation,” 2024.
- Y. Zhang, R. Zhang, J. Gu, Y. Zhou, N. Lipka, D. Yang, and T. Sun, “Llavar: Enhanced visual instruction tuning for text-rich image understanding,” 2023.
- C. Lyu, M. Wu, L. Wang, X. Huang, B. Liu, Z. Du, S. Shi, and Z. Tu, “Macaw-llm: Multi-modal language modeling with image, audio, video, and text integration,” arXiv preprint arXiv:2306.09093, 2023.
- B. Li, Y. Zhang, L. Chen, J. Wang, F. Pu, J. Yang, C. Li, and Z. Liu, “Mimic-it: Multi-modal in-context instruction tuning,” 2023.
- Z. Zhao, L. Guo, T. Yue, S. Chen, S. Shao, X. Zhu, Z. Yuan, and J. Liu, “Chatbridge: Bridging modalities with large language model as a language catalyst,” 2023.
- Y. Zhao, B. Yu, B. Hui, H. Yu, F. Huang, Y. Li, and N. L. Zhang, “A preliminary study of the intrinsic relationship between complexity and alignment,” 2023.
- A. Gudibande, E. Wallace, C. Snell, X. Geng, H. Liu, P. Abbeel, S. Levine, and D. Song, “The false promise of imitating proprietary llms,” arXiv preprint arXiv:2305.15717, 2023.
- C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu, L. YU, S. Zhang, G. Ghosh, M. Lewis, L. Zettlemoyer, and O. Levy, “LIMA: Less is more for alignment,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023. [Online]. Available: https://openreview.net/forum?id=KBMOKmX2he
- M. Li, Y. Zhang, S. He, Z. Li, H. Zhao, J. Wang, N. Cheng, and T. Zhou, “Superfiltering: Weak-to-strong data filtering for fast instruction-tuning,” 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:267365346
- B. Xu, A. Yang, J. Lin, Q. Wang, C. Zhou, Y. Zhang, and Z. Mao, “Expertprompting: Instructing large language models to be distinguished experts,” 2023.
- W. Liu, W. Zeng, K. He, Y. Jiang, and J. He, “What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning,” 2023.
- R. Lou, K. Zhang, J. Xie, Y. Sun, J. Ahn, H. Xu, Y. Su, and W. Yin, “Muffin: Curating multi-faceted instructions for improving instruction-following,” 2023.
- T. Schick, J. Dwivedi-Yu, Z. Jiang, F. Petroni, P. Lewis, G. Izacard, Q. You, C. Nalmpantis, E. Grave, and S. Riedel, “Peer: A collaborative language model,” 2022.
- A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark, “Self-refine: Iterative refinement with self-feedback,” 2023.
- W. Saunders, C. Yeh, J. Wu, S. Bills, L. Ouyang, J. Ward, and J. Leike, “Self-critiquing models for assisting human evaluators,” 2022.
- D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving, “Fine-tuning language models from human preferences,” arXiv preprint arXiv:1909.08593, 2019.
- N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,” Advances in Neural Information Processing Systems, vol. 33, pp. 3008–3021, 2020.
- J. Wu, L. Ouyang, D. M. Ziegler, N. Stiennon, R. Lowe, J. Leike, and P. Christiano, “Recursively summarizing books with human feedback,” 2021.
- Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan et al., “Training a helpful and harmless assistant with reinforcement learning from human feedback,” arXiv preprint arXiv:2204.05862, 2022.
- A. Köpf, Y. Kilcher, D. von Rütte, S. Anagnostidis, Z.-R. Tam, K. Stevens, A. Barhoum, N. M. Duc, O. Stanley, R. Nagyfi, S. ES, S. Suri, D. Glushkov, A. Dantuluri, A. Maguire, C. Schuhmann, H. Nguyen, and A. Mattick, “Openassistant conversations – democratizing large language model alignment,” 2023.
- G. Wang, S. Cheng, X. Zhan, X. Li, S. Song, and Y. Liu, “Openchat: Advancing open-source language models with mixed-quality data,” 2023.
- L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P.-S. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadeh, Z. Kenton, S. Brown, W. Hawkins, T. Stepleton, C. Biles, A. Birhane, J. Haas, L. Rimell, L. A. Hendricks, W. Isaac, S. Legassick, G. Irving, and I. Gabriel, “Ethical and social risks of harm from language models,” 2021.
- J. Ji, M. Liu, J. Dai, X. Pan, C. Zhang, C. Bian, C. Zhang, R. Sun, Y. Wang, and Y. Yang, “Beavertails: Towards improved safety alignment of llm via a human-preference dataset,” 2023.
- I. Solaiman and C. Dennison, “Process for adapting language models to society (palms) with values-targeted datasets,” Advances in Neural Information Processing Systems, vol. 34, pp. 5861–5873, 2021.
- L. Qiu, Y. Zhao, J. Li, P. Lu, B. Peng, J. Gao, and S.-C. Zhu, “Valuenet: A new dataset for human value driven dialogue system,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 10, 2022, pp. 11 183–11 191.
