The Evolution of Statistical Induction Heads: In-Context Learning Markov Chains
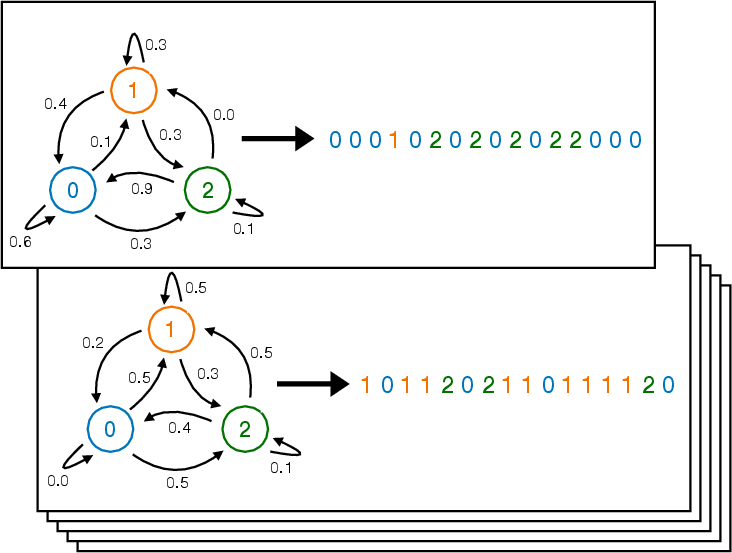
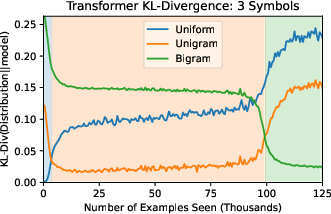
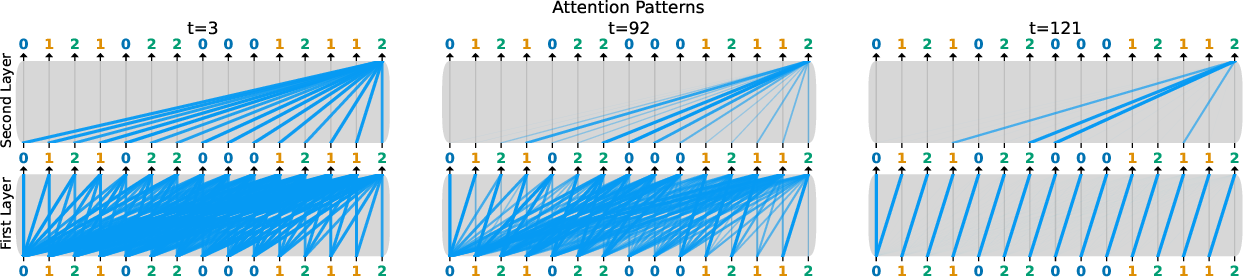
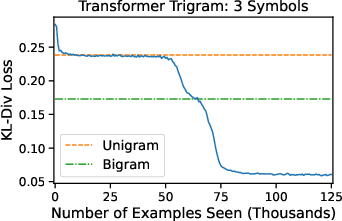
Abstract: LLMs have the ability to generate text that mimics patterns in their inputs. We introduce a simple Markov Chain sequence modeling task in order to study how this in-context learning (ICL) capability emerges. In our setting, each example is sampled from a Markov chain drawn from a prior distribution over Markov chains. Transformers trained on this task form \emph{statistical induction heads} which compute accurate next-token probabilities given the bigram statistics of the context. During the course of training, models pass through multiple phases: after an initial stage in which predictions are uniform, they learn to sub-optimally predict using in-context single-token statistics (unigrams); then, there is a rapid phase transition to the correct in-context bigram solution. We conduct an empirical and theoretical investigation of this multi-phase process, showing how successful learning results from the interaction between the transformer's layers, and uncovering evidence that the presence of the simpler unigram solution may delay formation of the final bigram solution. We examine how learning is affected by varying the prior distribution over Markov chains, and consider the generalization of our in-context learning of Markov chains (ICL-MC) task to $n$-grams for $n > 2$.
- Sgd learning on neural networks: leap complexity and saddle-to-saddle dynamics. In The Thirty Sixth Annual Conference on Learning Theory, pages 2552–2623. PMLR.
