- The paper identifies that prevalent noise, including SQL errors and ambiguous queries, significantly skews model performance metrics.
- The analysis shows that correcting SQL queries leads to drastic changes in model rankings, emphasizing the benchmark's sensitivity.
- The study advocates for rigorous data cleaning and noise annotation to enhance the reliability of Text-to-SQL evaluations.
Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark
Introduction
The paper investigates the role of noise in the Text-to-SQL domain, focusing on the BIRD-Bench benchmark. Text-to-SQL involves transforming natural language into SQL queries, a task that is vital for enabling non-experts to query databases. Despite the importance of this task, designing effective models is challenging, particularly due to noise such as ambiguous questions and syntactical errors. BIRD-Bench, while not intended to contain noisy queries explicitly, does contain extensive noise, influencing model evaluations and benchmarks.

Figure 1: Example of an incorrect SQL query that generates the wrong gold reference answer for the given question.
A striking finding is the prevalence of incorrect gold SQL queries within BIRD-Bench, which can lead to inaccurate model performance statistics. Furthermore, the paper reveals that zero-shot models outperform state-of-the-art prompting methods when tested on corrected SQL queries, emphasizing the importance of reliable benchmarks for advancing Text-to-SQL research.
Noise Analysis in BIRD-Bench
The research presents a qualitative analysis of noise across various domains within the BIRD-Bench.
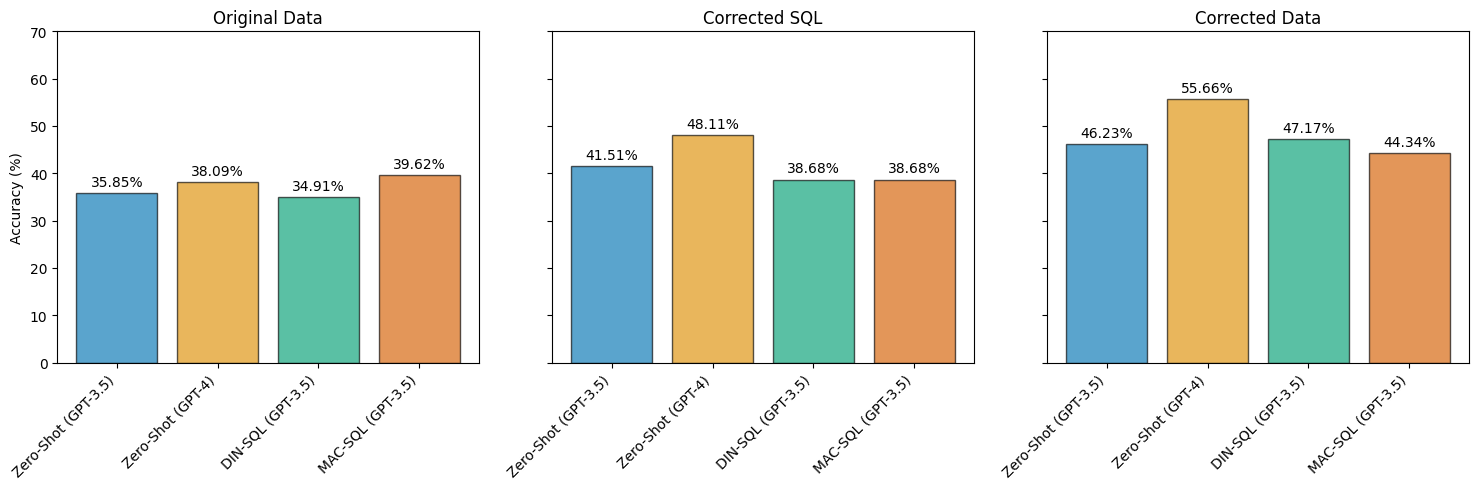
Figure 2: Accuracy of various models on Bird-Bench's financial domain. Models are evaluated on the original data (left), corrected SQL queries (middle), and corrected SQL queries and corrected noisy questions.
Table 1 summarizes the frequency and types of noise encountered across domains, highlighting that noise is unevenly distributed, affecting domains and categories differently. The financial domain exhibits the highest noise level at 49%, whereas the Superhero domain has the lowest at 15%. Variations in noise significantly impact model accuracy, questioning the benchmark's reliability in assessing real-world performance.
Moreover, errors in SQL queries, as shown in Figure 1, where incorrect JOIN operations mismatches data entries, complicate evaluations and model development. Accurate benchmarks necessitate correcting such errors to ensure data reliability.
Evaluating different models on varied datasets demonstrated substantial shifts in performance due to corrections in SQL queries and natural language queries.