- J. Kiesel, M. Alshomary, N. Handke, X. Cai, H. Wachsmuth, and B. Stein, “Identifying the human values behind arguments,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 4459–4471. [Online]. Available: https://aclanthology.org/2022.acl-long.306
- R. Liu, G. Zhang, X. Feng, and S. Vosoughi, “Aligning generative language models with human values,” in Findings of the Association for Computational Linguistics: NAACL 2022, M. Carpuat, M.-C. de Marneffe, and I. V. Meza Ruiz, Eds. Seattle, United States: Association for Computational Linguistics, Jul. 2022, pp. 241–252. [Online]. Available: https://aclanthology.org/2022.findings-naacl.18
- A. Glaese, N. McAleese, M. Trebacz, J. Aslanides, V. Firoiu, T. Ewalds, M. Rauh, L. Weidinger, M. Chadwick, P. Thacker et al., “Improving alignment of dialogue agents via targeted human judgements,” arXiv preprint arXiv:2209.14375, 2022.
- H. Sun, Z. Zhang, F. Mi, Y. Wang, W. Liu, J. Cui, B. Wang, Q. Liu, and M. Huang, “MoralDial: A framework to train and evaluate moral dialogue systems via moral discussions,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 2213–2230. [Online]. Available: https://aclanthology.org/2023.acl-long.123
- J. Yao, X. Yi, X. Wang, J. Wang, and X. Xie, “From instructions to intrinsic human values – a survey of alignment goals for big models,” 2023.
- Y. Liu, Y. Yao, J.-F. Ton, X. Zhang, R. G. H. Cheng, Y. Klochkov, M. F. Taufiq, and H. Li, “Trustworthy llms: a survey and guideline for evaluating large language models’ alignment,” arXiv preprint arXiv:2308.05374, 2023.
- J. Qian, H. Wang, Z. Li, S. Li, and X. Yan, “Limitations of language models in arithmetic and symbolic induction,” 2022.
- X. She, Y. Liu, Y. Zhao, Y. He, L. Li, C. Tantithamthavorn, Z. Qin, and H. Wang, “Pitfalls in language models for code intelligence: A taxonomy and survey,” 2023.
- H. Manikandan, Y. Jiang, and J. Z. Kolter, “Language models are weak learners,” 2023.
- Y. Liang, C. Wu, T. Song, W. Wu, Y. Xia, Y. Liu, Y. Ou, S. Lu, L. Ji, S. Mao, Y. Wang, L. Shou, M. Gong, and N. Duan, “Taskmatrix.ai: Completing tasks by connecting foundation models with millions of apis,” 2023.
- G. Mialon, R. Dessì, M. Lomeli, C. Nalmpantis, R. Pasunuru, R. Raileanu, B. Rozière, T. Schick, J. Dwivedi-Yu, A. Celikyilmaz, E. Grave, Y. LeCun, and T. Scialom, “Augmented language models: a survey,” 2023.
- A. Parisi, Y. Zhao, and N. Fiedel, “Talm: Tool augmented language models,” 2022.
- R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders, X. Jiang, K. Cobbe, T. Eloundou, G. Krueger, K. Button, M. Knight, B. Chess, and J. Schulman, “Webgpt: Browser-assisted question-answering with human feedback,” 2022.
- Y. Qin, Z. Cai, D. Jin, L. Yan, S. Liang, K. Zhu, Y. Lin, X. Han, N. Ding, H. Wang, R. Xie, F. Qi, Z. Liu, M. Sun, and J. Zhou, “WebCPM: Interactive web search for Chinese long-form question answering,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 8968–8988. [Online]. Available: https://aclanthology.org/2023.acl-long.499
- Y. Song, W. Xiong, D. Zhu, W. Wu, H. Qian, M. Song, H. Huang, C. Li, K. Wang, R. Yao, Y. Tian, and S. Li, “Restgpt: Connecting large language models with real-world restful apis,” 2023.
- T. Cai, X. Wang, T. Ma, X. Chen, and D. Zhou, “Large language models as tool makers,” 2023.
- Y. Shen, K. Song, X. Tan, D. Li, W. Lu, and Y. Zhuang, “Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,” 2023.
- S. Hao, T. Liu, Z. Wang, and Z. Hu, “Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings,” 2024.
- S. Yuan, K. Song, J. Chen, X. Tan, Y. Shen, R. Kan, D. Li, and D. Yang, “Easytool: Enhancing llm-based agents with concise tool instruction,” 2024.
- S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, “Opt: Open pre-trained transformer language models,” 2022.
- T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- W. Huang, P. Abbeel, D. Pathak, and I. Mordatch, “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,” in International Conference on Machine Learning. PMLR, 2022, pp. 9118–9147.
- I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “Progprompt: Generating situated robot task plans using large language models,” 2022.
- D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, and E. Chi, “Least-to-most prompting enables complex reasoning in large language models,” 2023.
- C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y. Su, “Llm-planner: Few-shot grounded planning for embodied agents with large language models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2998–3009.
- Z. Wang, S. Cai, A. Liu, X. Ma, and Y. Liang, “Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents,” arXiv preprint arXiv:2302.01560, 2023.
- S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” arXiv preprint arXiv:2305.10601, 2023.
- B. Liu, Y. Jiang, X. Zhang, Q. Liu, S. Zhang, J. Biswas, and P. Stone, “Llm+ p: Empowering large language models with optimal planning proficiency,” arXiv preprint arXiv:2304.11477, 2023.
- S. Hao, Y. Gu, H. Ma, J. J. Hong, Z. Wang, D. Z. Wang, and Z. Hu, “Reasoning with language model is planning with world model,” arXiv preprint arXiv:2305.14992, 2023.
