- The paper introduces WKVQuant, a PTQ framework that quantizes both weights and the Key/Value cache to maintain accuracy while reducing memory usage.
- It employs Past Only Quantization, two-dimensional quantization, and cross-block reconstruction regularization to effectively minimize quantization errors.
- Experiments on LLaMA models reveal minimal increases in perplexity, confirming the method's balance between memory efficiency and performance.
WKVQuant: Quantizing Weight and Key/Value Cache for LLMs Gains More
Introduction
The paper "WKVQuant: Quantizing Weight and Key/Value Cache for LLMs Gains More" addresses the challenge of deploying LLMs by focusing on efficient quantization techniques. LLMs like GPT and LLaMA have demonstrated exceptional performance in natural language processing tasks; however, their large memory and computational requirements make deployment difficult. The paper proposes a new quantization framework, WKVQuant, designed specifically for quantizing both weights and Key/Value (KV) caches in LLMs, overcoming the limitations of existing methods that either focus solely on weights or include activations at the cost of accuracy.
Quantization Challenges in LLMs
LLMs consist of massive model weights and utilize a KV cache to store intermediate activations for auto-regressive generation. Quantization, which reduces memory usage by converting parameters into low-bit integers, is a common approach to address the memory demand. Existing methods include weight-only quantization, which preserves accuracy but fails to sufficiently reduce memory, and weight-activation quantization, which impacts accuracy due to quantizing both weights and activations. The latter includes crucial activations like the KV cache, but introduces more quantization error which significantly degrades performance.
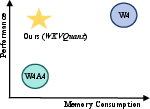
Figure 1: Memory-Performance curve.
WKVQuant Framework
The WKVQuant framework is a Post-Training Quantization (PTQ) method targeting the quantization of weights and the KV cache alone. This smaller focus allows the framework to retain higher accuracy compared to methods that attempt to quantize all activations, including temporary ones. WKVQuant introduces three key techniques:
