- The paper presents its main contribution by benchmarking LLM-based embeddings against classical models using cosine similarity and analogy tests.
- It demonstrates that LLMs like ADA and PaLM achieve superior semantic clustering and word-pair similarity compared to traditional methods.
- It reveals that SBERT, while resource-efficient, maintains notable agreement with LLMs, highlighting its potential in constrained environments.
Revisiting Word Embeddings in the LLM Era
Introduction
The paper "Revisiting Word Embeddings in the LLM Era" (2402.11094) investigates the efficacy of LLMs as word embedding models, particularly in comparison to classical methods like SBERT and USE. The study critically examines whether the enhanced performance of LLMs is primarily due to their scale or if they inherently produce distinct embeddings. The authors focus on two primary analyses: word-pair similarity and word analogy tasks, using metrics such as cosine similarity to explore embeddings' latent semantic spaces.
Word-Pair Similarity Analysis
One of the principal investigations in the paper revolves around analyzing how LLM-based embeddings contrast with classical ones in terms of word-pair cosine similarity. Using a corpus of approximately 80,000 distinct words from WordNet, the authors compute the cosine similarity of every word pair across different models, totaling around 6.4 billion pairs.
The results, depicted in (Figure 1), demonstrate that LLM-based embeddings, particularly ADA and LLaMA, exhibit higher expected cosine similarity for random word pairs than classical models. This finding underscores significant differences in the latent semantic spacing among models, as LLMs evidently cluster semantically related words more tightly.
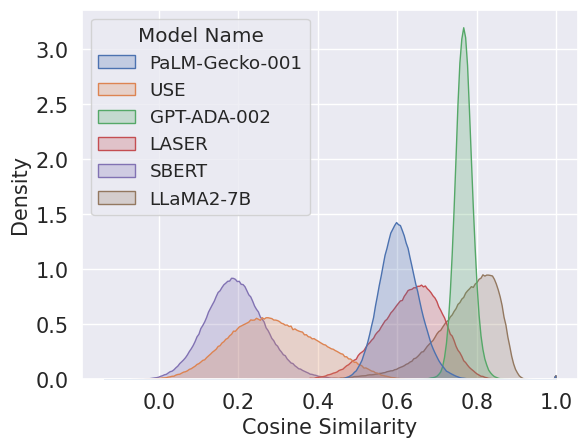
Figure 1: The distribution of cosine similarities between all pairs of words for each model.
Further, the study utilizes the BATS dataset to compare morphologically and semantically related word pairs. Notably, as demonstrated in (Figure 2), ADA, PaLM, and SBERT distinctly separate related pairs from unrelated ones better than other models, highlighting their superior semantic similarity capture.
Figure 2: Histogram showing the distribution of cosine similarities for random, morphologically related, and semantically related pairs of words for each model.