- M. Hu, Y. Mu, X. Yu, M. Ding, S. Wu, W. Shao, Q. Chen, B. Wang, Y. Qiao, and P. Luo, “Tree-planner: Efficient close-loop task planning with large language models,” arXiv preprint arXiv:2310.08582, 2023.
- B. Y. Lin, C. Huang, Q. Liu, W. Gu, S. Sommerer, and X. Ren, “On grounded planning for embodied tasks with language models,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 11, 2023, pp. 13 192–13 200.
- K. Valmeekam, M. Marquez, S. Sreedharan, and S. Kambhampati, “On the planning abilities of large language models - a critical investigation,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023. [Online]. Available: https://openreview.net/forum?id=X6dEqXIsEW
- T. Sumers, K. Marino, A. Ahuja, R. Fergus, and I. Dasgupta, “Distilling internet-scale vision-language models into embodied agents,” in Proceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023.
- Y. Yang, T. Zhou, K. Li, D. Tao, L. Li, L. Shen, X. He, J. Jiang, and Y. Shi, “Embodied multi-modal agent trained by an llm from a parallel textworld,” 2023.
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” 2019.
- J. Li, L. Gui, Y. Zhou, D. West, C. Aloisi, and Y. He, “Distilling chatgpt for explainable automated student answer assessment,” in EMNLP (Findings). Association for Computational Linguistics, 2023, pp. 6007–6026.
- R. Tang, X. Han, X. Jiang, and X. Hu, “Does synthetic data generation of llms help clinical text mining?” arXiv preprint arXiv:2303.04360, 2023.
- X. He, I. Nassar, J. Kiros, G. Haffari, and M. Norouzi, “Generate, annotate, and learn: NLP with synthetic text,” Trans. Assoc. Comput. Linguistics, vol. 10, pp. 826–842, 2022. [Online]. Available: https://transacl.org/ojs/index.php/tacl/article/view/3811
- Y. Meng, J. Huang, Y. Zhang, and J. Han, “Generating training data with language models: Towards zero-shot language understanding,” in Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. [Online]. Available: http://papers.nips.cc/paper_files/paper/2022/hash/0346c148ba1c21c6b4780a961ea141dc-Abstract-Conference.html
- J. Wang, Z. Yao, A. Mitra, S. Osebe, Z. Yang, and H. Yu, “UMASS_BioNLP at MEDIQA-chat 2023: Can LLMs generate high-quality synthetic note-oriented doctor-patient conversations?” in Proceedings of the 5th Clinical Natural Language Processing Workshop, T. Naumann, A. Ben Abacha, S. Bethard, K. Roberts, and A. Rumshisky, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 460–471. [Online]. Available: https://aclanthology.org/2023.clinicalnlp-1.49
- Z. Yang, S. Cherian, and S. Vucetic, “Data augmentation for radiology report simplification,” in Findings of the Association for Computational Linguistics: EACL 2023, A. Vlachos and I. Augenstein, Eds. Dubrovnik, Croatia: Association for Computational Linguistics, May 2023, pp. 1922–1932. [Online]. Available: https://aclanthology.org/2023.findings-eacl.144
- X. Ma, X. Zhang, R. Pradeep, and J. Lin, “Zero-shot listwise document reranking with a large language model,” 2023.
- Z. Qin, R. Jagerman, K. Hui, H. Zhuang, J. Wu, J. Shen, T. Liu, J. Liu, D. Metzler, X. Wang, and M. Bendersky, “Large language models are effective text rankers with pairwise ranking prompting,” 2023.
- X. Ma, Y. Gong, P. He, H. Zhao, and N. Duan, “Query rewriting in retrieval-augmented large language models,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 5303–5315. [Online]. Available: https://aclanthology.org/2023.emnlp-main.322
- D. Sachan, M. Lewis, M. Joshi, A. Aghajanyan, W.-t. Yih, J. Pineau, and L. Zettlemoyer, “Improving passage retrieval with zero-shot question generation,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 2022, pp. 3781–3797. [Online]. Available: https://aclanthology.org/2022.emnlp-main.249
- D. S. Sachan, M. Lewis, D. Yogatama, L. Zettlemoyer, J. Pineau, and M. Zaheer, “Questions are all you need to train a dense passage retriever,” Transactions of the Association for Computational Linguistics, vol. 11, pp. 600–616, 2023. [Online]. Available: https://aclanthology.org/2023.tacl-1.35
- T. Schick and H. Schütze, “Generating datasets with pretrained language models,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, M.-F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, Eds. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021, pp. 6943–6951. [Online]. Available: https://aclanthology.org/2021.emnlp-main.555
- Z. Peng, X. Wu, and Y. Fang, “Soft prompt tuning for augmenting dense retrieval with large language models,” arXiv preprint arXiv:2307.08303, 2023.
- J. Saad-Falcon, O. Khattab, K. Santhanam, R. Florian, M. Franz, S. Roukos, A. Sil, M. A. Sultan, and C. Potts, “UDAPDR: unsupervised domain adaptation via LLM prompting and distillation of rerankers,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, 2023, pp. 11 265–11 279. [Online]. Available: https://aclanthology.org/2023.emnlp-main.693
- V. Jeronymo, L. Bonifacio, H. Abonizio, M. Fadaee, R. Lotufo, J. Zavrel, and R. Nogueira, “Inpars-v2: Large language models as efficient dataset generators for information retrieval,” arXiv preprint arXiv:2301.01820, 2023.
