- The paper introduces a principled framework adapting precision and recall from image generation to assess quality and diversity in LLM outputs.
- It employs pre-trained embeddings, PCA, and k-NN support estimation to measure quality (precision) and diversity (recall) in generated text.
- Empirical results reveal trade-offs in instruction-tuned models, offering actionable insights for balancing sample quality and diversity.
Precision and Recall for Evaluating Quality and Diversity in LLMs
The paper "Exploring Precision and Recall to assess the quality and diversity of LLMs" (2402.10693) introduces a principled framework for evaluating LLMs by adapting the concepts of Precision and Recall from image generation to text generation. This approach enables a nuanced, distribution-based assessment of both the quality and diversity of generated text, addressing limitations of traditional sample-based and reference-based evaluation metrics. The authors provide empirical evidence that these metrics reveal critical trade-offs in LLM behavior, particularly under instruction tuning and human feedback alignment.
Motivation and Background
Traditional evaluation of LLMs has relied on metrics such as BLEU, ROUGE, and BERTScore, which require aligned reference corpora and are limited in open-ended generation settings. Perplexity, while widely used, is a token-level metric and fails to capture semantic diversity or global distributional properties. Recent distribution-based metrics, such as MAUVE, attempt to quantify the divergence between the empirical distribution of human-written texts and model outputs, but collapse quality and diversity into a single scalar, obscuring the underlying trade-offs.
The adaptation of Precision and Recall from the image generation literature (notably [sajjadi_assessing_2018], [kynkaanniemi_improved_2019]) provides a two-dimensional evaluation: Precision measures the proportion of generated samples that are close to the reference distribution (quality), while Recall measures the proportion of the reference distribution covered by the model outputs (diversity). This separation is critical for diagnosing model behavior, especially in the context of instruction tuning and alignment, where improvements in quality may come at the expense of diversity.
The authors adopt the support-based definitions of Precision and Recall:
- Precision: Q(Supp(P)) — the probability mass of the model distribution Q that falls within the support of the reference distribution P.
- Recall: P(Supp(Q)) — the probability mass of the reference distribution P that is covered by the support of Q.
In practice, the support of high-dimensional text distributions is estimated by projecting samples into a latent space using a pre-trained model (e.g., GPT-2 LARGE embeddings), followed by dimensionality reduction (PCA) and k-nearest neighbor (k-NN) support estimation. The pipeline is as follows:
- Sampling: Draw N samples from both the reference and model distributions.
- Embedding: Project samples into a latent space via a pre-trained model.
- Dimensionality Reduction: Apply PCA to retain 90% of the variance.
- Support Estimation: For each sample, define a ball of radius equal to the distance to its k-th nearest neighbor; the union of these balls forms the estimated support.
- Metric Computation: Precision is the fraction of model samples within the reference support; Recall is the fraction of reference samples within the model support.
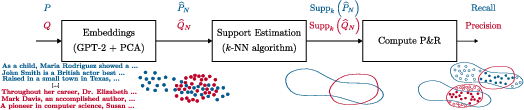
Figure 1: The pipeline for computing Precision and Recall: text samples are embedded, reduced in dimension, and support is estimated via k-NN.
Empirical analysis shows that N=3000–$4000$ samples and k=4 provide stable estimates, with metrics plateauing as N increases.
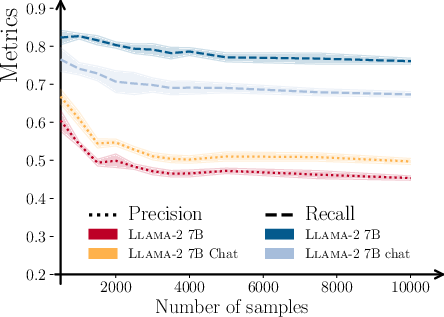
Figure 2: Precision and Recall stabilize as the number of samples increases, indicating robustness of the estimation procedure.
Empirical Findings
Disentangling Quality and Diversity
The authors demonstrate, using controlled topic modeling experiments, that MAUVE fails to distinguish between lack of diversity and lack of quality, whereas Precision and Recall provide clear diagnostic power.