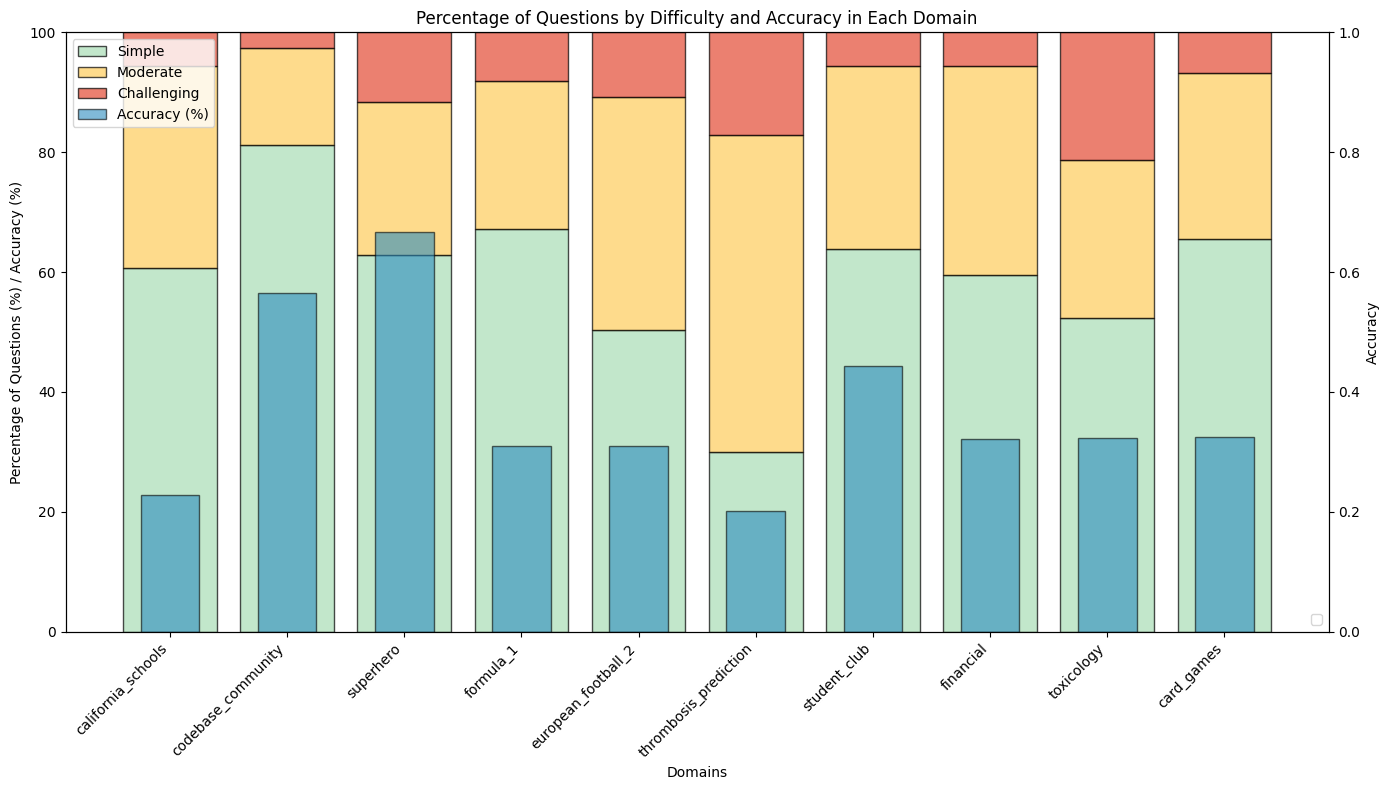
Figure 3: Distribution of question difficulties and execution accuracy of the DIN-SQL model on various domains of the BIRD-Bench development set.
The paper highlights that correcting SQL queries alone drastically alters model rankings, with zero-shot GPT-3.5 outperforming advanced prompting methods like DIN-SQL and MAC-SQL. Models tested on datasets with fully corrected queries revealed that zero-shot GPT-4 achieves the best performance, suggesting noise has a considerable impact on model accuracy. Hence, accurate model evaluations require meticulously cleaned datasets, which could guide improvements in Text-to-SQL methodologies.
Conclusions and Future Work
The study outlines crucial considerations for designing reliable Text-to-SQL benchmarks that can inform researchers about model capabilities in handling noise. It suggests annotating and labeling noise types to facilitate improvements in model robustness. Future research could explore the automatic classification and correction of noise using LLMs, enhancing Text-to-SQL systems' reliability in practical applications.
This investigation underscores the complexities of real-world language data in benchmarking and advocates for comprehensive validation processes in dataset design, impacting subsequent model developments. Reliable benchmarks are critical in the quest for effective AI systems capable of handling the nuances of natural language input in database environments.
In this context, ongoing evaluation and redesign of benchmarks like BIRD-Bench are essential for accelerating advancements in Text-to-SQL model accuracy and reliability.