- W. Sun, Z. Chen, X. Ma, L. Yan, S. Wang, P. Ren, Z. Chen, D. Yin, and Z. Ren, “Instruction distillation makes large language models efficient zero-shot rankers,” 2023.
- C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., vol. 21, no. 1, jan 2020.
- S. Bruch, X. Wang, M. Bendersky, and M. Najork, “An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance,” in Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR 2019, Santa Clara, CA, USA, October 2-5, 2019, 2019, pp. 75–78. [Online]. Available: https://doi.org/10.1145/3341981.3344221
- C. Burges, T. Shaked, E. Renshaw, A. Lazier, M. Deeds, N. Hamilton, and G. Hullender, “Learning to rank using gradient descent,” in Proceedings of the 22nd International Conference on Machine Learning, ser. ICML ’05. New York, NY, USA: Association for Computing Machinery, 2005, p. 89–96. [Online]. Available: https://doi.org/10.1145/1102351.1102363
- X. Wang, C. Li, N. Golbandi, M. Bendersky, and M. Najork, “The lambdaloss framework for ranking metric optimization,” in Proceedings of the 27th ACM International Conference on Information and Knowledge Management, ser. CIKM ’18. New York, NY, USA: Association for Computing Machinery, 2018, p. 1313–1322. [Online]. Available: https://doi.org/10.1145/3269206.3271784
- W. Wang, X. Lin, F. Feng, X. He, and T.-S. Chua, “Generative recommendation: Towards next-generation recommender paradigm,” 2023.
- S. Dai, N. Shao, H. Zhao, W. Yu, Z. Si, C. Xu, Z. Sun, X. Zhang, and J. Xu, “Uncovering chatgpt’s capabilities in recommender systems,” in Proceedings of the 17th ACM Conference on Recommender Systems, ser. RecSys ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 1126–1132. [Online]. Available: https://doi.org/10.1145/3604915.3610646
- Y. Xi, W. Liu, J. Lin, X. Cai, H. Zhu, J. Zhu, B. Chen, R. Tang, W. Zhang, R. Zhang, and Y. Yu, “Towards open-world recommendation with knowledge augmentation from large language models,” 2023.
- X. Ren, W. Wei, L. Xia, L. Su, S. Cheng, J. Wang, D. Yin, and C. Huang, “Representation learning with large language models for recommendation,” 2023.
- W. Wei, X. Ren, J. Tang, Q. Wang, L. Su, S. Cheng, J. Wang, D. Yin, and C. Huang, “Llmrec: Large language models with graph augmentation for recommendation,” 2024.
- L. Wang, S. Zhang, Y. Wang, E.-P. Lim, and Y. Wang, “LLM4Vis: Explainable visualization recommendation using ChatGPT,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, M. Wang and I. Zitouni, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 675–692. [Online]. Available: https://aclanthology.org/2023.emnlp-industry.64
- Z. Cui, J. Ma, C. Zhou, J. Zhou, and H. Yang, “M6-rec: Generative pretrained language models are open-ended recommender systems,” 2022.
- P. Liu, L. Zhang, and J. A. Gulla, “Pre-train, prompt and recommendation: A comprehensive survey of language modelling paradigm adaptations in recommender systems,” 2023.
- K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ser. ACL ’02. USA: Association for Computational Linguistics, 2002, p. 311–318. [Online]. Available: https://doi.org/10.3115/1073083.1073135
- C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013
- C. Su and C. McMillan, “Distilled GPT for source code summarization,” CoRR, vol. abs/2308.14731, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.14731
- W. Guo, J. Yang, K. Yang, X. Li, Z. Rao, Y. Xu, and D. Niu, “Instruction fusion: Advancing prompt evolution through hybridization,” CoRR, vol. abs/2312.15692, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.15692
- O. Sener and S. Savarese, “Active learning for convolutional neural networks: A core-set approach,” in 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings, 2018. [Online]. Available: https://openreview.net/forum?id=H1aIuk-RW
- H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” 2023.
- S. Zhang, P. Sun, S. Chen, M. Xiao, W. Shao, W. Zhang, Y. Liu, K. Chen, and P. Luo, “Gpt4roi: Instruction tuning large language model on region-of-interest,” 2023.
- OpenAI, “Gpt-4v(ision) system card,” 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:263218031
- B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2641–2649.
- L. Li, Z. Xie, M. Li, S. Chen, P. Wang, L. Chen, Y. Yang, B. Wang, and L. Kong, “Silkie: Preference distillation for large visual language models,” arXiv preprint arXiv:2312.10665, 2023.
- H. Ha, P. Florence, and S. Song, “Scaling up and distilling down: Language-guided robot skill acquisition,” in Conference on Robot Learning. PMLR, 2023, pp. 3766–3777.
- S. Wu, Z. Liu, Z. Zhang, Z. Chen, W. Deng, W. Zhang, J. Yang, Z. Yao, Y. Lyu, X. Xin, S. Gao, P. Ren, Z. Ren, and Z. Chen, “fuzi.mingcha,” https://github.com/irlab-sdu/fuzi.mingcha, 2023.
- H. Xiong, S. Wang, Y. Zhu, Z. Zhao, Y. Liu, Q. Wang, and D. Shen, “Doctorglm: Fine-tuning your chinese doctor is not a herculean task,” arXiv preprint arXiv:2304.01097, 2023.