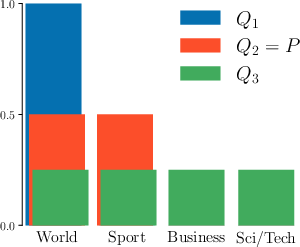
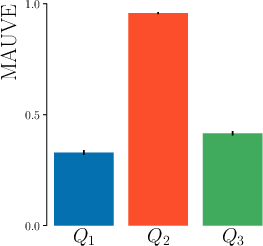
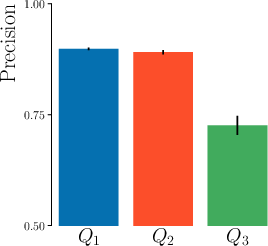
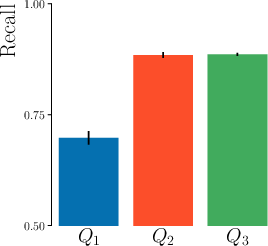
Figure 3: Precision and Recall differentiate between models lacking diversity (Q1) and those generating off-distribution content (Q3), where MAUVE cannot.
LLM Evaluation: Pre-trained vs. Instruction-Tuned
A comprehensive evaluation of Llama-2, Mistral, Vicuna, and Pythia models reveals that instruction-tuned (chat) models consistently achieve higher Precision but lower Recall compared to their pre-trained counterparts. This indicates that alignment and instruction tuning improve sample quality but reduce output diversity.
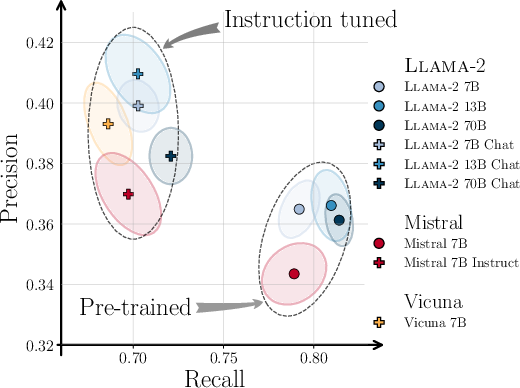
Figure 4: Precision and Recall for various models on WebText; instruction-tuned models cluster at higher Precision and lower Recall.
Larger models exhibit higher Recall, suggesting that model capacity is positively correlated with generative diversity.
In-Context Learning and Prompt Diversity
In the Wikipedia biography generation task, increasing the number of in-context examples leads to higher Precision for both pre-trained and instruction-tuned models. Notably, Recall for chat models increases with more in-context examples, indicating that prompt diversity can partially mitigate the diversity loss induced by instruction tuning.
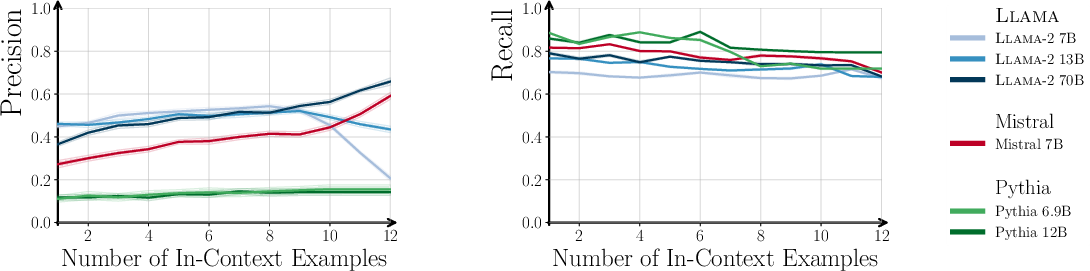
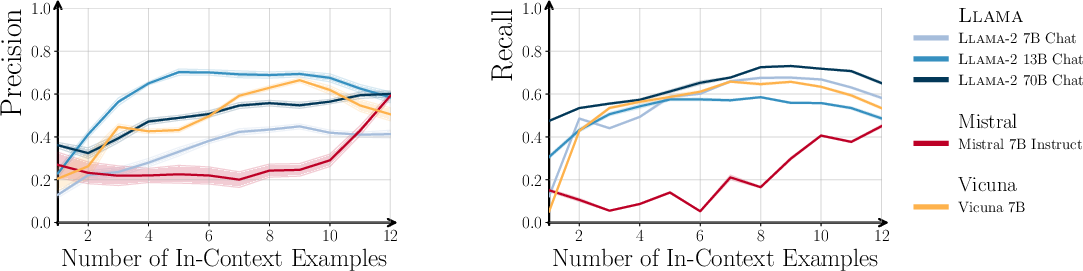
Figure 5: Precision and Recall as a function of in-context examples; chat models recover diversity with more diverse prompts.