Word Analogy Task Analysis
The paper expands its exploration to the word analogy task, traditionally performed on classical models. It evaluates LLMs using the BATS dataset under several analogy-solving metrics, including 3CosAdd and LRCos, among others.
The results reveal that ADA and PaLM perform significantly better than classical embeddings, as illustrated in the report. Interestingly, SBERT, despite being a classical model, is often ranked as the third-best performer, hinting at its potential as a resource-efficient alternative. These results are encapsulated in (Figure 3), which reflects the ranking discrepancies among various embeddings for certain BATS categories.
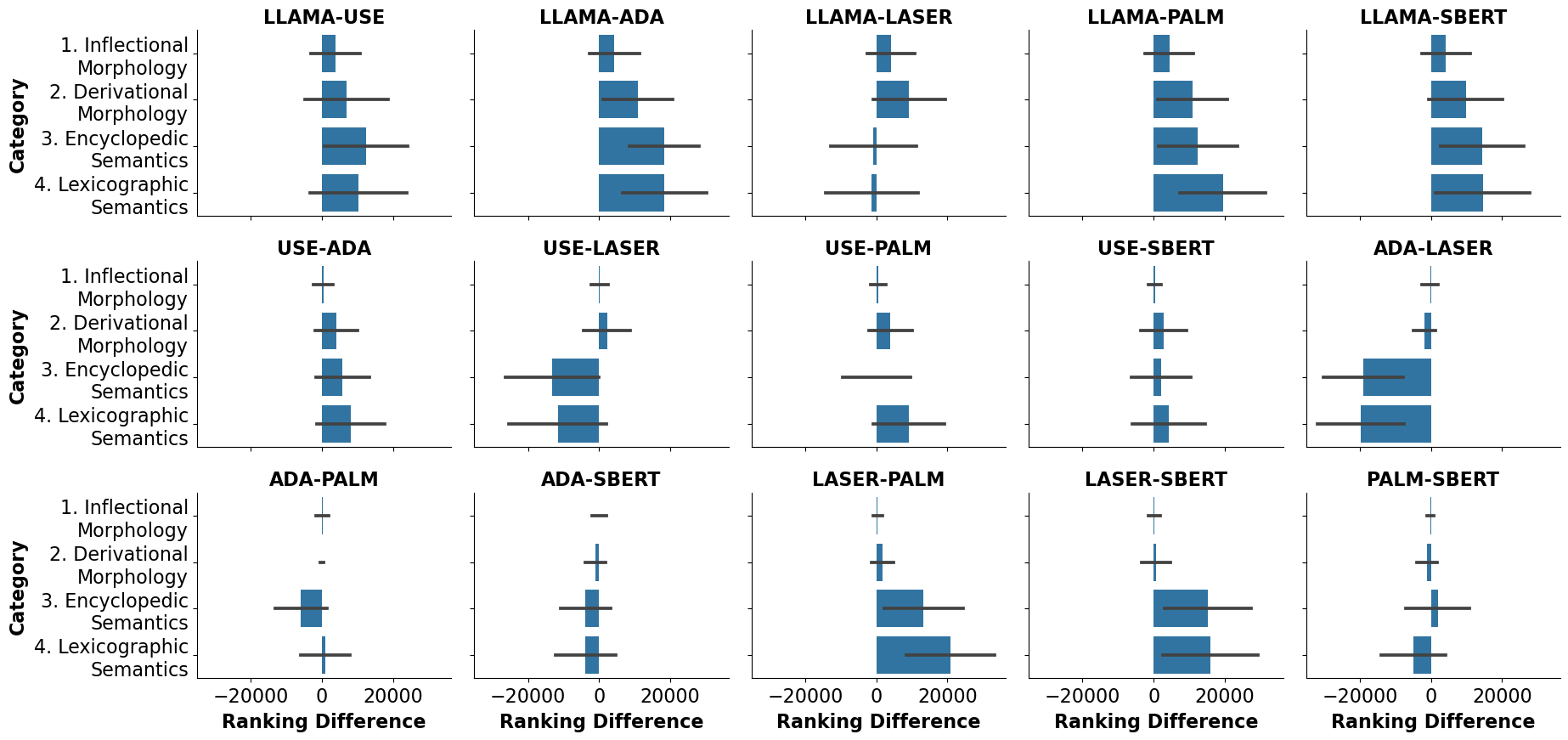
Figure 3: For each model, the cosine similarity of related words was found and ranked according to all pairs of words. Here, the difference in ranking between model pairs for certain BATS categories is shown.
Correlation and Agreement Among Models
The study further scrutinizes the degree of agreement among different embedding models regarding word pair similarities. The results, portrayed in (Figure 4), indicate that only ADA and PaLM, both LLMs, consistently align in their semantic assessments. Surprisingly, SBERT also shows a notable degree of agreement with these heavy LLMs, demonstrating its versatility and robustness despite being a lighter model.
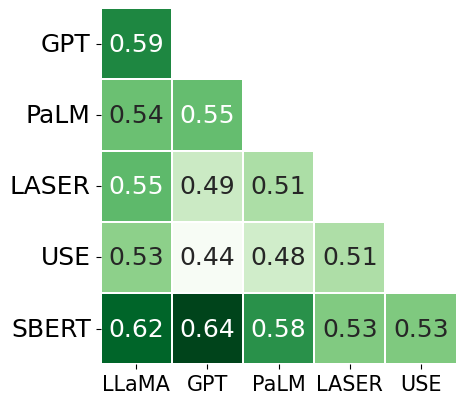
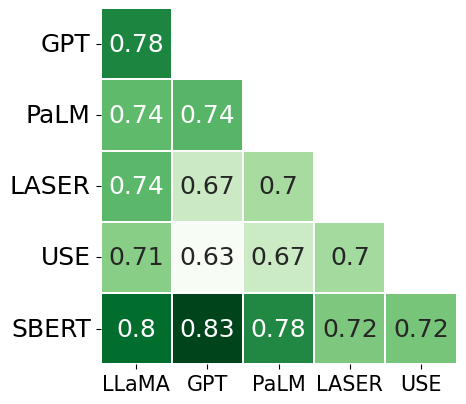
Figure 4: Kendal tau correlation coefficients for each pair of models, found using a large dataset of pairs of words.
Conclusion
The comprehensive investigation in this study establishes that LLM-based word embeddings generally offer significant enhancements in semantic clustering and analogy task performance compared to classical models. ADA and PaLM, in particular, demonstrate strong capabilities in these areas. However, the findings also suggest that SBERT, a classical model, holds its ground well, proposing itself as a viable option for resource-constrained environments due to its agreement with more resource-intensive LLMs. These insights pave the way for future explorations that aim to elucidate the nuanced distinctions and potential integrations of classical and LLM-based word embeddings in NLP applications.