- X. Zhang, C. Tian, X. Yang, L. Chen, Z. Li, and L. R. Petzold, “Alpacare: Instruction-tuned large language models for medical application,” arXiv preprint arXiv:2310.14558, 2023.
- Y. Li, Z. Li, K. Zhang, R. Dan, S. Jiang, and Y. Zhang, “Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge,” Cureus, vol. 15, no. 6, 2023.
- T. Han, L. C. Adams, J. Papaioannou, P. Grundmann, T. Oberhauser, A. Löser, D. Truhn, and K. K. Bressem, “Medalpaca - an open-source collection of medical conversational AI models and training data,” CoRR, vol. abs/2304.08247, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.08247
- C. Wu, W. Lin, X. Zhang, Y. Zhang, Y. Wang, and W. Xie, “Pmc-llama: Towards building open-source language models for medicine,” arXiv preprint arXiv:2305.10415, vol. 6, 2023.
- Z. Bao, W. Chen, S. Xiao, K. Ren, J. Wu, C. Zhong, J. Peng, X. Huang, and Z. Wei, “Disc-medllm: Bridging general large language models and real-world medical consultation,” CoRR, vol. abs/2308.14346, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.14346
- Z. Gou, Z. Shao, Y. Gong, yelong shen, Y. Yang, M. Huang, N. Duan, and W. Chen, “ToRA: A tool-integrated reasoning agent for mathematical problem solving,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=Ep0TtjVoap
- E. Perkowski, R. Pan, T. D. Nguyen, Y. Ting, S. Kruk, T. Zhang, C. O’Neill, M. Jablonska, Z. Sun, M. J. Smith, H. Liu, K. Schawinski, K. Iyer, I. Ciuca, and UniverseTBD, “Astrollama-chat: Scaling astrollama with conversational and diverse datasets,” CoRR, vol. abs/2401.01916, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.01916
- J. Gao, R. Pi, J. Zhang, J. Ye, W. Zhong, Y. Wang, L. Hong, J. Han, H. Xu, Z. Li, and L. Kong, “G-llava: Solving geometric problem with multi-modal large language model,” CoRR, vol. abs/2312.11370, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.11370
- H. Zhao, S. Liu, C. Ma, H. Xu, J. Fu, Z.-H. Deng, L. Kong, and Q. Liu, “GIMLET: A unified graph-text model for instruction-based molecule zero-shot learning,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023. [Online]. Available: https://openreview.net/forum?id=Tt6DrRCgJV
- A. N. Rubungo, C. Arnold, B. P. Rand, and A. B. Dieng, “Llm-prop: Predicting physical and electronic properties of crystalline solids from their text descriptions,” CoRR, vol. abs/2310.14029, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.14029
- H. Cao, Z. Liu, X. Lu, Y. Yao, and Y. Li, “Instructmol: Multi-modal integration for building a versatile and reliable molecular assistant in drug discovery,” CoRR, vol. abs/2311.16208, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.16208
- H. Abdine, M. Chatzianastasis, C. Bouyioukos, and M. Vazirgiannis, “Prot2text: Multimodal protein’s function generation with GNNs and transformers,” in Deep Generative Models for Health Workshop NeurIPS 2023, 2023. [Online]. Available: https://openreview.net/forum?id=EJ7YNgWYFj
- Y. Luo, J. Zhang, S. Fan, K. Yang, Y. Wu, M. Qiao, and Z. Nie, “Biomedgpt: Open multimodal generative pre-trained transformer for biomedicine,” arXiv preprint arXiv:2308.09442, 2023.
- B. Chen, X. Cheng, P. Li, Y. Geng, J. Gong, S. Li, Z. Bei, X. Tan, B. Wang, X. Zeng, C. Liu, A. Zeng, Y. Dong, J. Tang, and L. Song, “xtrimopglm: Unified 100b-scale pre-trained transformer for deciphering the language of protein,” CoRR, vol. abs/2401.06199, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.06199
- C. Deng, T. Zhang, Z. He, Y. Xu, Q. Chen, Y. Shi, L. Fu, W. Zhang, X. Wang, C. Zhou, Z. Lin, and J. He, “K2: A foundation language model for geoscience knowledge understanding and utilization,” 2023.
- Z. Bi, N. Zhang, Y. Xue, Y. Ou, D. Ji, G. Zheng, and H. Chen, “Oceangpt: A large language model for ocean science tasks,” CoRR, vol. abs/2310.02031, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.02031
- Z. Zheng, J. Zhang, T. Vu, S. Diao, Y. H. W. Tim, and S. Yeung, “Marinegpt: Unlocking secrets of ocean to the public,” CoRR, vol. abs/2310.13596, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.13596
- Z. Lin, C. Deng, L. Zhou, T. Zhang, Y. Xu, Y. Xu, Z. He, Y. Shi, B. Dai, Y. Song, B. Zeng, Q. Chen, T. Shi, T. Huang, Y. Xu, S. Wang, L. Fu, W. Zhang, J. He, C. Ma, Y. Zhu, X. Wang, and C. Zhou, “Geogalactica: A scientific large language model in geoscience,” CoRR, vol. abs/2401.00434, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.00434
- D. Zhang, A. Petrova, D. Trautmann, and F. Schilder, “Unleashing the power of large language models for legal applications,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 5257–5258.