- Past Only Quantization (POQ): POQ quantizes only the past KV cache during decoding, while maintaining the current KV in full precision, thus improving the accuracy of attention computations.
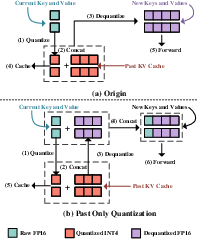
Figure 2: Comparison between original quantization method and Past Only Quantization (POQ) for KV cache.
- Two-dimensional Quantization: This strategy employs static channel smoothing and dynamic token-wise quantization to handle distributional variance within the KV cache, thereby reducing quantization errors effectively.
- Cross-block Reconstruction Regularization (CRR): CRR optimizes quantization parameters by evaluating the impact of quantization across blocks, using Mean Absolute Error (MAE) instead of Mean Squared Error (MSE) to minimize bias from outliers.
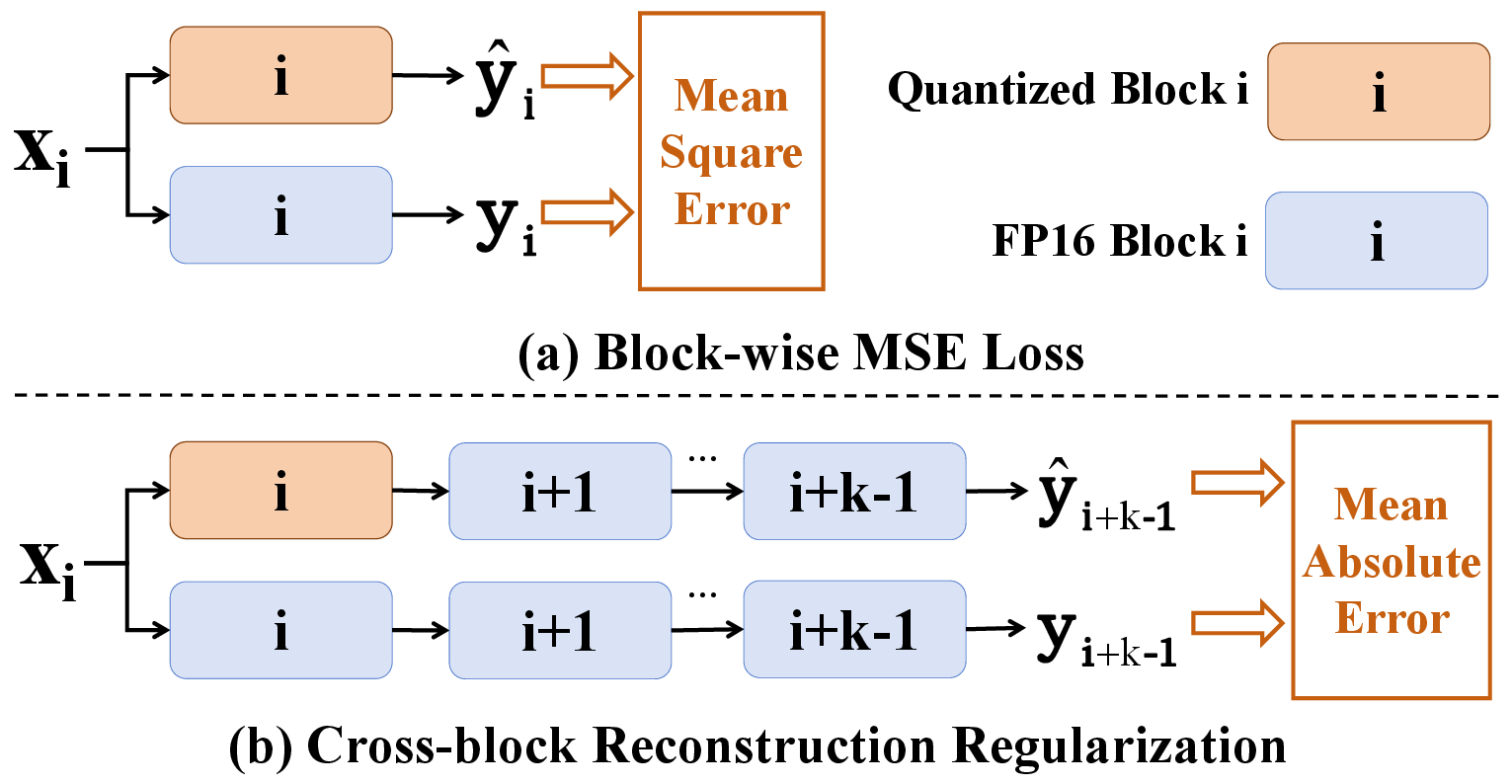
Figure 3: Comparison between Block-wise Mean Square Error (MSE) loss and CRR.
Experimental Evaluation
Experiments on the LLaMA and LLaMA-2 models demonstrated that WKVQuant achieves memory savings comparable to full weight-activation quantization while preserving accuracy close to weight-only quantization. Specifically, the WKVQuant method shows minimal performance drops in terms of perplexity on datasets like WikiText2 and PTB when compared to existing techniques, proving it as an efficient alternative for model deployment under memory constraints.
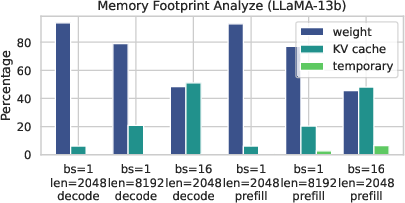
Figure 4: The memory usage proportions of weight, KV cache, and temporary storage on LLaMA-2-13b.
Conclusion
WKVQuant provides a valuable trade-off between accuracy and memory efficiency, achieved by focusing on the quantization of model weights and KV cache without involving temporary activations. This approach not only facilitates the deployment of LLMs on resource-constrained hardware but also ensures minimal performance degradation, making it a promising strategy for efficiently managing the memory footprint of large models. Future work could explore the integration of more sophisticated quantization techniques within this framework to further enhance its applicability across various LLM architectures.