- A mechanism for sample-efficient in-context learning for sparse retrieval tasks. CoRR, abs/2305.17040.
- What learning algorithm is in-context learning? investigations with linear models. arXiv preprint arXiv:2211.15661.
- In-context language learning: Architectures and algorithms. CoRR, abs/2401.12973.
- A closer look at memorization in deep networks. In International conference on machine learning, pages 233–242. PMLR.
- High-dimensional asymptotics of feature learning: How one gradient step improves the representation. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A., editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Hidden progress in deep learning: Sgd learns parities near the computational limit. Advances in Neural Information Processing Systems, 35:21750–21764.
- Curriculum learning. In Danyluk, A. P., Bottou, L., and Littman, M. L., editors, Proceedings of the 26th Annual International Conference on Machine Learning, ICML 2009, Montreal, Quebec, Canada, June 14-18, 2009, volume 382 of ACM International Conference Proceeding Series, pages 41–48. ACM.
- Birth of a transformer: A memory viewpoint.
- Circular law theorem for random markov matrices. Probability Theory and Related Fields, 152.
- Class-based n-gram models of natural language. Comput. Linguist., 18(4):467–479.
- Language models are few-shot learners. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H., editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Data distributional properties drive emergent in-context learning in transformers. Advances in Neural Information Processing Systems, 35:18878–18891.
- Sudden drops in the loss: Syntax acquisition, phase transitions, and simplicity bias in mlms.
- Chomsky, N. (1956). Three models for the description of language. IRE Transactions on information theory, 2(3):113–124.
- Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers. arXiv preprint arXiv:2212.10559.
- A survey for in-context learning. arXiv preprint arXiv:2301.00234.
- A mathematical framework for transformer circuits. Transformer Circuits Thread, 1.
- What can transformers learn in-context? A case study of simple function classes. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A., editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- How do transformers learn in-context beyond simple functions? a case study on learning with representations. arXiv preprint arXiv:2310.10616.
- In-context learning creates task vectors. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9318–9333.
- The developmental landscape of in-context learning. CoRR, abs/2402.02364.
- Neural tangent kernel: Convergence and generalization in neural networks. In Bengio, S., Wallach, H. M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R., editors, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pages 8580–8589.
- Sgd on neural networks learns functions of increasing complexity. Advances in neural information processing systems, 32.
- Karpathy, A. (2023). Mingpt. https://github.com/karpathy/minGPT/tree/master.
- General-purpose in-context learning by meta-learning transformers. CoRR, abs/2212.04458.
- Grokking as the transition from lazy to rich training dynamics. CoRR, abs/2310.06110.
- Transformers as algorithms: Generalization and stability in in-context learning. In International Conference on Machine Learning, pages 19565–19594. PMLR.
- Dichotomy of early and late phase implicit biases can provably induce grokking. CoRR, abs/2311.18817.
- Attention with markov: A framework for principled analysis of transformers via markov chains. CoRR, abs/2402.04161.
- A tale of two circuits: Grokking as competition of sparse and dense subnetworks. CoRR, abs/2303.11873.
- In-context learning and induction heads. Transformer Circuits Thread. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html.
- Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177.
- Reddy, G. (2023). The mechanistic basis of data dependence and abrupt learning in an in-context classification task.
- Are emergent abilities of large language models a mirage? CoRR, abs/2304.15004.
- The pitfalls of simplicity bias in neural networks. Advances in Neural Information Processing Systems, 33:9573–9585.
- Shannon, C. E. (1948). A mathematical theory of communication. The Bell system technical journal, 27(3):379–423.
- Self-attention with relative position representations. In Walker, M. A., Ji, H., and Stent, A., editors, Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 2 (Short Papers), pages 464–468. Association for Computational Linguistics.
- Deep learning generalizes because the parameter-function map is biased towards simple functions. arXiv preprint arXiv:1805.08522.
- Attention is all you need. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R., editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008.
- Transformers learn in-context by gradient descent. In International Conference on Machine Learning, pages 35151–35174. PMLR.
- How many pretraining tasks are needed for in-context learning of linear regression? arXiv preprint arXiv:2310.08391.
- An explanation of in-context learning as implicit bayesian inference. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.