- Z. Sun, “A short survey of viewing large language models in legal aspect,” arXiv preprint arXiv:2303.09136, 2023.
- J. Lai, W. Gan, J. Wu, Z. Qi, and P. S. Yu, “Large language models in law: A survey,” arXiv preprint arXiv:2312.03718, 2023.
- S. Yue, W. Chen, S. Wang, B. Li, C. Shen, S. Liu, Y. Zhou, Y. Xiao, S. Yun, W. Lin et al., “Disc-lawllm: Fine-tuning large language models for intelligent legal services,” arXiv preprint arXiv:2309.11325, 2023.
- H. Zhong, C. Xiao, C. Tu, T. Zhang, Z. Liu, and M. Sun, “Jec-qa: a legal-domain question answering dataset,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, 2020, pp. 9701–9708.
- K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, L. Hou, K. Clark, S. Pfohl, H. Cole-Lewis, D. Neal, M. Schaekermann, A. Wang, M. Amin, S. Lachgar, P. A. Mansfield, S. Prakash, B. Green, E. Dominowska, B. A. y Arcas, N. Tomasev, Y. Liu, R. Wong, C. Semturs, S. S. Mahdavi, J. K. Barral, D. R. Webster, G. S. Corrado, Y. Matias, S. Azizi, A. Karthikesalingam, and V. Natarajan, “Towards expert-level medical question answering with large language models,” CoRR, vol. abs/2305.09617, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.09617
- X. Yang, J. Gao, W. Xue, and E. Alexandersson, “Pllama: An open-source large language model for plant science,” CoRR, vol. abs/2401.01600, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.01600
- X. Wang, G. H. Chen, D. Song, Z. Zhang, Z. Chen, Q. Xiao, F. Jiang, J. Li, X. Wan, B. Wang et al., “Cmb: A comprehensive medical benchmark in chinese,” arXiv preprint arXiv:2308.08833, 2023.
- W. Zhu, X. Wang, H. Zheng, M. Chen, and B. Tang, “Promptcblue: A chinese prompt tuning benchmark for the medical domain,” arXiv preprint arXiv:2310.14151, 2023.
- Z. Bao, W. Chen, S. Xiao, K. Ren, J. Wu, C. Zhong, J. Peng, X. Huang, and Z. Wei, “Disc-medllm: Bridging general large language models and real-world medical consultation,” arXiv preprint arXiv:2308.14346, 2023.
- C. Wu, X. Zhang, Y. Zhang, Y. Wang, and W. Xie, “Pmc-llama: Further finetuning llama on medical papers,” CoRR, vol. abs/2304.14454, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.14454
- S. Xue, F. Zhou, Y. Xu, H. Zhao, S. Xie, Q. Dai, C. Jiang, J. Zhang, J. Zhou, D. Xiu, and H. Mei, “Weaverbird: Empowering financial decision-making with large language model, knowledge base, and search engine,” CoRR, vol. abs/2308.05361, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.05361
- S. Wu, O. Irsoy, S. Lu, V. Dabravolski, M. Dredze, S. Gehrmann, P. Kambadur, D. S. Rosenberg, and G. Mann, “Bloomberggpt: A large language model for finance,” CoRR, vol. abs/2303.17564, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.17564
- D. Lu, H. Wu, J. Liang, Y. Xu, Q. He, Y. Geng, M. Han, Y. Xin, and Y. Xiao, “Bbt-fin: Comprehensive construction of chinese financial domain pre-trained language model, corpus and benchmark,” CoRR, vol. abs/2302.09432, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2302.09432
- Y. Yang, Y. Tang, and K. Y. Tam, “Investlm: A large language model for investment using financial domain instruction tuning,” CoRR, vol. abs/2309.13064, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.13064
- Q. Xie, W. Han, X. Zhang, Y. Lai, M. Peng, A. Lopez-Lira, and J. Huang, “PIXIU: A large language model, instruction data and evaluation benchmark for finance,” CoRR, vol. abs/2306.05443, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2306.05443
- N. Wang, H. Yang, and C. D. Wang, “Fingpt: Instruction tuning benchmark for open-source large language models in financial datasets,” CoRR, vol. abs/2310.04793, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.04793
- R. Taylor, M. Kardas, G. Cucurull, T. Scialom, A. Hartshorn, E. Saravia, A. Poulton, V. Kerkez, and R. Stojnic, “Galactica: A large language model for science,” CoRR, vol. abs/2211.09085, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2211.09085
- J. Yin, S. Dash, F. Wang, and M. Shankar, “FORGE: pre-training open foundation models for science,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2023, Denver, CO, USA, November 12-17, 2023, D. Arnold, R. M. Badia, and K. M. Mohror, Eds. ACM, 2023, pp. 81:1–81:13. [Online]. Available: https://doi.org/10.1145/3581784.3613215
- Z. Azerbayev, H. Schoelkopf, K. Paster, M. D. Santos, S. McAleer, A. Q. Jiang, J. Deng, S. Biderman, and S. Welleck, “Llemma: An open language model for mathematics,” CoRR, vol. abs/2310.10631, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.10631
- F. Yu, A. Gao, and B. Wang, “Outcome-supervised verifiers for planning in mathematical reasoning,” CoRR, vol. abs/2311.09724, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.09724
- T. D. Nguyen, Y. Ting, I. Ciuca, C. O’Neill, Z. Sun, M. Jablonska, S. Kruk, E. Perkowski, J. W. Miller, J. Li, J. Peek, K. Iyer, T. Rózanski, P. Khetarpal, S. Zaman, D. Brodrick, S. J. R. Méndez, T. Bui, A. Goodman, A. Accomazzi, J. P. Naiman, J. Cranney, K. Schawinski, and UniverseTBD, “Astrollama: Towards specialized foundation models in astronomy,” CoRR, vol. abs/2309.06126, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.06126
- J. Roberts, T. Lüddecke, S. Das, K. Han, and S. Albanie, “Gpt4geo: How a language model sees the world’s geography,” 2023.