Correlation with Other Metrics
Precision correlates with MAUVE but not with diversity metrics such as Self-BLEU or Distinct-N, while Recall correlates with these diversity metrics, confirming the intended semantic separation.
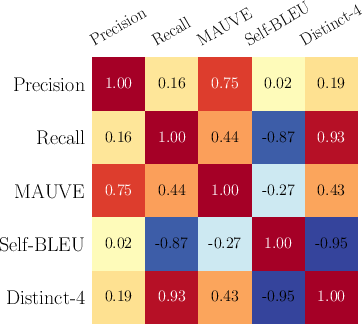
Figure 6: Correlation between Precision, Recall, and other distribution-based metrics for Wikipedia biography generation.
Comparative Analysis and Trade-offs
The explicit trade-off between Precision and Recall is visualized in the Precision-Recall plane, enabling fine-grained model comparison. For instance, models with high Precision but low Recall are high-quality but mode-seeking, while those with high Recall but low Precision are diverse but less human-like.
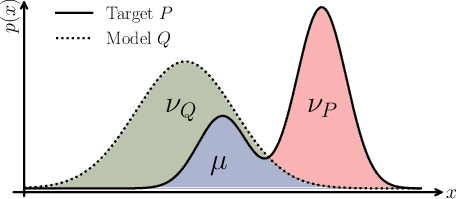
Figure 7: Illustration of the Precision-Recall trade-off, highlighting the spectrum from high-quality/low-diversity to high-diversity/low-quality models.
PR-curves provide a more granular view than scalar metrics like MAUVE, supporting detailed analysis of model behavior across different tasks and settings.
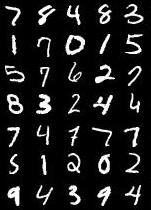


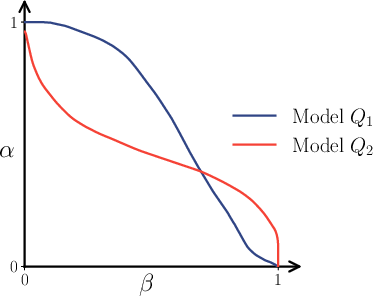
Figure 8: PR-curves for MNIST; Q1 (high quality, low diversity) and Q2 (low quality, high diversity) are clearly distinguished.
Practical Implications and Limitations
The proposed framework enables:
- Reference-free evaluation: No need for aligned corpora; applicable to open-ended generation.
- Model selection and diagnosis: Facilitates targeted improvements (e.g., boosting diversity without sacrificing quality).
- Comparative analysis: Supports direct comparison between models, including across families and sizes.
However, the approach is sensitive to the choice of embedding model and support estimation parameters. Outlier sensitivity and domain generalizability remain open challenges, as do potential biases inherited from the reference dataset. The authors recommend group-wise computation of metrics to audit fairness and representation.
Future Directions
- Robust support estimation: Incorporation of topological or statistical robustness (e.g., TopP-R [kim_toppr_2023]) to mitigate outlier effects.
- Embedding model selection: Systematic study of the impact of different embedding spaces on metric reliability.
- Task-specific adaptation: Extension to multilingual and domain-specific LLMs.
- Integration with training objectives: Direct optimization of Precision/Recall trade-offs during model training, as explored in recent GAN and flow literature.
Conclusion
This work establishes Precision and Recall as essential, interpretable metrics for evaluating LLMs in open-ended generation. By decoupling quality and diversity, the framework provides actionable insights into model behavior, exposes trade-offs induced by alignment and scaling, and sets a foundation for more rigorous, distribution-based evaluation protocols in NLP.