GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements
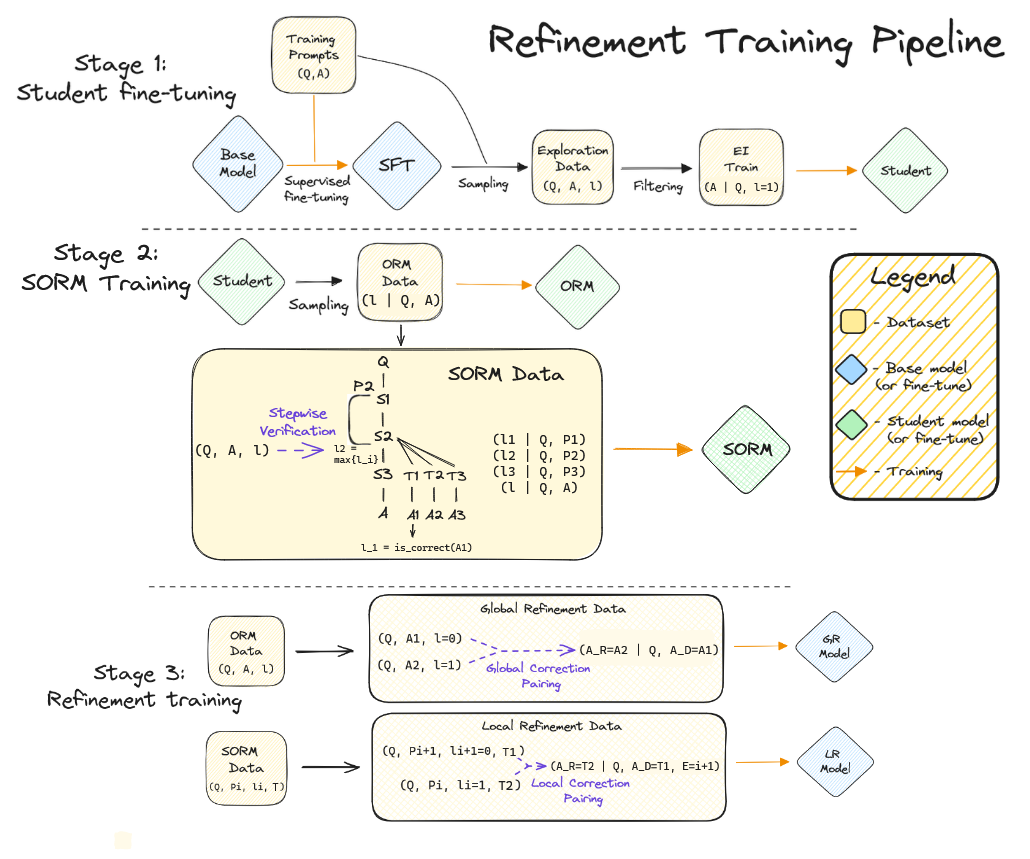
Abstract: State-of-the-art LLMs can exhibit impressive reasoning refinement capabilities on math, science or coding tasks. However, recent work demonstrates that even the best models struggle to identify \textit{when and where to refine} without access to external feedback. Outcome-based Reward Models (\textbf{ORMs}), trained to predict correctness of the final answer indicating when to refine, offer one convenient solution for deciding when to refine. Process Based Reward Models (\textbf{PRMs}), trained to predict correctness of intermediate steps, can then be used to indicate where to refine. But they are expensive to train, requiring extensive human annotations. In this paper, we propose Stepwise ORMs (\textbf{SORMs}) which are trained, only on synthetic data, to approximate the expected future reward of the optimal policy or $V{\star}$. More specifically, SORMs are trained to predict the correctness of the final answer when sampling the current policy many times (rather than only once as in the case of ORMs). Our experiments show that SORMs can more accurately detect incorrect reasoning steps compared to ORMs, thus improving downstream accuracy when doing refinements. We then train \textit{global} refinement models, which take only the question and a draft solution as input and predict a corrected solution, and \textit{local} refinement models which also take as input a critique indicating the location of the first reasoning error. We generate training data for both models synthetically by reusing data used to train the SORM. We find combining global and local refinements, using the ORM as a reranker, significantly outperforms either one individually, as well as a best of three sample baseline. With this strategy we can improve the accuracy of a LLaMA-2 13B model (already fine-tuned with RL) on GSM8K from 53\% to 65\% when greedily sampled.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.