- Z. Lin, C. Deng, L. Zhou, T. Zhang, Y. Xu, Y. Xu, Z. He, Y. Shi, B. Dai, Y. Song, B. Zeng, Q. Chen, T. Shi, T. Huang, Y. Xu, S. Wang, L. Fu, W. Zhang, J. He, C. Ma, Y. Zhu, X. Wang, and C. Zhou, “Geogalactica: A scientific large language model in geoscience,” 2023.
- C. Wang, D. Engler, X. Li, J. Hou, D. J. Wald, K. Jaiswal, and S. Xu, “Near-real-time earthquake-induced fatality estimation using crowdsourced data and large-language models,” 2023.
- L. Chen, S. Li, J. Yan, H. Wang, K. Gunaratna, V. Yadav, Z. Tang, V. Srinivasan, T. Zhou, H. Huang, and H. Jin, “Alpagasus: Training a better alpaca with fewer data,” 2023.
- Y. Cao, Y. Kang, and L. Sun, “Instruction mining: High-quality instruction data selection for large language models,” 2023.
- M. Li, Y. Zhang, Z. Li, J. Chen, L. Chen, N. Cheng, J. Wang, T. Zhou, and J. Xiao, “From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning,” ArXiv, vol. abs/2308.12032, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:261076515
- Q. Du, C. Zong, and J. Zhang, “Mods: Model-oriented data selection for instruction tuning,” 2023.
- Y. Li, B. Hui, X. Xia, J. Yang, M. Yang, L. Zhang, S. Si, J. Liu, T. Liu, F. Huang, and Y. Li, “One shot learning as instruction data prospector for large language models,” 2023.
- E. Frantar, S. P. Singh, and D. Alistarh, “Optimal brain compression: A framework for accurate post-training quantization and pruning,” 2023.
- T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer, “GPT3.int8(): 8-bit matrix multiplication for transformers at scale,” in Advances in Neural Information Processing Systems, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022. [Online]. Available: https://openreview.net/forum?id=dXiGWqBoxaD
- Y. J. Kim, R. Henry, R. Fahim, and H. H. Awadalla, “Finequant: Unlocking efficiency with fine-grained weight-only quantization for llms,” 2023.
- C. Tao, L. Hou, W. Zhang, L. Shang, X. Jiang, Q. Liu, P. Luo, and N. Wong, “Compression of generative pre-trained language models via quantization,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 4821–4836. [Online]. Available: https://aclanthology.org/2022.acl-long.331
- Z. Yao, R. Yazdani Aminabadi, M. Zhang, X. Wu, C. Li, and Y. He, “Zeroquant: Efficient and affordable post-training quantization for large-scale transformers,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 168–27 183, 2022.
- G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” 2023.
- X. Ma, G. Fang, and X. Wang, “Llm-pruner: On the structural pruning of large language models,” 2023.
- M. Zhang, H. Chen, C. Shen, Z. Yang, L. Ou, X. Yu, and B. Zhuang, “Loraprune: Pruning meets low-rank parameter-efficient fine-tuning,” 2023.
- E. Frantar and D. Alistarh, “Sparsegpt: Massive language models can be accurately pruned in one-shot,” 2023.
- M. Xu, Y. L. Xu, and D. P. Mandic, “Tensorgpt: Efficient compression of the embedding layer in llms based on the tensor-train decomposition,” 2023.
- Y. Li, Y. Yu, Q. Zhang, C. Liang, P. He, W. Chen, and T. Zhao, “Losparse: Structured compression of large language models based on low-rank and sparse approximation,” 2023.
- Z. Hu, L. Wang, Y. Lan, W. Xu, E.-P. Lim, L. Bing, X. Xu, S. Poria, and R. K.-W. Lee, “Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models,” 2023.
- H. Liu, D. Tam, M. Mohammed, J. Mohta, T. Huang, M. Bansal, and C. Raffel, “Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning,” in Advances in Neural Information Processing Systems, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022. [Online]. Available: https://openreview.net/forum?id=rBCvMG-JsPd
- Y. Wang, S. Agarwal, S. Mukherjee, X. Liu, J. Gao, A. H. Awadallah, and J. Gao, “AdaMix: Mixture-of-adaptations for parameter-efficient model tuning,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 2022, pp. 5744–5760. [Online]. Available: https://aclanthology.org/2022.emnlp-main.388
- E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” 2021.
- X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), C. Zong, F. Xia, W. Li, and R. Navigli, Eds. Online: Association for Computational Linguistics, Aug. 2021, pp. 4582–4597. [Online]. Available: https://aclanthology.org/2021.acl-long.353
- X. Liu, K. Ji, Y. Fu, W. Tam, Z. Du, Z. Yang, and J. Tang, “P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 61–68. [Online]. Available: https://aclanthology.org/2022.acl-short.8
- T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” 2023.
- J. Kim, J. H. Lee, S. Kim, J. Park, K. M. Yoo, S. J. Kwon, and D. Lee, “Memory-efficient fine-tuning of compressed large language models via sub-4-bit integer quantization,” 2023.
- S. Malladi, T. Gao, E. Nichani, A. Damian, J. D. Lee, D. Chen, and S. Arora, “Fine-tuning language models with just forward passes,” 2024.
- Z. Wan, X. Wang, C. Liu, S. Alam, Y. Zheng, J. Liu, Z. Qu, S. Yan, Y. Zhu, Q. Zhang, M. Chowdhury, and M. Zhang, “Efficient large language models: A survey,” 2024.
- Y.-S. Lee, M. Sultan, Y. El-Kurdi, T. Naseem, A. Munawar, R. Florian, S. Roukos, and R. Astudillo, “Ensemble-instruct: Instruction tuning data generation with a heterogeneous mixture of LMs,” in Findings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 12 561–12 571. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.836
- W. Chen, Y. Zhou, N. Du, Y. Huang, J. Laudon, Z. Chen, and C. Cui, “Lifelong language pretraining with distribution-specialized experts,” in International Conference on Machine Learning. PMLR, 2023, pp. 5383–5395.
- S. Kotha, J. M. Springer, and A. Raghunathan, “Understanding catastrophic forgetting in language models via implicit inference,” arXiv preprint arXiv:2309.10105, 2023.
- B. Koloski, B. Škrlj, M. Robnik-Šikonja, and S. Pollak, “Measuring catastrophic forgetting in cross-lingual transfer paradigms: Exploring tuning strategies,” arXiv preprint arXiv:2309.06089, 2023.
- T. Wu, L. Luo, Y.-F. Li, S. Pan, T.-T. Vu, and G. Haffari, “Continual learning for large language models: A survey,” arXiv preprint arXiv:2402.01364, 2024.
- Y. Luo, Z. Yang, F. Meng, Y. Li, J. Zhou, and Y. Zhang, “An empirical study of catastrophic forgetting in large language models during continual fine-tuning,” arXiv preprint arXiv:2308.08747, 2023.
- J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,” Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017.
- M. Rostami, S. Kolouri, and P. K. Pilly, “Complementary learning for overcoming catastrophic forgetting using experience replay,” arXiv preprint arXiv:1903.04566, 2019.
- D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, and G. Wayne, “Experience replay for continual learning,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- S.-W. Lee, J.-H. Kim, J. Jun, J.-W. Ha, and B.-T. Zhang, “Overcoming catastrophic forgetting by incremental moment matching,” Advances in neural information processing systems, vol. 30, 2017.
- A. Mallya, D. Davis, and S. Lazebnik, “Piggyback: Adapting a single network to multiple tasks by learning to mask weights,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 67–82.
- Z. Wang, Z. Zhang, C.-Y. Lee, H. Zhang, R. Sun, X. Ren, G. Su, V. Perot, J. Dy, and T. Pfister, “Learning to prompt for continual learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 139–149.
- Z. Hu, Y. Li, J. Lyu, D. Gao, and N. Vasconcelos, “Dense network expansion for class incremental learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 858–11 867.
- X. Li, L. Lin, S. Wang, and C. Qian, “Unlock the power: Competitive distillation for multi-modal large language models,” arXiv preprint arXiv:2311.08213, 2023.
- M. Zeng, W. Xue, Q. Liu, and Y. Guo, “Continual learning with dirichlet generative-based rehearsal,” arXiv preprint arXiv:2309.06917, 2023.
- Z. Zhang, M. Fang, L. Chen, and M.-R. Namazi-Rad, “Citb: A benchmark for continual instruction tuning,” arXiv preprint arXiv:2310.14510, 2023.
- C. Burns, P. Izmailov, J. H. Kirchner, B. Baker, L. Gao, L. Aschenbrenner, Y. Chen, A. Ecoffet, M. Joglekar, J. Leike, I. Sutskever, and J. Wu, “Weak-to-strong generalization: Eliciting strong capabilities with weak supervision,” CoRR, vol. abs/2312.09390, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.09390
- M. Li, Y. Zhang, S. He, Z. Li, H. Zhao, J. Wang, N. Cheng, and T. Zhou, “Superfiltering: Weak-to-strong data filtering for fast instruction-tuning,” CoRR, vol. abs/2402.00530, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.00530
- J. Ji, B. Chen, H. Lou, D. Hong, B. Zhang, X. Pan, J. Dai, and Y. Yang, “Aligner: Achieving efficient alignment through weak-to-strong correction,” CoRR, vol. abs/2402.02416, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.02416
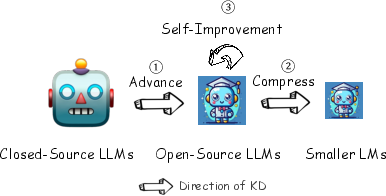
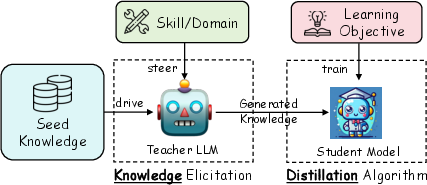
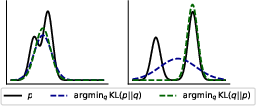
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

